ROLLUP
ROLLUP에 지정된 GROUPING COLUMNS LIST는 SUBTOTAL을 생성하기 위해 사용되어지며, GROUPING COLUMNS의 수를 N 이라고 했을 때 N+1 LEVEL의 SUBTOTAL이 생성된다.
즉 소그룹간의 합계를 구하는 함수이며,
- 인수 계층 구조
- 인수 순서가 바뀌면 결과도 바뀐다
- 예제
부서명과 업무명을 기준으로 사원수와 급여 합을 집계한 일반적인 SQL 문장 과 ROLLUP 함수를 사용한 SQL 문장 비교
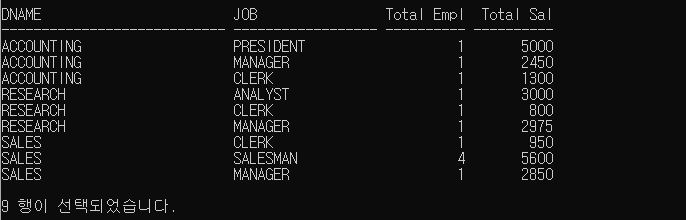
----------일반적인 GROUP BY-------------
SELECT DNAME, JOB, COUNT(*) "Total Empl",SUM(SAL) "Total Sal"
FROM EMP,DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME JOB; -> 결과
-------------ROLLUP 사용-------------
SELECT DNAME, JOB, COUNT(*) "Total Empl",SUM(SAL) "Total Sal"
FROM EMP,DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME,JOB);->결과
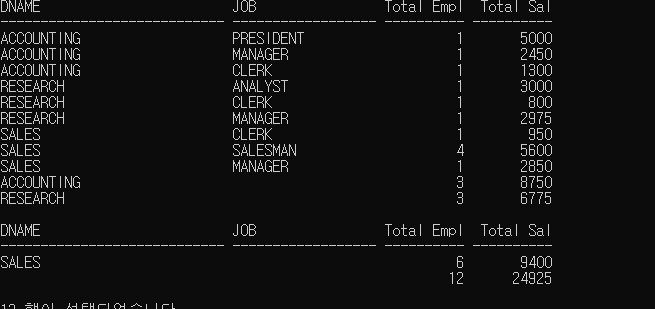
ROLLUP은 계층구조라고 하였다.
위 결과에서
JOB가 NULL 값인 행이 L2
DNAME과 JOB가 NULL값인 행이 L3에 해당한다.
CUBE
결합 가능한 모든 값에 대하여 다차원 집계를 생성하며,
ROLLUP에 비해 시스템 부하가 심하다.
인수들 간 평등한 관계를 가지며 순서가 바뀌어도 결과가 같다.
CUBE는 GROUPING COLUMNS이 가질 수 있는 모든 경우의 수에 대하여 Subtotal을 생성하므로 GROUPING COLUMNS의 수가 N이라고 가정하면, 2의 N승 LEVEL의 Subtotal을 생성하게 된다
SELECT DNAME, JOB, COUNT(*) "Total Empl",SUM(SAL) "Total Sal"
FROM EMP,DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE(DNAME,JOB);-결과
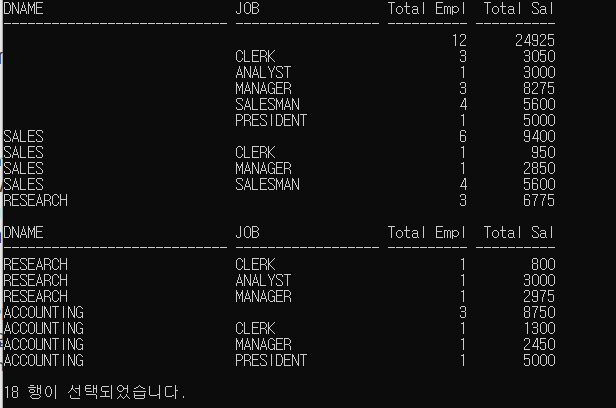
ROLLUP 예제에서 CUBE로 바꾼게 전부이지만, 결과가 사뭇 다르다.
하지만 게층형 구조라는 것은 같으며 모든 경우의 수에 대하여 Subtotal을 생성하므로 행의 수가 상대적으로 많다.
GROUPING 함수
ROLLUP이나 CUBE에의한 집계 표시면 1, 아니면 0을 표시한다.
- 예제
ROLLUP 함수를 추가한 집계 보고서에서 집계 레코드를 구분할 수 있는 GROUPING 함수가 추가된 문장
SELECT DNAME, GROUPING(DNAME), JOB, GROUPING(JOB),
COUNT(*) "Total Empl",SUM(SAL) "Total Sal"
FROM EMP,DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME,JOB);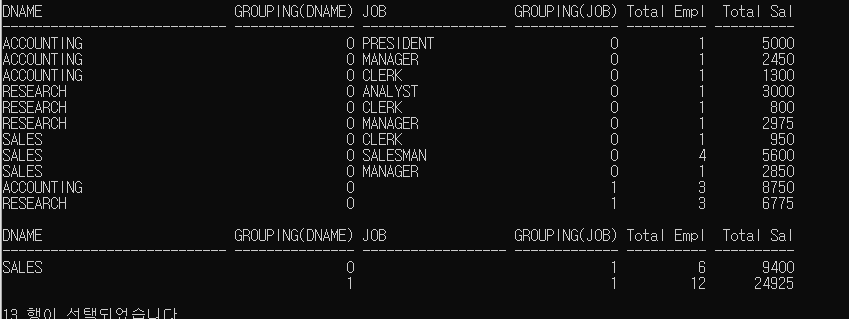
GROUPING 함수 덕분에 LEVEL 파악이 훨씬 쉬워졌다.
GROUPING SETS 함수
인수들에 대한 개별 집계를 구할 수 있다.
다양한 소계 집합 생성 가능
- 일반 그룹함수와 GROUPING SETS를 사용한 SQL 비교
--------------------일반 그룹함수-----------------
SELECT DNAME,"ALL JOBS" JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY DNAME UNION ALL
SELECT 'All Departments'DNAME, JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO=EMP.DEPTNO
GROUP BY JOB;-> 결과
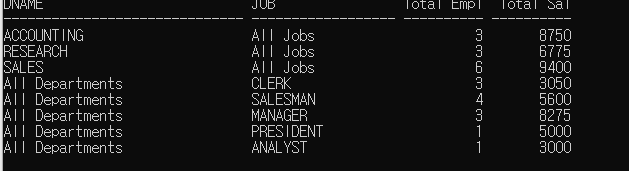
------------------GROUPING SETS 함수 사용---------------------
SELECT DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME, DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB, COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS (DNAME, JOB);-> 결과

훨씬 간결한 SQL문장으로 같은 결과를 얻을 수 있다.
