슈퍼타입/서브타입 개요
Extended ER모델이라고 부르는 슈퍼/서브타입 데이터 모델은 논리적인 데이터 모델에서 이용되는 형태이고 분석단계에서 많이 쓰이는 모델이다.
따라서 물리적인 데이터 모델을 설꼐하는 단계에서는 슈퍼/서브타입 데이터 모델을 일정한 기준에 의해 변환해야 한다.
물리적인 데이터 모델이 성능을 고려한 데이터 모델이 되어야 한다는 점을 고려하면 막연하게 슈퍼/서브타입을 아무런 기준없이 변환하는 것 자체가 성능이 저하될 수 있는 위험이 있다.
*상속과 트랜잭션이 키워드*슈퍼/서브 타입모델
업무를 구성하는 데이터를 공통과 차이점의 특징을 고려하여 효과적으로 표현한 모델.
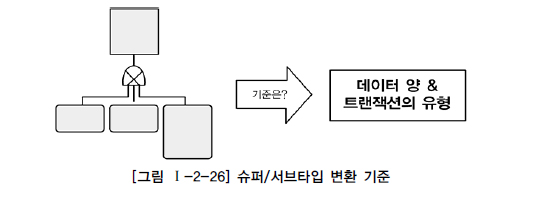
슈퍼/서브 타입 데이터 모델의 성능저하 원인
- 슈퍼/서브타입에 대한 변환을 잘못하면 성능이 저하되는 이유는 트랜잭션 특성을 고려하지 않고 테이블이 설계되었기 때문이다.
- 트랜잭션은 항상 일괄로 처리하는데 테이블은 개별로 유지되어 Union연산에 의해 성능이 저하될 수 있다.
- 트랜잭션은 항상 서브타입 개별로 처리하는데 테이블은 하나로 통합되어 있어 불필요하게 많은 양의 데이터가 집약되어 있어 성능이 저하되는 경우가 있다.
- 트랜잭션은 항상 슈퍼+서브 타입을 공통으로 처리하는데 개별로 유지되어 있거나 하나의 테이블로 집약되어 있어 성능이 저하되는 경우가 있다.
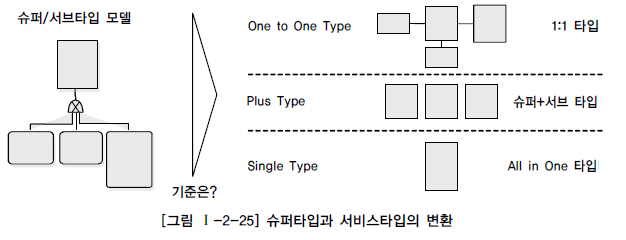
슈퍼/서브 타입 변환기준
슈퍼/서브타입 데이터 모델의 변환기술
1. OneToOne Type
개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성
업무적으로 발생되는 트랜재겻ㄴ이 슈퍼타입과 서브타입 각각에 대해 발생하는 것
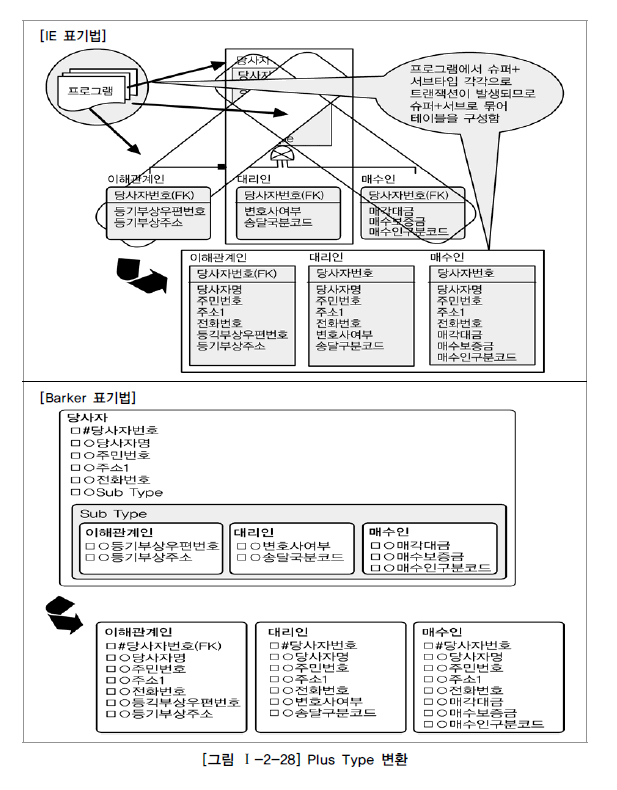
2. Plus Type
슈퍼타입+서브타입에 대해 발생되는 트랜잭션에 대해서는 슈퍼타입+서브타입 테이블로 구성
슈퍼타입과 서브타입을 묶어 트랜잭션이 발생하는 업무특징을 가지고 있을 때에는 다음 데이터 모델과 같이 슈퍼타입+각 서브타입을 하나로 묶어 별도의 테이블로 구성하는 것이 효율적이다.
3. Sigle Type / All In One Type
전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성
비록 슈퍼타입과 서브타입의 테이블들을 하나로 묶었을 때 각각의 속성별로 제약사항(NULL/NOT NULL, 기본값, 체크값)을 정확하게 지정하지 못할지라도 대용량이고 성능향상이 필요하다면 하나의 테이블로 묶어서 만들어 준다.
슈퍼/서브타입 데이터 모델의 변환타입 비교
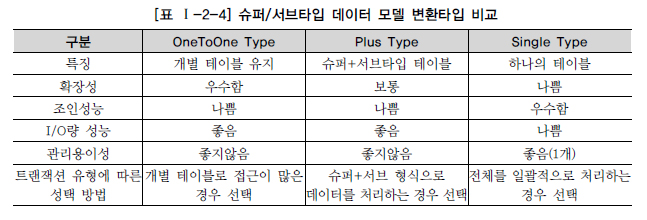
각성능이 좋을 수도 나쁠 수도 있기 때문에 변환 모델의 선택은 철저하게 데이터 베이스에 발생되는 트랜잭션의 유형에 따라 선택해야 한다.
인덱스 특성을 고려한 PK/FK DB성능향상
PK/FK칼럼 순서와 성능개요 데이터를 조회할 때 가장 효과적으로 처리될 수 있도록 접근경로를 제공하는 오브젝트가 인덱스이다.
인덱스의 특징은 여러 개의 속성이 하나의 인덱스로 구성되어 있을 때 앞쪽에 위치한 속성의 값이 비교자로 있어야 좋은 효율을 나타낸다.
앞쪽에 위치한 속성의 값이 비교적 '=' 아니면 최소한 범위 'BETWEEN' '<>'가 들어와야 효율적이다.
인덱스는 도서관에 있는 책의 장르별 ㄱㄴㄷ 순 같은거라고 생각하자 