인덱스 = 색인 : 쉽게 찾아볼 수 있도록 일정한 순서에 따라 놓은 목록
데이터베이스에서의 인덱스
데이터가 특정 기준으로 정렬되어 있다면 검색을 빠르게 할 수 있을 것이다.
데이터베이스 테이블에 대한 검색 성능을 향상시키는 자료 구조이며 where 절 등을 통해 활용된다.
인덱스의 특징
- 인덱스는 항상 최신의 정렬 상태를 유지
- 인덱스도 하나의 데이터베이스 객체
- 데이터베이스 크기의 약 10% 정도의 저장공간 필요
Full Table Scan
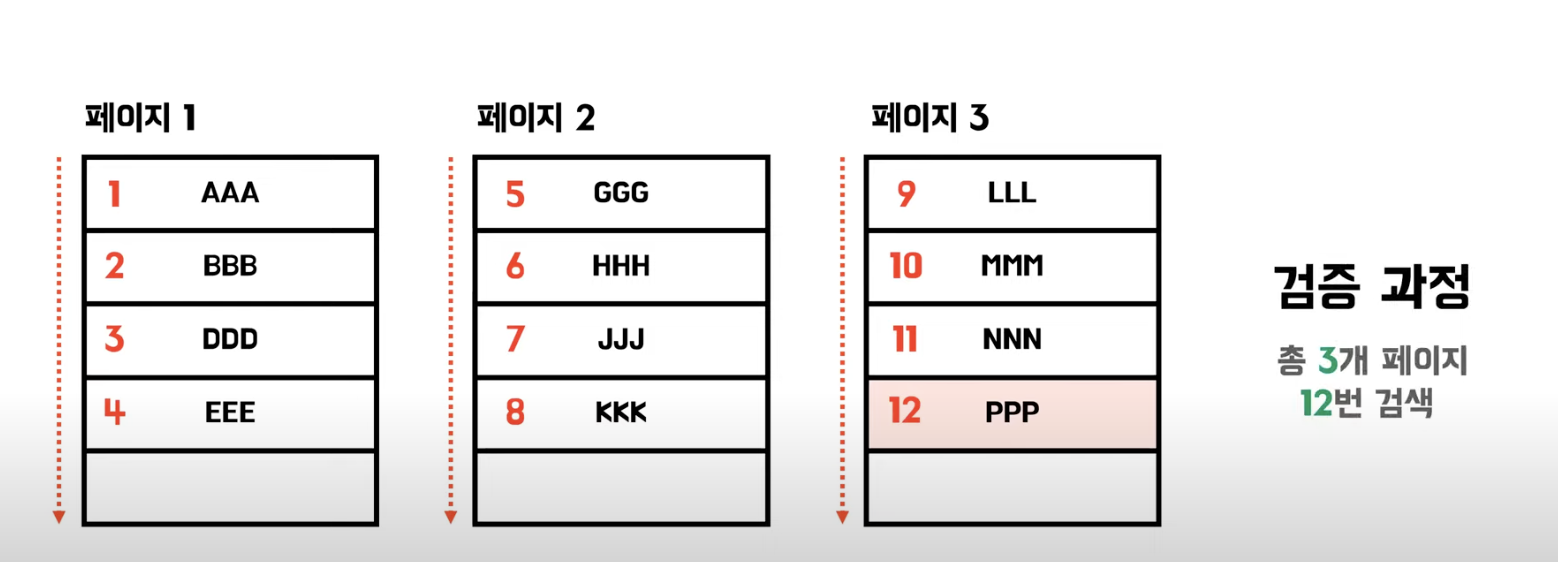
- 순차적으로 접근
- 접근 비용 감소
언제 사용하는가?
1. 적용 가능한 인덱스가 없는 경우
2. 인덱스 처리 범위가 넓은 경우
3. 크기가 작은 테이블에 엑세스하는 경우
즉, 인덱스를 적용하여도 성능상의 이점이 없는 경우에 사용
B-Tree
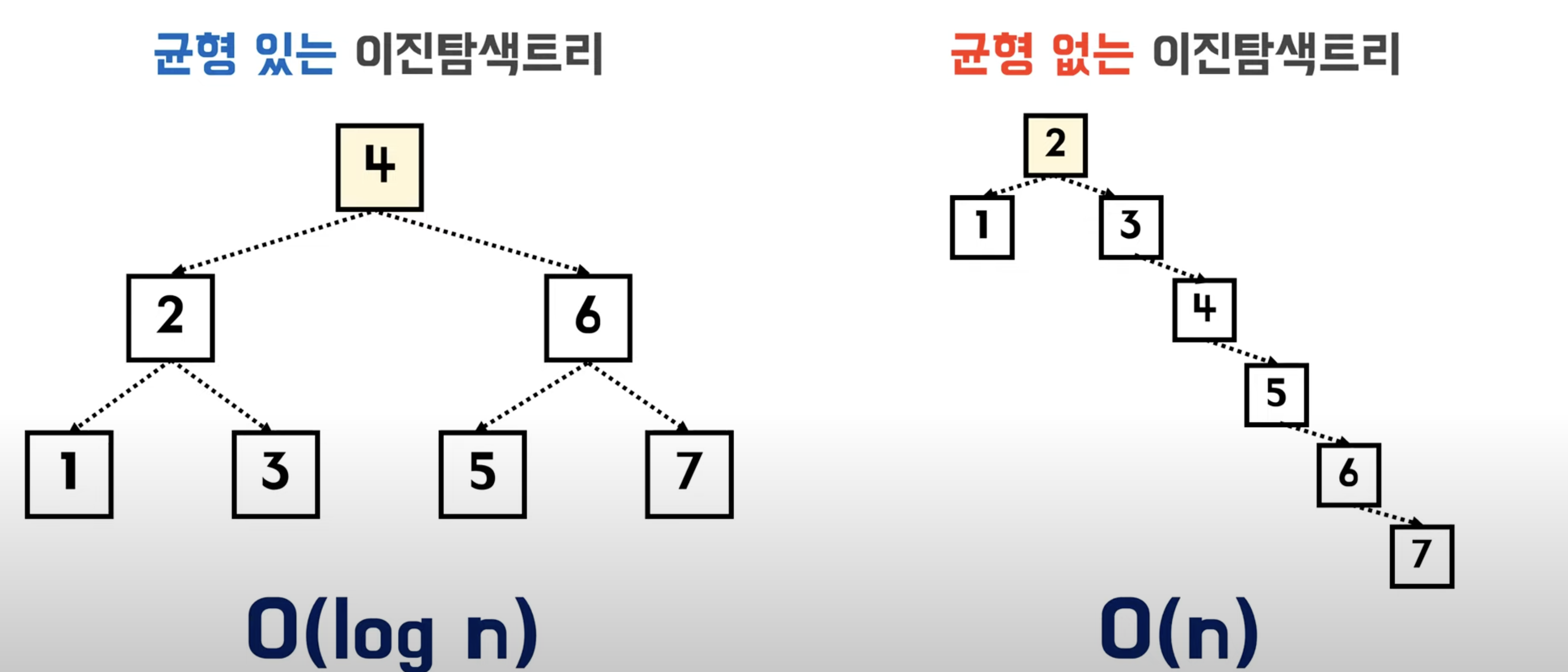 이진탐색트리의 단점을 보안하기 위한 자료구조
이진탐색트리의 단점을 보안하기 위한 자료구조
- 트리 높이가 같음
- 자식 노드를 2개 이상 가질 수 있음
- 기본 데이터베이스 인덱스 구조
B-Tree INSERT
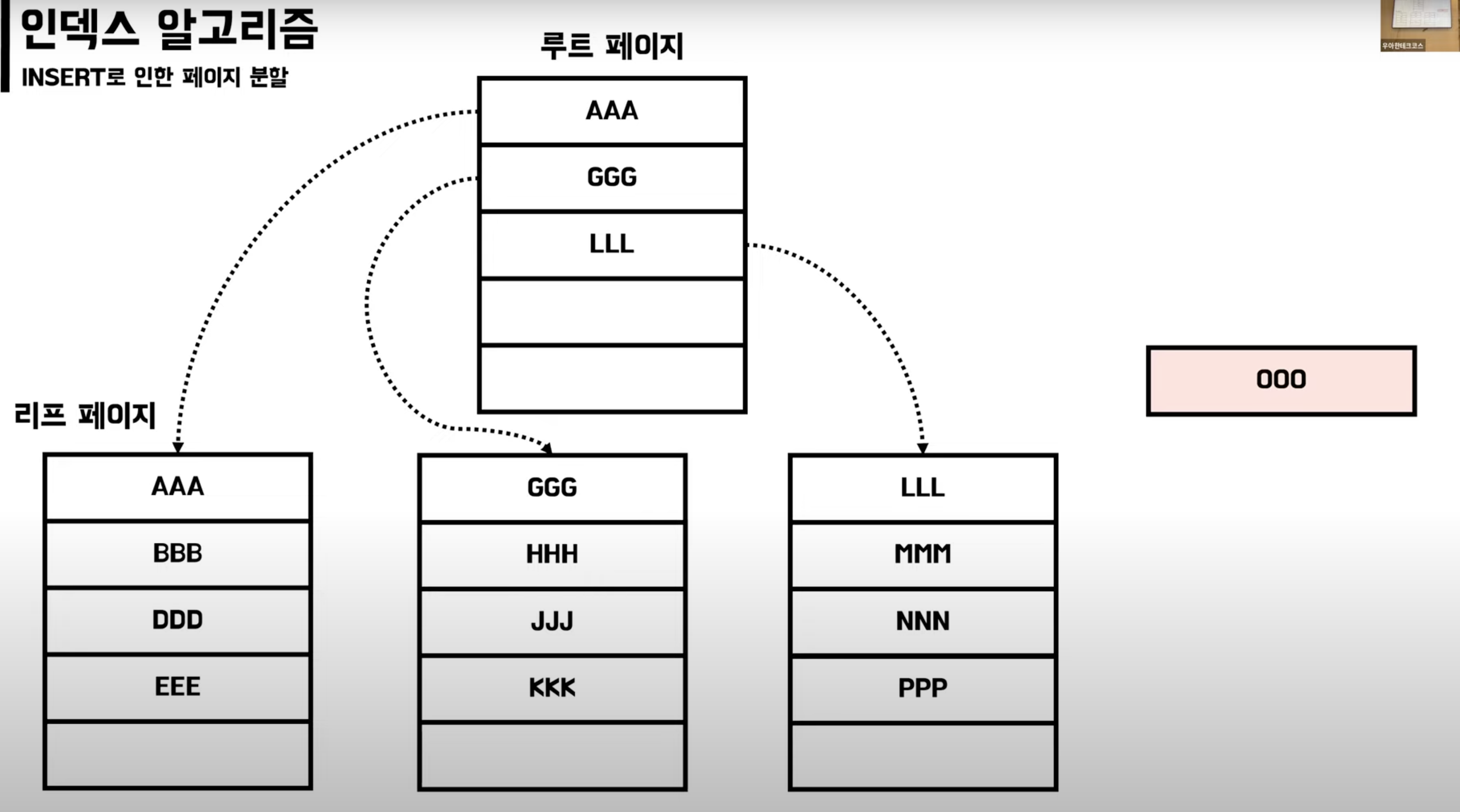
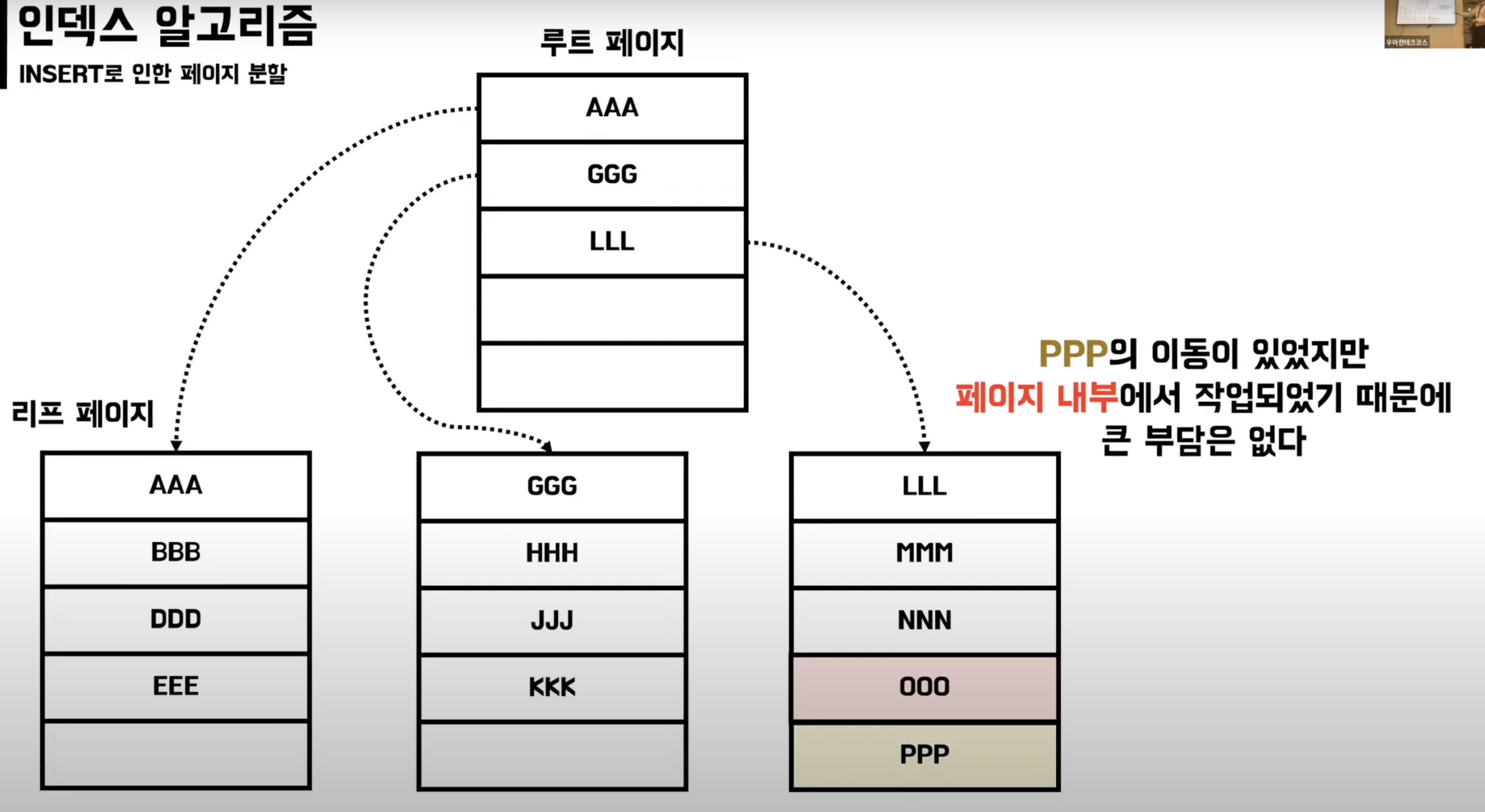
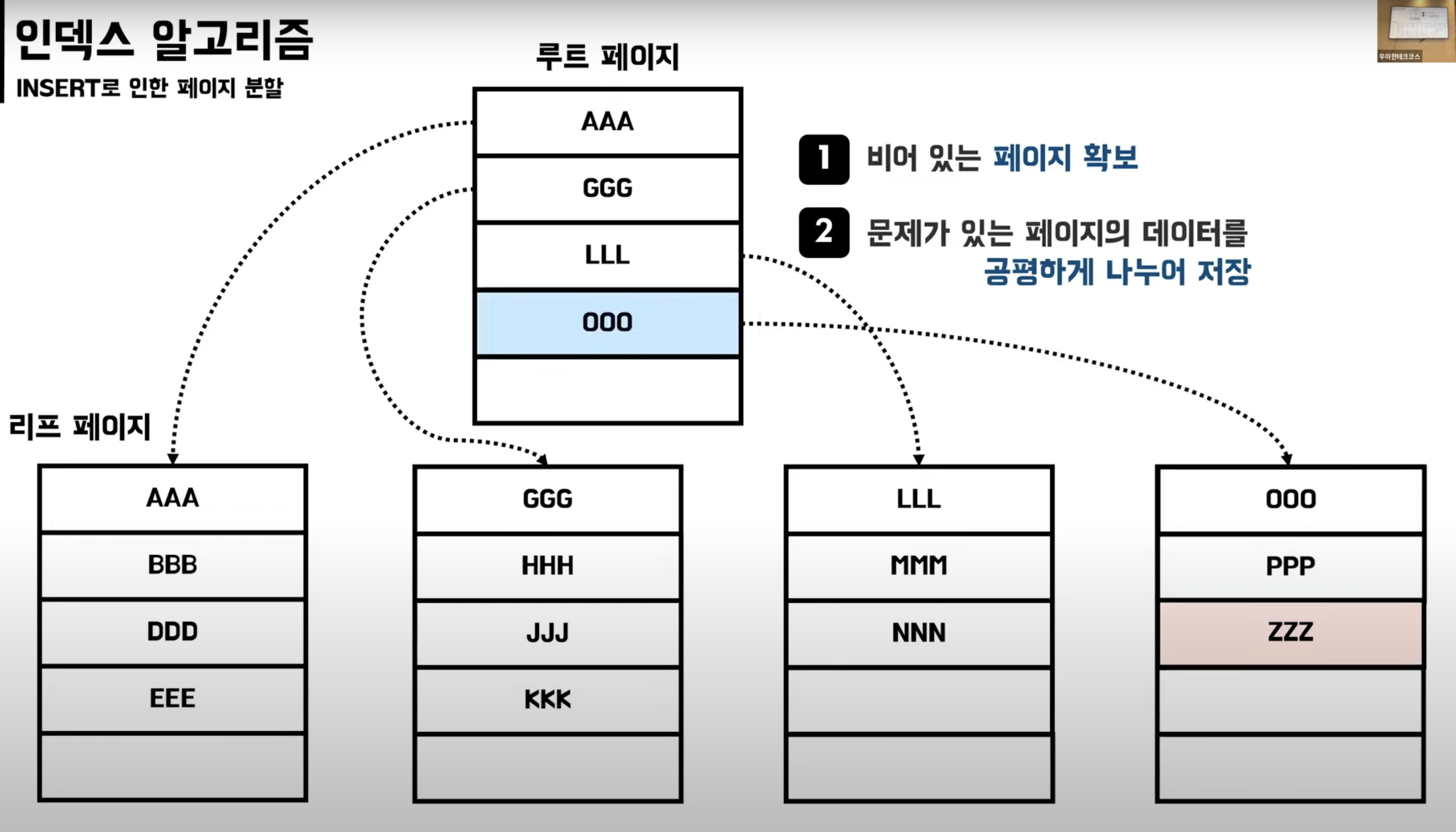
페이지 분할
- 페이지에 새로운 데이터를 추가할 여유공간이 없어 페이지에 변화가 발생
- DB가 느려지고 성능에 영향을 준다.
B-Tree DELET
인덱스의 데이터를 실제로 지워지 않고 사용 안함 표시를 한다.
B-Tree UPDATE
- DELETE(기존 값 사용안함 표시)
- INSERT(변경된 값 삽입)
DELETE, UPDATE 둘다 where 절로 처리할 대상을 찾기 위한 조회 성능은 향상된다.
- 사용하지 않는 인덱스가 적용되었다면 불필요한 처리량 증가
- 사용안함 표시로 페이지 낭비 및 인덱스 조각화 심해짐
정리
select -> 성능이 향상
insert, update, delete -> 페이지 분할과 사용안함 표시로 인덱스의 조각화가 심해져 성능이 저하된다.
인덱스의 종류
클러스터링 인덱스
- 실제 데이터와 같은 무리의 인덱스
- 실제 데이터가 정렬된 사전
논-클러스터링 인덱스
- 실제 데이터와 다른 무리의 별도의 인덱스
- 실제 데이터 탐색에 도움을 주는 별도의 찾아보기 페이지(책 맨 뒷페이지)
 primary key 적용시 -> 클러스터링 인덱스 자동 생성
primary key 적용시 -> 클러스터링 인덱스 자동 생성
unique 적용히 -> 논 클러스터링 인덱스 자동 생성
클러스터링 인덱스
생성 방법

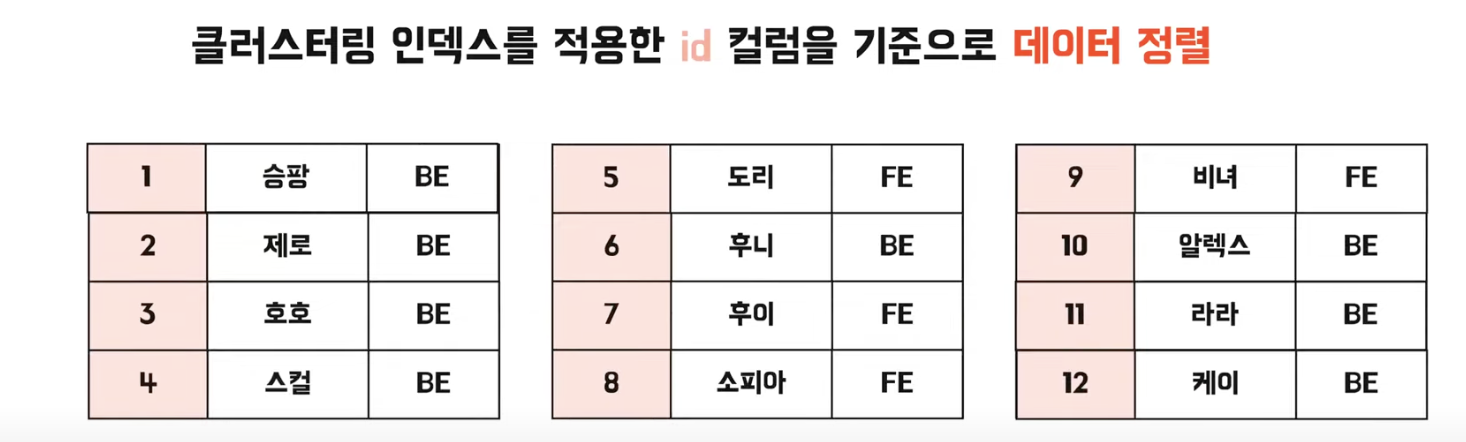
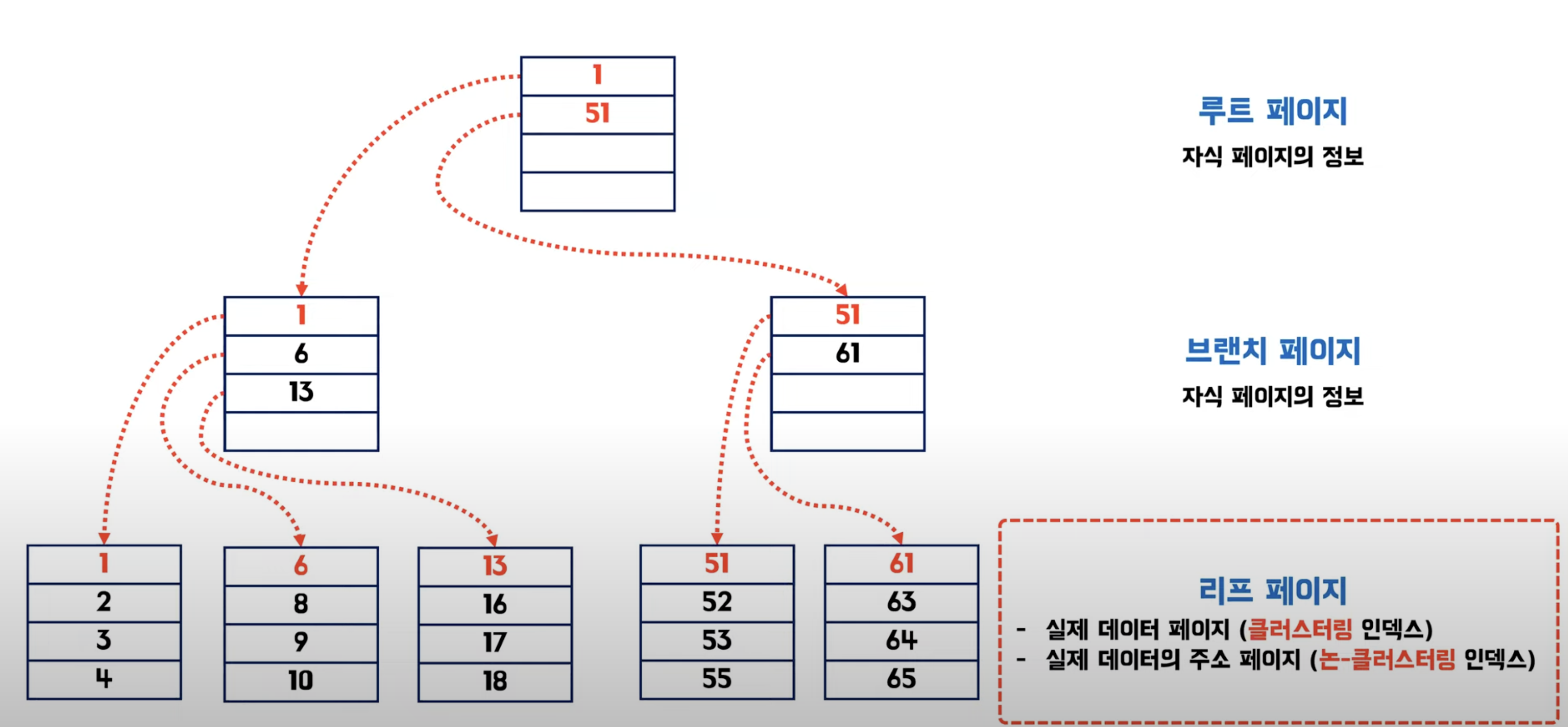
B-tree 방식으로 구성됨 1000-> 리프 페이지(데이터페이지 = 실제 데이터가 저장된 곳)의 주소
클러스터링 인덱스 방식에서의 id 찾기
클러스터링 인덱스 특징
- 실제 데이터 자체가 정렬
- 테이블당 1개만 존재 가능
- 리프 페이지가 데이터 페이지
- 아래로 제약조건 시 자동생성
- primary key(우선순위)
- unique + not null
논-클러스터링 인덱스
생성 방법
그냥 index 생성시에는(방법 3) 중복을 허용한 논-클러스터링 인덱스 생성 방식
인덱스 구성
- 데이터페이지와 리프페이지는 별도
- 1002 + #3 => 1002페이지주소의 3번째 데이터를 의미
- 책 뒷페이지의 찾아보기 페이지와 비슷한 느낌
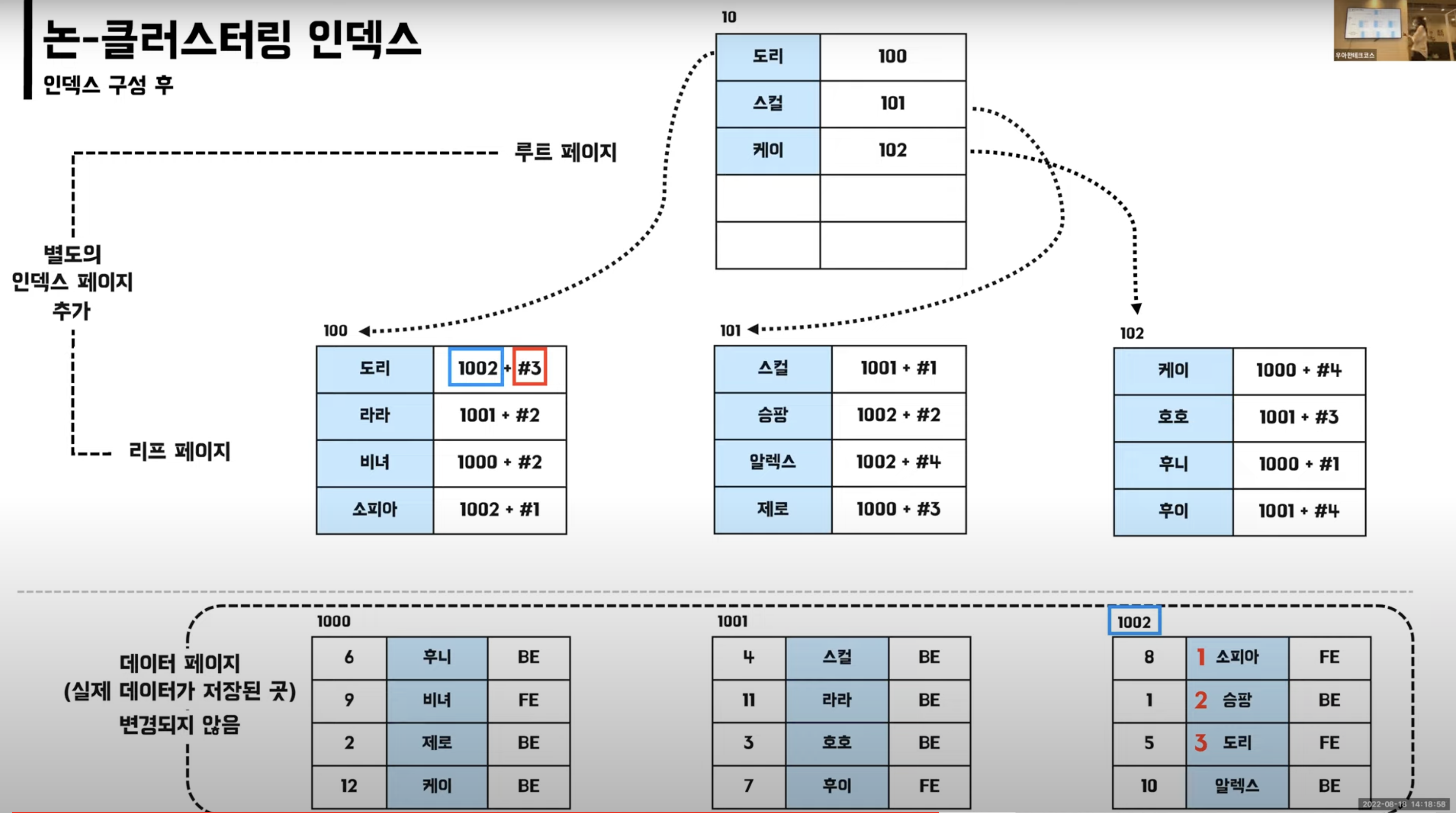
논-클러스터링 인덱스 방식에서의 이름 찾기
논-클러스터링 인덱스 특징
- 실제 데이터 페이지는 그대로
- 별도의 인덱스 페이지 생성 -> 추가 공간 필요
- 테이블당 여러 개 존재
- 리프 페이지에 실제 데이터 페이지 주소를 담고 있음
- unqiue 제약조건 적용시 자동생성
- 직접 index 생성시 논-클러스터링 인덱스 생성
클러스터링과 논 클러스터링 인덱스를 같이 사용하게 된다면?
데이터페이지의 주소와 위치값을 가지고 있을 것 같았지만 논 클러스터링 인덱스 페이지에는 클러스터링 인덱스가 적용된 컬럼의 실제 값을 가지고 있음
실제 조회 방식
인덱스 적용 기준
카디널리티: 그룹 내 요소의 개수
어떤 컬럼에 인덱스를 적용해야 할까?
1. 카디널리티가 높은 (중복도가 낮은) 컬럼( id, 이메일, 주민번호 등등 )
2. where, join, order by 절에 자주 사용되는 컬럼
- 인덱스는 추가 공간이 필요로 한다.
- 조건 절이 없다면 인덱스가 사용되지 않는다.
3. insert / update / delete 가 자주 발생하지 않는 컬럼
- 데베 성능 이슈
4. 규모가 작지 않은 테이블
- 인덱스 적용시 성능 효과 미미하면 의미 없음
인덱스 사용시 주의 사항
- 잘 활용되지 않는 인덱스는 과감히 제거하자
- where 절에 사용되더라도 자주 사용해야 가치가 있다.
- 불필요한 인덱스로 성능저하가 발생할 수 있다.
- 데이터 중복도가 높은 컬럼은 인덱스 효과가 적다.
- 자주 사용되더라도 insert/update/delete가 자주 일어나는지 고려해야한다.
- 일반적인 웹 서비스와 같은 온라인 트랜잭션 환경에서 쓰기와 읽기 비율은 2:8 또는 1:9이다.
- 조금 느린 쓰기를 감수하고 빠른 읽기를 선택하는 것도 하나의 방법이다.
