프록시 서버
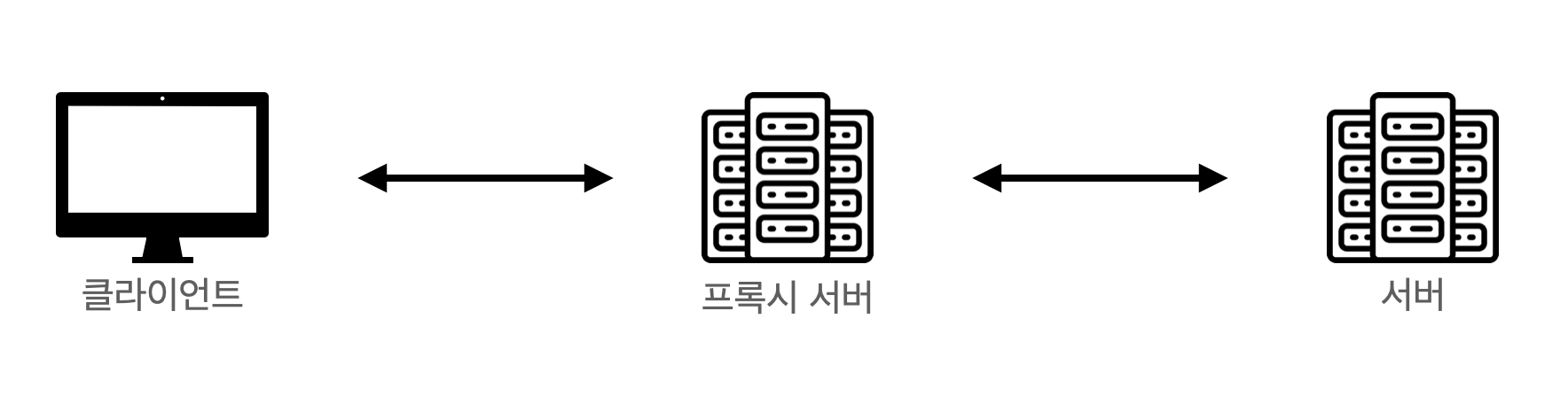
클라이언트가 서버와 소통할 때, 서버에 바로 접근하지 않고 자신을 통해 서버에 접근할 수 있도록 해주는 일종의 대리 서버입니다.
보통 일반 사용자는 지역이 제한되어 있는 서비스를 이용하기 위해 우회하거나, 캐시를 통해 더 빠른 이용을 하기 위해 프록시 서버를 사용합니다. 이외에도 여러 장점들이 있습니다.
프록시 서버의 종류
프록시 서버가 클라이언트에 가까이 있는지, 서버에 가까이 있는지에 따라 Forward Proxy, Reverse Proxy 두 가지로 나뉩니다.
1. Forward Proxy
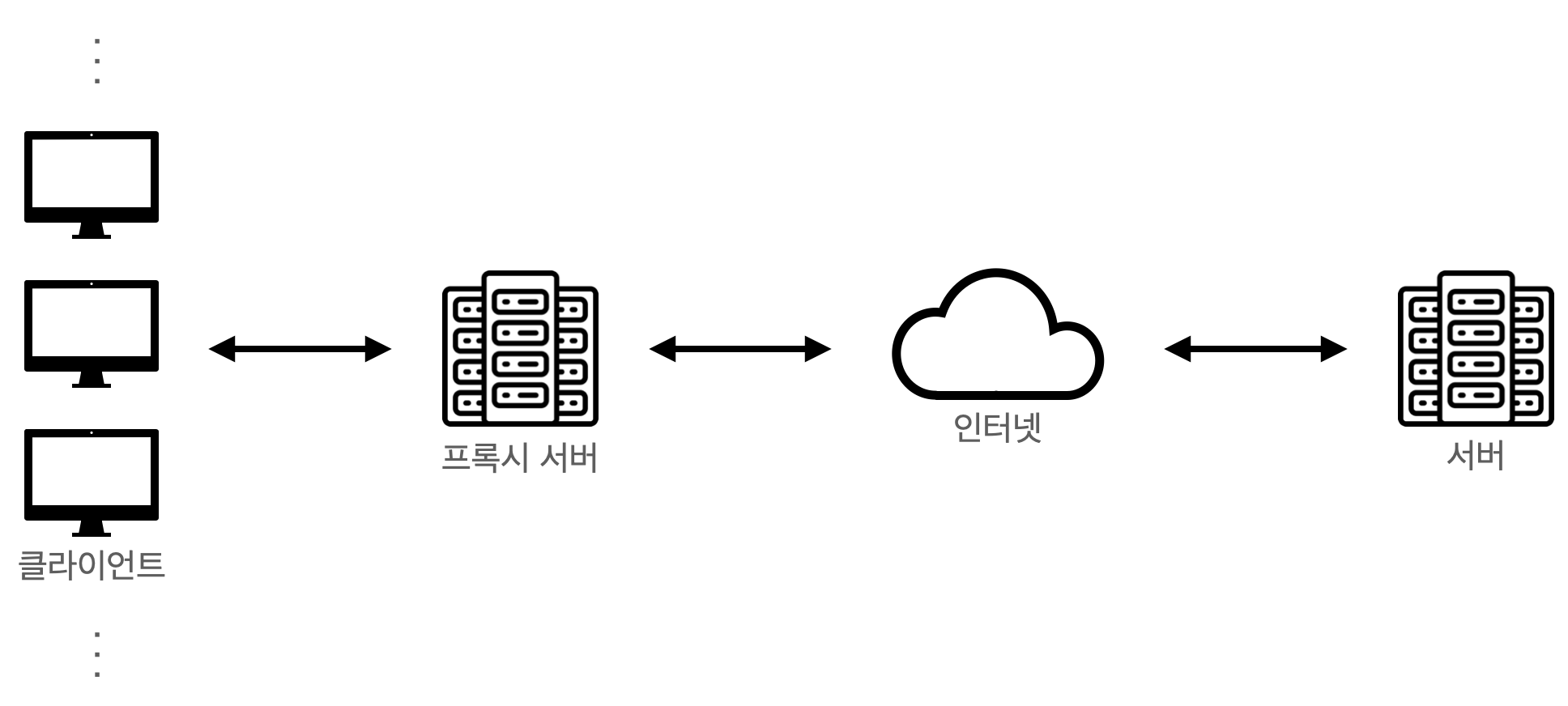
위 그림과 같이 클라이언트 가까이에 위치한 프록시 서버로 클라이언트를 대신에 서버에 요청을 전달합니다.
주로 캐싱을 제공하는 경우가 많아 사용자가 빠른 서비스를 이용할 수 있도록 도와줍니다.
- 캐싱을 통해 빠른 서비스 이용 가능
클라이언트는 서비스의 서버가 아닌 프록시 서버와 소통하게 됩니다. 그러한 과정에서 여러 클라이언트가 동일한 요청을 보내는 경우 첫 응답을 하며 결과 데이터를 캐시에 저장해 놓고, 이후 서버에 재 요청을 보내지 않아도 다른 클라이언트에게 빠르게 전달할 수 있습니다. - 보안
클라이언트에서 프록시 서버를 거친 후 서버에 요청이 도착하기 때문에, 서버에서 클라이언트의 IP 추적이 필요한 경우 클라이언트의 IP가 아닌 프록시 서버의 IP가 전달됩니다. 서버가 응답받은 IP는 프록시 서버의 IP이기 때문에 서버에게 클라이언트를 숨길 수 있습니다.
2. Reverse Proxy
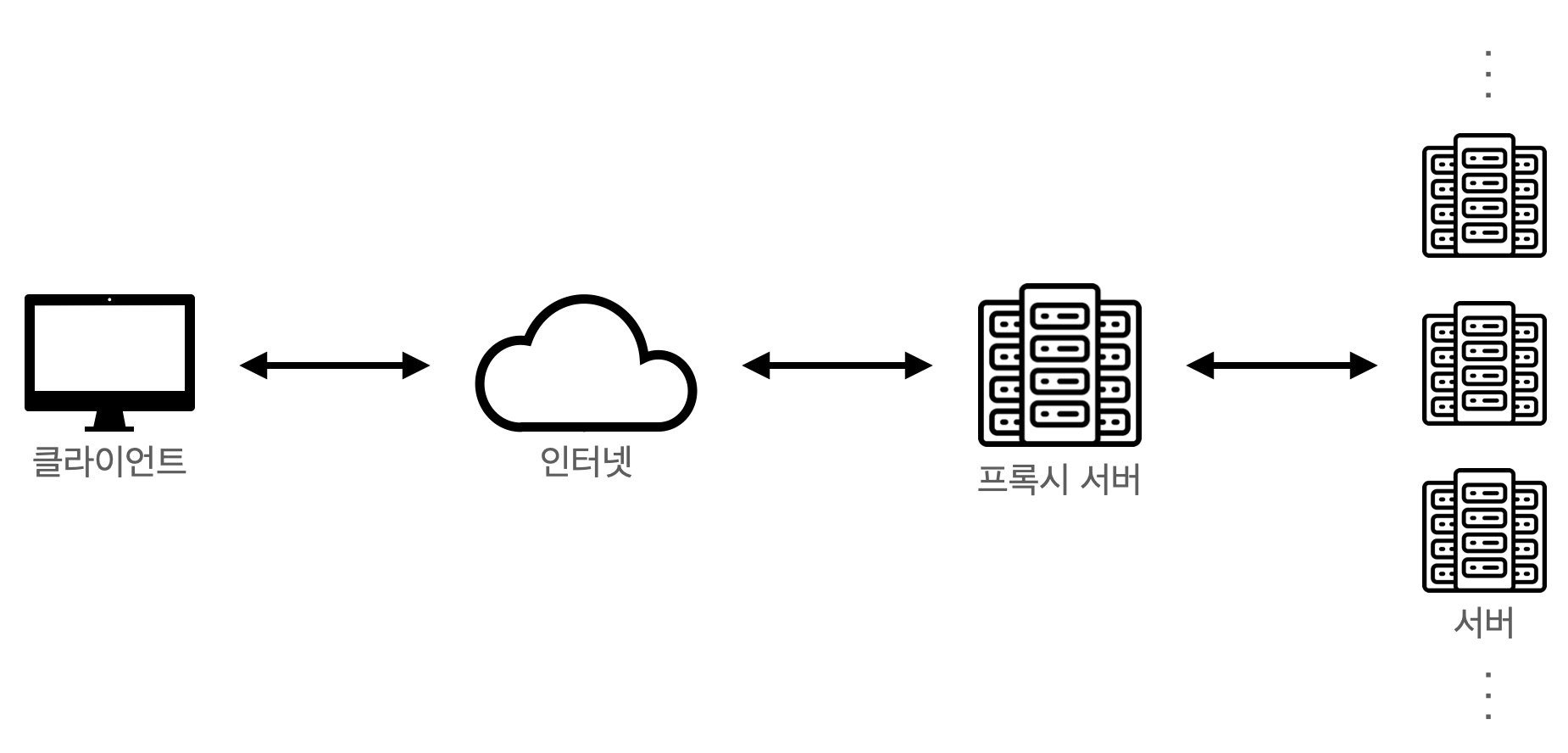
Reverse Proxy는 반대로 서버 가까이에 위치한 프록시 서버로 서버를 대신해서 클라이언트에 응답을 제공합니다. 분산처리를 목적으로 하거나 보안을 위해 프록시 서버를 이용합니다. Reverse Proxy를 사용함으로 인해 얻을 수 있는 장점으로는 다음과 같습니다.
- 분산처리
클라이언트 - 서버 구조에서 사용자가 많아져 서버에 과부하가 올 경우를 위해 부하를 분산할 수 있습니다. Reverse Proxy 구조에서 프록시 서버로 요청이 들어오면 여러 대의 서버로 요청을 나누어 전달 후 처리합니다. - 보안
Forward Proxy와 반대로 Reverse Proxy는 클라이언트에게 서버를 숨길 수 있습니다. 클라이언트 입장에서의 요청 보내는 서버가 프록시 서버가 되므로 실제 서버의 IP주소가 노출되지 않습니다.
로드밸런서
사용자의 많은 요청으로 서버에 과부화가 와 서버가 원활한 서비스를 제공하지 못하는 경우를 해결하기 위해 크게 서버의 하드웨어를 업그레이드하는 방법과 서버의 개수를 늘리는 방법, 두 가지를 선택할 수 있습니다.
1. Scale-Up
Scale-Up은 물리적으로 서버의 사양을 높이는 하드웨어적인 방법입니다. 서버의 수를 늘리지 않고 프로그램 구현에 있어 변화가 필요 없다는 장점이 있습니다. 하지만 서버의 사양을 높이는 데엔 굉장히 높은 비용이 들고, 하드웨어의 업그레이드에 한계가 있다는 큰 단점이 있습니다. 또한 사양을 늘린 만큼 클라이언트의 요청이 더욱 많아진다면, 서버에 발생하는 부하는 여전히 해결하지 못한 상황이 됩니다.
2. Scale-Out
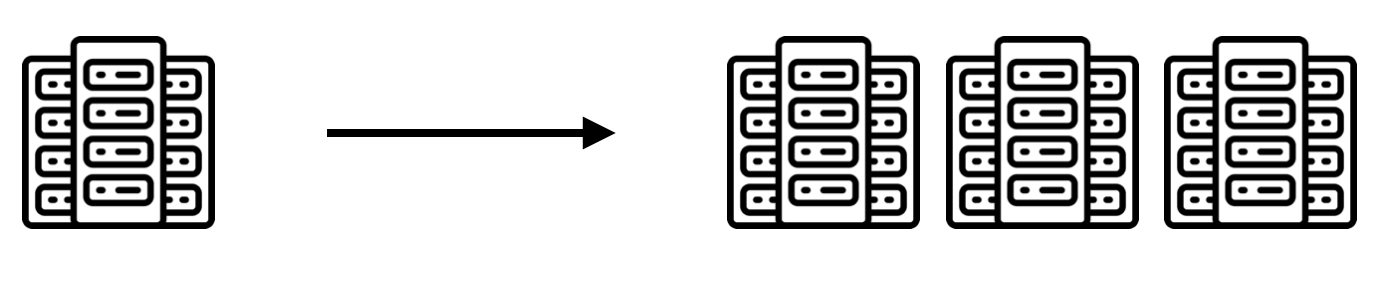
Scale-Out은 서버의 개수를 늘려 하나의 서버에 줄 부하를 분산시키는 방법입니다. 많은 요청이 오더라도 여러 대의 서버가 나눠서 처리를 하기 때문에 서버의 사양을 높이지 않고도 비교적 저렴한 방법으로 부하를 처리할 수 있습니다.
Scale-Out방법으로 여러 대의 서버로 부하를 처리하는 경우, 클라이언트로부터 온 요청을 여러 서버 중 어느 서버에 보내서 처리해야 할까요? 요청을 여러 서버에 나눠 처리할 수 있도록 교통정리를 해줄 역할이 필요합니다. 이 역할을 하는 게 바로 로드 밸런서이고, 여러 서버에 교통정리를 해주는 기술 혹은 프로그램을 로드 밸런싱이라고 부릅니다.
로드 밸런서의 종류
| 로드 밸런서의 종류 | 로드밸런싱의 기준 |
|---|---|
| L2 | 데이터 전송 계층에서 Mac 주소를 바탕으로 로드 밸런싱 합니다. |
| L3 | 네트워크 계층에서 IP 주소를 바탕으로 로드 밸런싱 합니다.전송 계층에서 IP주소와 Port를 바탕으로 로드 밸런싱 합니다. |
| L4 | 전송 계층에서 IP주소와 Port를 바탕으로 로드 밸런싱 합니다. |
| L7 | 응용 계층에서 클라이언트의 요청을 바탕으로 로드 밸런싱 합니다. (예, 엔드포인트) |
오토스케일링
AWS 기반으로 작성
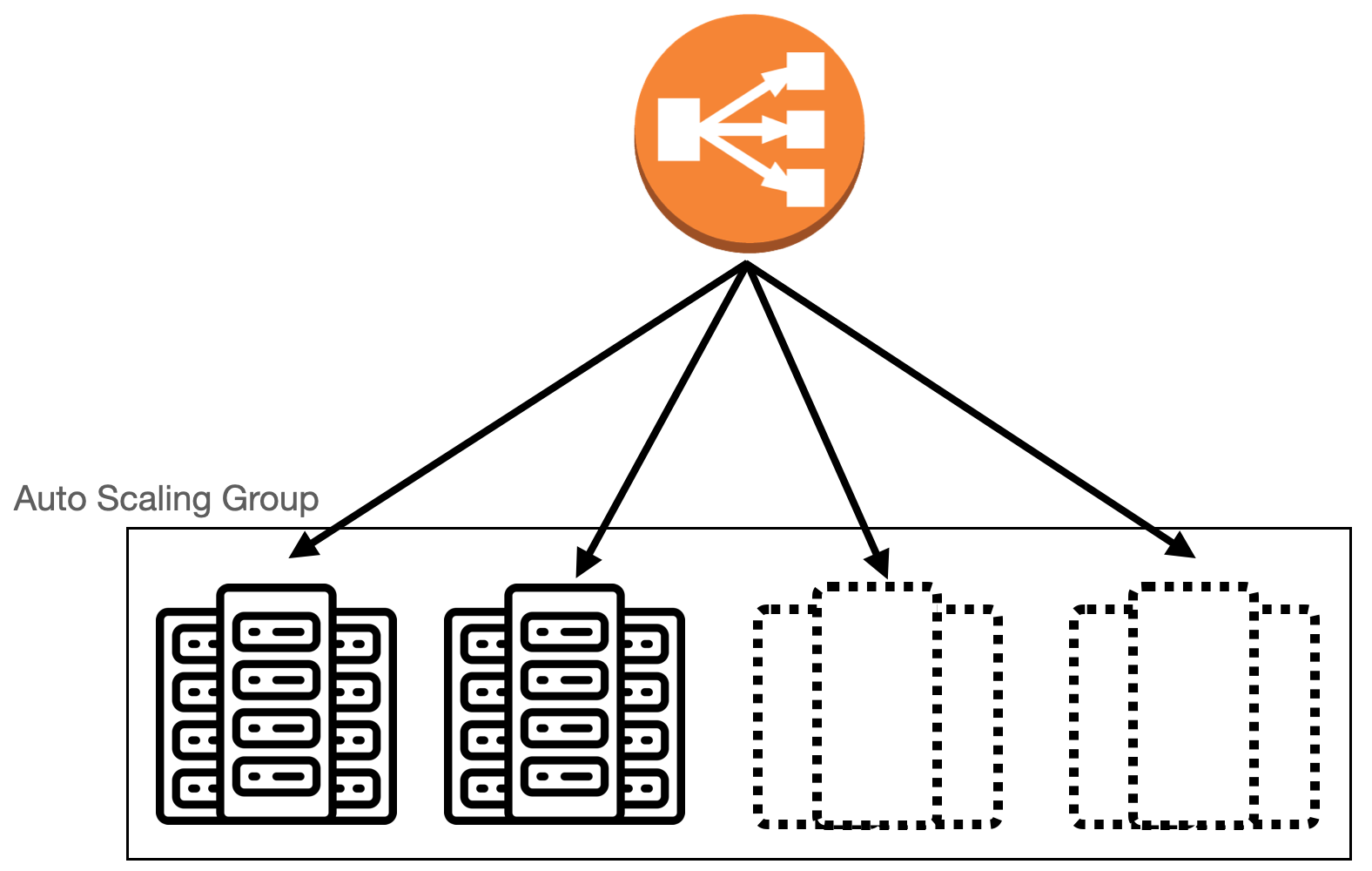
Scale-Out 방식으로 서버를 증설할 때 자동으로 서버(리소스)를 관리해 주는 기능입니다.
클라이언트의 요청이 많아져 서버의 처리 요구량이 증가하면 새 리소스를 자동으로 추가하고 반대로 처리 요구량이 줄어들면 리소스를 감소시켜 적절한 분산 환경을 만들어줍니다.
장점
- 동적 스케일링 : Auto Scaling의 가장 큰 장점은 사용자의 요구 수준에 따라 리소스를 동적으로 스케일링할 수 있다는 점입니다. 스케일 업 할 수 있는 서버의 수에는 제한이 없고, 필요한 경우 서버 두 대에서 수백 ~ 수만 대의 서버로 즉시 스케일 아웃 할 수 있습니다.
- 로드 밸런싱 : Auto Scaling은 리소스를 동적으로 스케일업 혹은 스케일다운 합니다. 로드밸런서와 함께 사용하면, 다수의 EC2 인스턴스에게 워크로드를 효과적으로 분배할 수 있어 사용자가 정의한 규칙에 따라 워크로드를 효과적으로 관리할 수 있습니다.
- 타깃 트래킹 : 사용자는 특정 타깃에 대해서만 Auto Scaling을 할 수 있으며, 사용자가 설정한 타깃에 맞춰 EC2 인스턴스의 수를 조정합니다.
- 헬스 체크와 서버 플릿 관리 : Auto Scaling을 이용하면 EC2 인스턴스의 헬스 체크 상태를 모니터링할 수 있습니다. 헬스 체크를 하는 과정에서 특정 인스턴스의 문제가 감지되면, 자동으로 다른 인스턴스로 교체합니다.
EC2 Auto Scaling 활용
시작 템플릿(Launch Configuration)
Auto Scaling으로 인스턴스를 확장 또는 축소하려면 어떤 서버를 사용할지 결정해야 합니다. 이는 시작 템플릿을 통해서 가능하며, AMI 상세 정보, 인스턴스 타입, 키 페어, 시큐리티 그룹 등 인스턴스에 대한 모든 정보를 담고 있습니다. 만약 시작 템플릿을 사용하고 있지 않고 시작 템플릿을 생성하지 않으려는 경우에는 대신 시작 구성을 생성할 수 있습니다. 시작 구성은 EC2 Auto Scaling이 사용자를 위해 생성하는 EC2 인스턴스 유형을 지정한다는 점에서 시작 템플릿과 비슷합니다. 사용할 AMI의 ID, 인스턴스 유형, 키 페어, 보안 그룹 등의 정보를 포함시켜서 시작 구성을 생성합니다.
Auto Scaling 그룹 생성
Auto Scaling 그룹은 스케일업 및 스케인 다운 규칙의 모음으로 EC2 인스턴스 시작부터 삭제까지의 모든 동작에 대한 규칙과 정책을 담고 있습니다. 따라서 Auto Scaling 그룹을 생성하기 위해서는 스케일링 정책 및 유형에 대해서 잘 숙지하고 있어야 합니다.
Scaling 유형
-
인스턴스 레벨 유지
기본 스케일링 계획으로도 부르며, 항상 실행 상태를 유지하고자 하는 인스턴스의 수를 지정할 수 있습니다. 일정한 수의 인스턴스가 필요한 경우 최소, 최대 및 원하는 용량에 동일한 값을 설정할 수 있습니다. -
수동 스케일링
기존 Auto Scaling 그룹의 크기를 수동으로 변경할 수 있습니다. 수동 스케일링을 선택하면 사용자가 직접 콘솔이나, API, CLI 등을 이용해 수동으로 인스턴스를 추가 또는 삭제해야 합니다. 해당 방식은 추천하지 않는 방식입니다. -
일정별 스케일링
예측 스케일링트래픽의 변화를 예측할 수 있고, 특정 시간대에 어느 정도의 트래픽이 증가하는지 패턴을 파악하고 있다면 일정별 스케일링을 사용하는 것이 좋습니다. 예를 들어 낮 시간대에는 트래픽이 최고치에 이르고 밤 시간대에는 트래픽이 거의 없다면 낮 시간대에 서버를 증설하고 밤 시간대에 스케일 다운 하는 규칙을 추가하면 됩니다. -
동적 스케일링
수요 변화에 대응하여 Auto Scaling 그룹의 용량을 조정하는 방법을 정의합니다. 이 방식은 CloudWatch가 모니터링하는 지표를 추적하여 경보 상태일 때 수행할 스케일링 규칙을 정합니다. 예를 들어 CPU 처리 용량의 80% 수준까지 급등한 상태가 5분 이상 지속될 경우 Auto Scaling이 작동돼 새 서버를 추가하는 방식입니다. 이와 같은 스케일링 정책을 정의할 때는 항상 스케일 업과 스케일 다운 두 가지의 정책을 작성해야 합니다.
Tomcat
Apache사에서 개발한 서블릿 컨테이너만 있는 오픈소스 웹 애플리케이션 서버입니다.
- 자바 애플리케이션을 위한 대표적인 오픈소스 WAS(Web Application Server)입니다.
- 오픈소스이기 때문에 라이선스 비용 부담 없이 사용할 수 있습니다.
- 독립적으로도 사용 가능하며 Apache 같은 다른 웹 서버와 연동하여 함께 사용할 수 있습니다.
- Tomcat은 자바 서블릿 컨테이너에 대한 공식 구현체로, Spring Boot에 내장되어 있어 별도의 설치 과정이 필요하지 않습니다.
Jetty
Jetty는 이클립스 재단의 HTTP 서버이자 자바 서블릿 컨테이너입니다.
- 2009년 이클립스 재단으로 이전하며 오픈소스 프로젝트로 개발되었습니다.
- Jetty는 타 웹 애플리케이션 대비 적은 메모리를 사용하여 가볍고 빠릅니다.
- 애플리케이션에 내장 가능합니다.
- 경량 웹 애플리케이션으로 소형 장비, 소규모 프로그램에 더 적합합니다.
NGINX

Nginx는 가볍고 높은 성능을 보이는 오픈소스 웹 서버 소프트웨어입니다.
Nginx는 웹 서버로 클라이언트에게 정적 리소스를 빠르게 응답하기 위한 웹 서버로 사용할 수 있습니다.
- Nginx는 트래픽이 많은 웹 사이트의 확장성을 위해 개발된 고성능 웹 서버입니다.
- 비동기 이벤트 기반으로 적은 자원으로 높은 성능과, 높은 동시성을 위해 개발되었습니다.
- 다수의 클라이언트 연결을 효율적으로 처리할 수 있습니다.
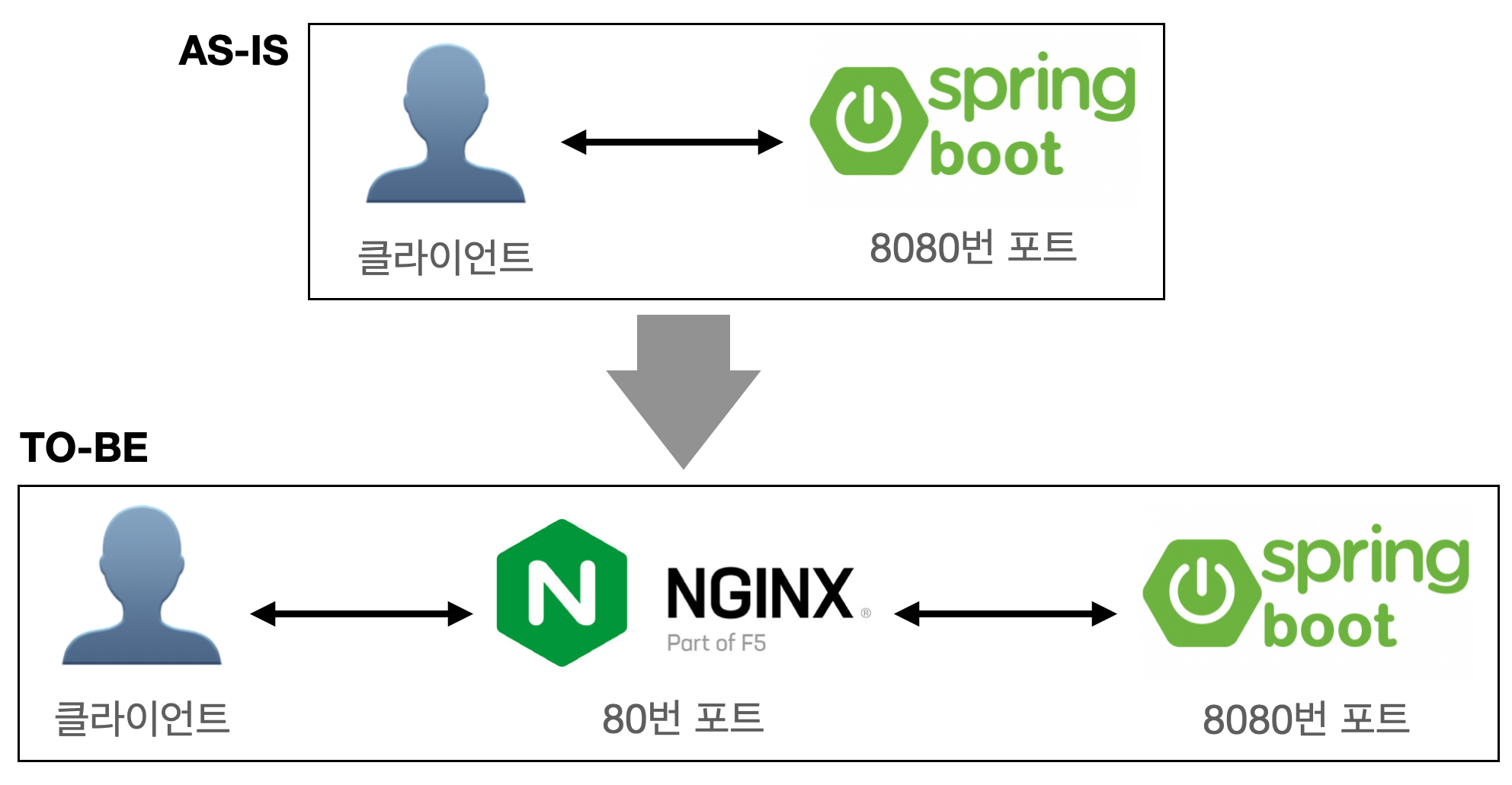
- 클라이언트와 서버 사이에 존재하는 리버스 프록시 서버로 사용할 수 있습니다.
- Nginx를 클라이언트와 서버 사이에 배치하여 무중단 배포를 할 수 있습니다.
Spring Boot와 NGINX 연동

VPC
Virtual Private Cloud 서비스로, 클라우드 내 프라이빗 공간을 제공함으로써, 클라우드를 퍼블릭과 프라이빗 영역으로 논리적으로 분리할 수 있게합니다.
VPC 구성 요소와 주요 용어
IP Address
IP는 컴퓨터 네트워크에서 장치들이 서로를 인식하고 통신을 하기 위해서 사용하는 특수한 번호로, IPv4, IPv6로 나뉘어 있으며 혼용하여 사용하고 있습니다.

십진수의 형태는 보기 편하도록 변형한 것이고, 실제의 형태는 2진수 8자리의 형태, 즉 각 8bit(비트)씩 총 32bit로 구성되어 있습니다. 이때 각 8bit를 Octet이라고 부르며, .으로 구분합니다. 그러므로 IPv4는 4개의 Octet(옥텟)으로 이루어져 있다고 할 수 있습니다.
IP Address Class
IPv4 주소에서 호스트가 연결되어 있는 특정 네트워크를 가리키는 8비트의 네트워크 영역(Network Address)과 해당 네트워크 내에서 호스트의 주소(Host Address)를 가리키는 나머지 영역을 구분하기 위해서 클래스(Class)를 사용했습니다. 클래스는 총 5가지(A, B, C, D, E) 클래스로 나누어져 있습니다. 하지만 D와 E 클래스는 멀티캐스트용, 연구 개발을 위한 예약 IP이므로 보통 사용되지 않습니다.

CIDR(Classless inter-domain routing)
사이더라고 불리며, 클래스 없는 도메인 간 라우팅 기법으로 1993년 도입되기 시작한 국제 표준의 IP주소 할당 방법이며, IP 클래스 방식을 대체한 방식입니다.
기존에는 클래스에 따라 정해진 Network Address와 Host Address를 사용해야 했다면, CIDR은 원하는 블록만큼 Network Address를 지정하여 운용할 수 있습니다.

위 사진에 따르면, /16은 첫 16bit를 Network Address로 사용한다는 의미로, 총 2^16인 65536개의 IP주소를 사용할 수 있는 커다란 네트워크 블록을 이러한 방식으로 표시합니다.
| CIDR 블록 | IP 주소의 수 |
|---|---|
| /28 | 16 |
| /24 | 254 |
| /20 | 4094 |
| /18 | 16382 |
| /16 | 65536 |
서브넷(Subnet)
서브넷은 서브네트워크(Subnetwork)의 줄임말로 IP 네트워크의 논리적인 하위 부분을 가리킵니다. 서브넷을 통해 하나의 네트워크를 여러 개로 나눌 수 있습니다. VPC를 사용하면 퍼블릭 서브넷, 프라이빗 서브넷, VPN only 서브넷등, 필요에 따라 다양한 서브넷을 생성할 수 있습니다.
- 퍼블릭 서브넷 : 인터넷을 통해 연결할 수 있는 서브넷
- 프라이빗 서브넷 : 인터넷을 연결하지 않고, 보안을 유지하는 배타적인 서브넷
- VPN only 서브넷 : 기업 데이터 센터와 VPC를 연결하는 서브넷
서브넷은 VPC의 CIDR 블록을 이용해 정의되며, 최소 크기의 서브넷은 /28입니다. 이때 주의 할 점은 서브넷은 AZ당 최소 하나를 사용할 수 있고, 여러 개의 AZ에 연결되는 서브넷은 만들 수 없습니다.
Tips ) AWS가 확보한 서브넷 중 처음 네 개의 IP주소와 마지막 IP주소는 인터넷 네트워킹을 위해 예약되어 있다. 서브넷에서 가용 IP주소를 계산할 때는 항상 이 부분을 기억하고 있어야 합니다. 예를 들어, 10.0.0.0/24 체계의 CIDR 블록이 있는 서브넷에서 10.0.0.0, 10.0.0.1, 10.0.02, 10.0.0.3, 10.0.0.255 등 5개의 IP주소는 예약되어 있습니다.
라우팅 테이블(Routing Table)
트래픽의 전송 방향을 결정하는 라우트와 관련된 규칙을 담은 테이블로 목적지를 향한 최적의 경로로 데이터 패킷을 전송하기 위한 모든 정보를 담고 있습니다.
쉽게 라우팅 테이블은 하나의 지점에서 또 다른 지점으로 가기 위한 모든 정보르르 제공하기 위한 테이블입니다.
모든 서브넷은 라우팅 테이블을 지닙니다.
예를 들어 아래의 캡처본과 같이 특정 VPC의 서브넷이 라우팅 테이블에 인터넷 게이트웨이(VPC와 인터넷 간 통신을 가능하게 하는 구성요소)를 포함하고 있다면, 해당 서브넷은 인터넷 액세스 권한 및 정보를 가집니다.
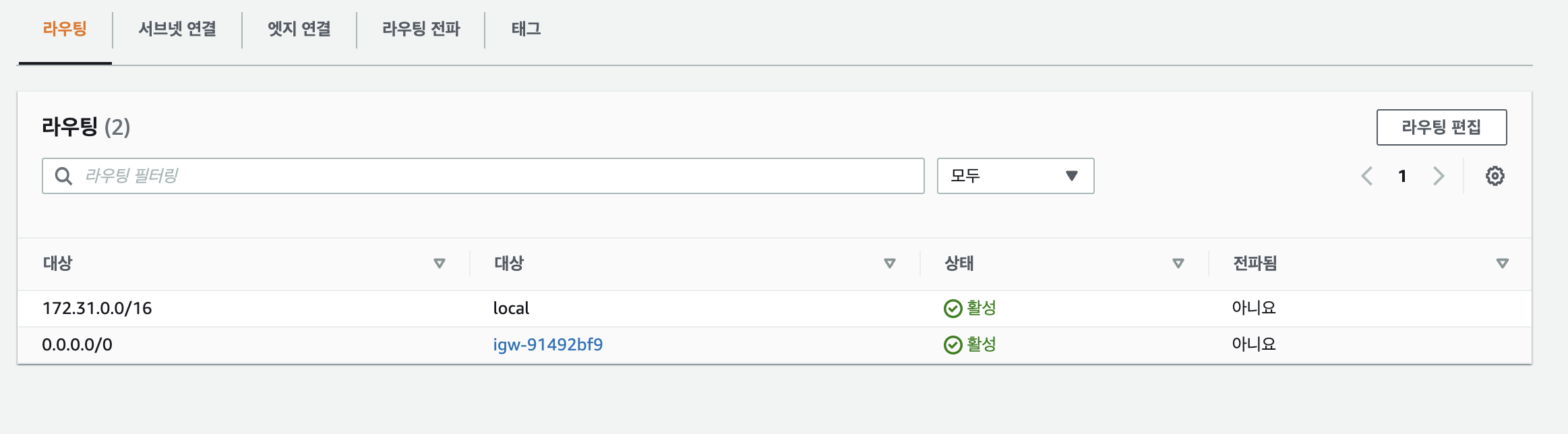
각각의 서브넷은 항상 라우팅 테이블을 가지고 있어야 하며, 하나의 라우팅 테이블 규칙을 여러 개의 서브넷에 연결하는 것도 가능합니다. 서브넷을 생성하고 별도의 라우팅 테이블을 생성하지 않으면 클라우드가 자동으로 VPC의 메인 라우팅 테이블을 연결합니다.
