JPA의 다양한 쿼리 지원 방법
JPQL(Java Persistence Query Language)
SQL을 추상화한 객체 지향 쿼리 언어이다.
JPQL은 엔티티 객체를 대상으로 쿼리한다.
SQL은 데이터베이스 테이블을 대상으로 쿼리한다
예제
List<Member>result = em.createQuery(
"select m from Member m where m.username like '%kim%'", Member.class
).getResultList();그래도 SQL 을 멀리서 지켜봤던 나로서는 저 정도는 어떤 쿼리인 지 알 수 있었다.
username 에 김 이 들어간 사람을 찾으면 되는 쿼리 같았다.
근데 문법이 조금 달라서 신경써야 할 것 같았다.
SQL 에서는 seletct 뒤에 m.username을 적어줘야 되는데 JPQL형님은 그런 게 필요 없나보다.
필요시 찾아서 다시 공부
Criteria, QueryDSL, 네이티브 SQL, JDBC 직접 사용, SpringJdbcTemplate 등
그럼 이제 다시 JPQL을 공부해보자!
JPQL 문법
- select m from Member as m where m.age > 18
이렇게 엔티티와 속성은 대소문자 구문해야 한다.- JPQL키워드는 대소문자 구분하지 않는다.(SELECT, where 등)
- 엔티티의 이름을 사용한다. @Entity(name=" 이 친구 ")
거의 기본값 사용
-별칭(m)은 필수이고 as는 생략이 가능하다.
TypeQuery, Query
- TypeQuery: 반환 타입이 명확할 때 사용
- Query: 반환 타입이 명확하지 않을 때 사용

결과조회
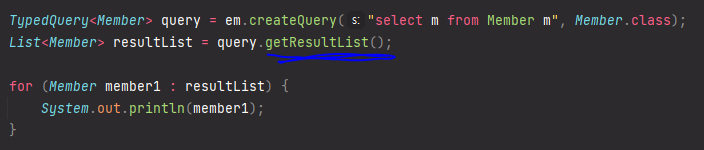
List<Member> result = em.createQuery(
"select m from Member m", Member.class
).getResultList();이렇게 한번에 할 수도 있다.
getResultList() - 결과가 하나 이상일 때, 리스트 반환
결과가 없으면 빈 리스트를 반환한다.

getSingleResult() - 결과가 정확히 하나일 때, 단일 객체 반환
• 결과가 없으면: javax.persistence.NoResultException
• 둘 이상이면: javax.persistence.NonUniqueResultException
파라미터 바인딩
이름기준
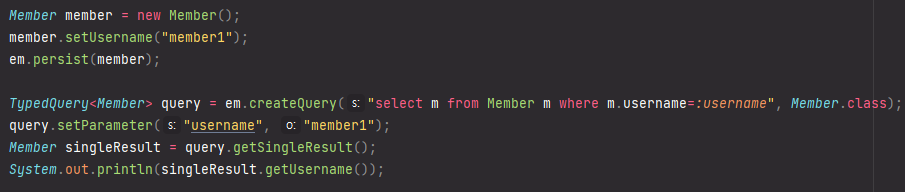
이렇게 이름을 찾을수도 있고
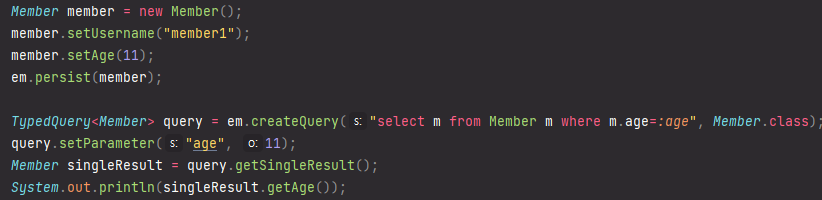
이렇게 나이를 찾을 수도 있다.
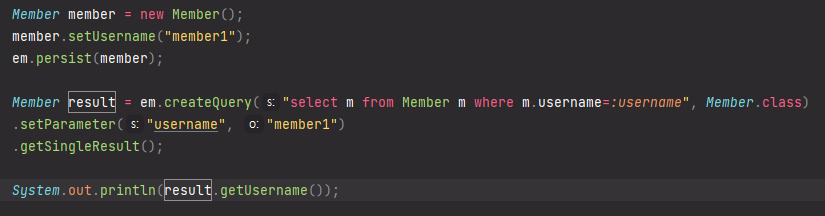
체인? 으로 코드를 깔끔하게 짤 수도 있다.
위치기준도 있지만 이름기준을 쓰도록 하자!
프로젝션
SELECT 절에 조회할 대상을 지정하는 것이다.

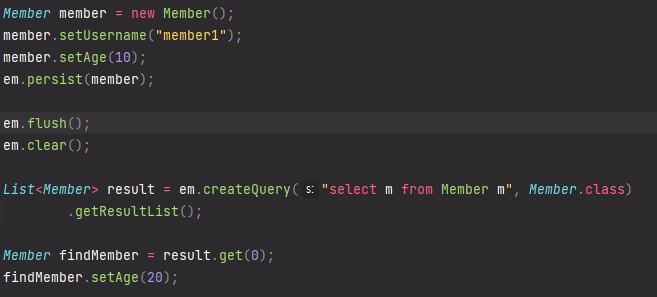
- !중요!
쿼리의 결과가 담긴 result는 영속성을 가지고 있다.
따라서 퀴리문 밑에 setAge도 commit을 해주면 반영이 된다.
스칼라 타입 프로젝션 값 조회
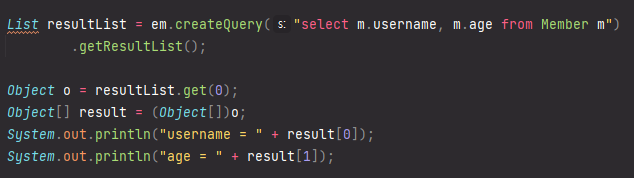
1. Query 타입으로 조회
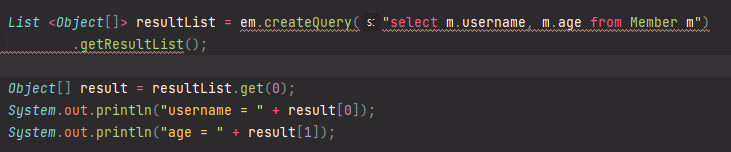
2. Object[] 타입으로 조회

3. new 명령으로 조회
select 뒤에 new 패키지경로.클래스 이름(생성자~~) 를 해줘야 한다.
Dto에 순서와 타입이 일치하는 생성자를 만들어야 사용할 수 있다.
페이징
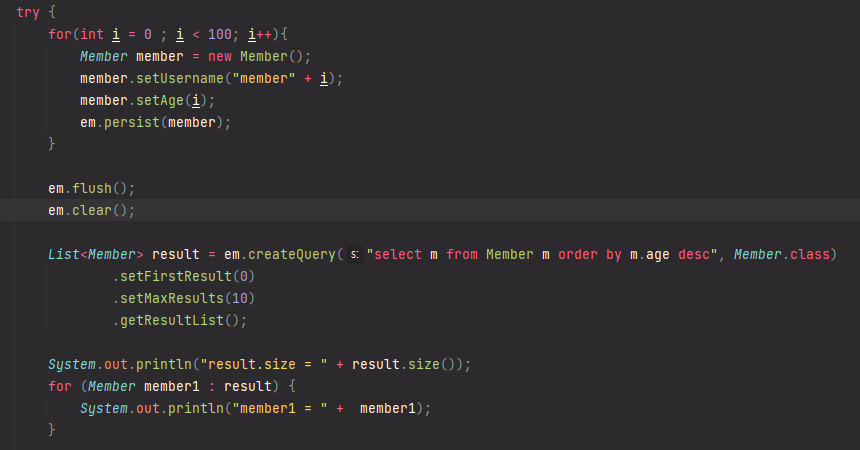
페이징 예제 코드
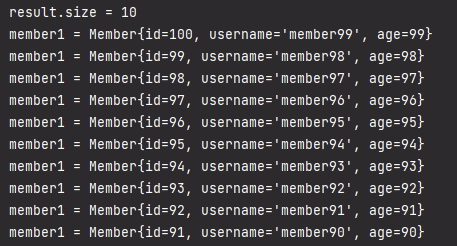
실행결과
• setFirstResult(int startPosition) : 조회 시작 위치
(0부터 시작)
• setMaxResults(int maxResult) : 조회할 데이터 수
@Override
public String toString() {
return "Member{" +
"id=" + id +
", username='" + username + '\'' +
", age=" + age +
'}';
}!! Member.class 에 toString()을 오버라이딩 했다.
조인
Inner Join, Left Outer Join, Outer Join, 세타 조인
이렇게 생각하면 될 것 같다.
- Inner Join : 교집합
- Left Outer Join :
ex) a LEFT OUTER JOIN b 이라고 한다면 a의 모든 행과, b에 함께있는 행을 얻는다. 즉 b는 a와 겹치는 b만 출력한다.- Outer Join : 합집합

inner 조인 문법인데 outer join 이나 left outer join도 똑같이 쓰면 된다.
조금만 바꿔주면 끝

이건 세타 조인의 문법이다.
ON절
- 조인할 때 조인 대상을 필터링 할 수 있다.
- 연관관계가 없는 엔티티를 외부조인(outer join)을 할 수 있다.
예제1
SELECT m, t FROM Member m LEFT JOIN m.team t on t.name = 'A' 회원과 팀을 조인하면서, 팀 이름이 A인 팀만 조인
예제2
SELECT m, t FROM Member m LEFT JOIN Team t on m.username = t.name회원의 이름과 팀의 이름이 같은 대상 외부 조인(연관관계 X)
서브쿼리
예제
- 나이가 평균보다 많은 회원
select m from Member m
where m.age > (select avg(m2.age) from Member m2)
- 한 건이라도 주문한 고객
select m from Member m
where (select count(o) from Order o where m = o.member) > 0메인쿼리랑 서브쿼리가 관계가 없다면 성능이 잘 나온다.(m1, m2)
서브쿼리 지원 함수
- [NOT] EXISTS (subquery): 서브쿼리에 결과가 존재하면 참
{ALL | ANY | SOME} (subquery)
ALL 모두 만족하면 참
ANY, SOME: 같은 의미, 조건을 하나라도 만족하면 참- [NOT] IN (subquery): 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참
예제
- 팀A 소속인 회원
select m from Member m
where exists (select t from m.team t where t.name = ‘팀A')
- 전체 상품 각각의 재고보다 주문량이 많은 주문들
select o from Order o
where o.orderAmount > ALL (select p.stockAmount from Product p)
- 어떤 팀이든 팀에 소속된 회원
select m from Member m
where m.team = ANY (select t from Team t)
From절 에서는 서브쿼리가 불가능하다.
JPQL 타입 표현
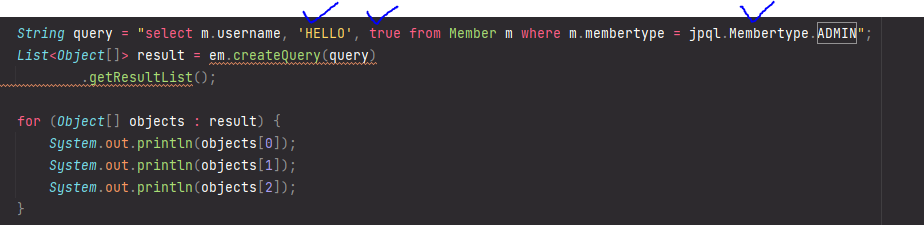
문자, Boolean, ENUM 사용법이다. 출력은 다 제대로 된다!
String query = "select m.username, 'HELLO', true from Member m
where m.membertype = :userType";
List<Object[]> result = em.createQuery(query)
.setParameter("userType", Membertype.ADMIN)
.getResultList();파라미터 바인딩 한다면 이렇게 바꿀 수 있다.
조건식 - CASE식
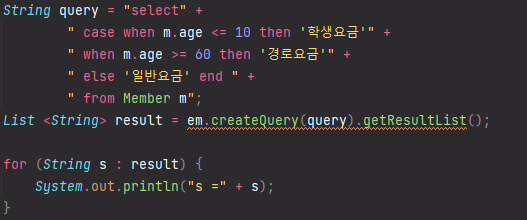
기본 CASE식
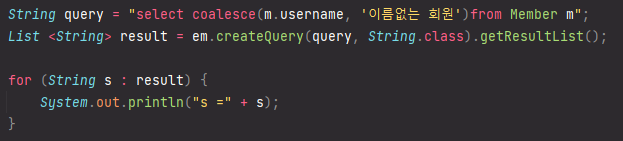
COALESCE: 하나씩 조회해서 null이 아니면 반환, null이면 오른쪽에 문자열 반환
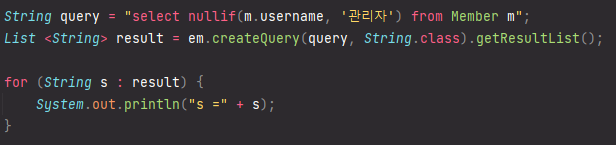
NULLIF: 두 값이 같으면 null 반환, 다르면 첫번째 값 반환
JPQL 기본 함수
• CONCAT - 문자열 더하기(연결)
• SUBSTRING - 문자열 일부 가져오기
• TRIM - 선행 후 후행 문자 제거
• LOWER, UPPER - 문자열을 대소문자 변경
• LENGTH - 길이 반환
• LOCATE - 부분 문자열 찾기
• ABS, SQRT, MOD - 수학 관련
• SIZE, INDEX(JPA 용도)
등이 있다. 필요할 때마다 사용법을 찾아 쓰면 될 거 같다!
사용자 정의 함수 호출
package jpql.dialect;
import org.hibernate.dialect.H2Dialect;
import org.hibernate.dialect.function.StandardSQLFunction;
import org.hibernate.type.StandardBasicTypes;
// 사용하는 Dialect를 상속받는다.
public class MyH2Dialect extends H2Dialect {
public MyH2Dialect() {
registerFunction("group_concat", new StandardSQLFunction("group_concat", StandardBasicTypes.STRING));
}
}MyH2Dialect.class
<!-- <property name="hibernate.dialect"
value="org.hibernate.dialect.H2Dialect"/> -->
<property name="hibernate.dialect"
value="jpql.dialect.MyH2Dialect"/>persistence.xml
기존에 등록 되어있던 것을 주석처리 후 새로 만든것을 등록한다.
select function('group_concat', i.name) from Item i그 후 사용하면 끝!!
경로 표현식
점을 찍어 객체 그래프를 탐색하는 것을 의미한다.
select m.username -> 상태 필드
from Member m
join m.team t -> 단일 값 연관 필드
join m.orders o -> 컬렉션 값 연관 필드
where t.name = '팀A'
잘 구분하자!!
1. 상태 필드(state field): 단순히 값 저장을 위한 필드(ex: m.username)
경로 탐색의 끝.2. 연관 필드(association field): 연관관계를 위한 필드
단일 값 연관 필드 : @ManyToOne, @OneToOne, 대상이 엔티티(ex: m.team)
- 경로 탐색 가능.
- 묵시적 내부 조인(inner join) 발생.
- 쿼리 튜닝이 어렵다.
컬렉션 값 연관 필드 : @OneToMany, @ManyToMany, 대상이 컬렉션(ex: m.orders)
- 경로 탐색 불가능(컬렉션이기 때문에 내부 탐색이 안된다.)
- 묵시적 내부 조인(inner join) 발생.
극복 방법
명시적 조인으로 바꿔준다.

위 코드를 아래 코드로!
실무에서는 명시적 조인을 쓰자 묵시적 조인 노노!!!!
페치 조인(fetch Join)
실무에서 정말정말 중요하다고 하니 집중해서 해보자!
- JPQL에서 성능 최적화를 위해 제공하는 기능
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
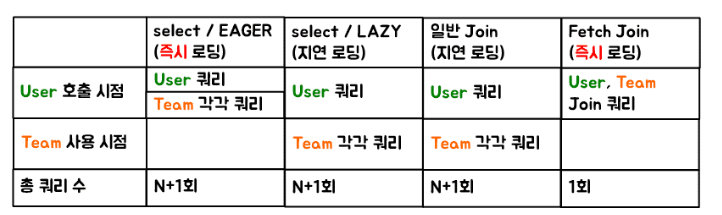
즉 N+1 문제를 해결할 수 있는 대단한 형님이시다.
N+1 이란?
엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 되는 것이다.
String query = "select m from Member m";
List<Member> resultList = em.createQuery(query, Member.class).getResultList();
for (Member member : resultList) {
System.out.println("member = " + member.getUsername() + ", " +
member.getTeam().getName());
}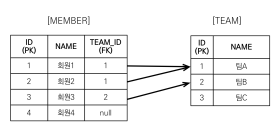
예를 들어보자
팀A와 팀B가 있고
멤버1, 2 는 팀A 소속/ 멤버3은 팀B 소속이다.
sout에 member.getUsername() 즉 멤버만 조회한다고 가정을 하면 3개의 쿼리만 날라간다. (LAZY 로딩)
이제 멤버도 가져와 보자
멤버1의 팀을 가져오는 쿼리를 날려준다.
멤버2도 마찬가진데, 쿼리가 실행되면 팀A는 1차캐시에 이미 있으니 바로 가져온다.
멤버3은 팀B 소속이라서 쿼리를 날려야 한다.
이렇게 되면 회원 수와 멤버수가 많이질수록 쿼리가 정말 많이 증가하게 된다.
자 그럼 페치조인 맛을 봐보도록 하자.
String query = "select m from Member m join fetch m.team";기본적인 문법이고, 회원과 팀을 함께 조회한다.
또한 team을 한꺼번에 조회하기 때문에 프록시가 아닌 실제 객체이다.
어? 그럼 즉시로딩이랑 비슷한 거 같은데?
즉시로딩과 페치조인의 차이점
정리하자면 즉시로딩과 페치조인의 차이점은 n+1이 되냐 안되냐가 가장 큰 거 같다. (실행 쿼리도 다른듯?)
컬렉션 페치 조인
일대다 관계 페치조인 중
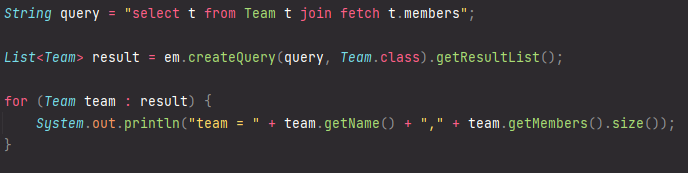
위에서 예를 들었던 상황과 같다고 가정하자.(팀2 멤버3)
이렇게 하면 출력은 2줄이 될 거 같지만 결과는 세 줄이 나온다.
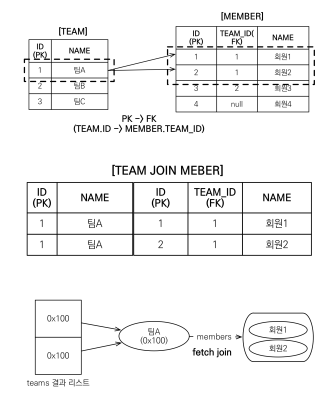
숙지!!!!!!!!!
select m from Member m join m.team
맴버에관한 쿼리 1번, 팀에대한 쿼리 2번
이런경우가 N+1 이고 데이터 뻥튀기는 없다.
1대다 데이터 뻥튀기!!!!!!!!! 다대1은 뻥튀기가 안된다!
select t from Team t join t.members
팀에관한 쿼리 1번, 맴버의 이름 2번
이런경우가 N+1 이고 데이터 뻥튀기가 있다.
이렇게 중복되는 것을 막기위해서는 DISTINCT를 사용하면 된다!
SQL의 DISTINCT는 중복된 결과를 제거하는 명령
- JPQL의 DISTINCT 2가지 기능 제공
• 1. SQL에 DISTINCT를 추가
• 2. 애플리케이션에서 엔티티 중복 제거
String query = "select distinct t from Team t join fetch t.members";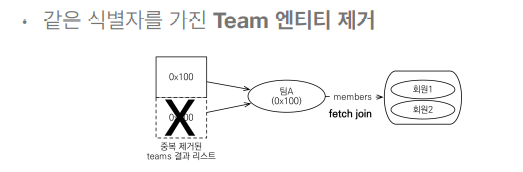
페치 조인의 특징과 한계
- 페치 조인 대상에는 별칭을 줄 수 없다.
페치조인은 기본적으로 연관된 엔티티를 다 가져오는 것인데, 부분적으로 조작하는 것은 위험하다. 하이버네이트는 가능, 가급적 사용X- 둘 이상의 컬렉션은 페치 조인 할 수 없다.
1:N도 데이터 뻥튀기가 되는데 둘 이상의 컬렉션이 페치 조인된다면 데이터가 늘어나면서 문제가 발생할 수 있다.- 컬렉션을 페치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없다.
1:1이나 N:1같은 단일 값 연관 필드들은 Fetch Join도 페이징이 가능하다.
그런데 1:N에서는 페이징이 불가능하다.
잘 생각해보면 알 수 있는데 만약 한 팀에 2명의 멤버가 있다고 가정해보자.
페이징이 가능하다면, 페이지에서 조회할 수 있는 데이터를 1개로 설정(setFristResult(), setMaxResults())하면 한 팀에 1명의 멤버만 조회가 될 것이다.
이는 논리적으로 맞지 않는다.
1:N에서 페이징 API를 사용할 수 있기는 한데, 하이버네이트에서 경고 로그를 남기고 메모리에서 페이징을 하는데 매우 위험할 수 있다.
그럼 어떻게 해결할까? 이를 해결하는 방법은 의외로 간단하다.
그냥 뒤집으면 된다.
select m from Member m fetch join Team
위와 같은 방식으로 뒤집어서 조회를 하면 다대일이 되므로 페이징 API를 사용할 수 있을 것이다.
다른 방법으로는 @BatchSize 애노테이션이다. 먼저 쿼리를 바꿔준다.
select t from Team t
이 배치 사이즈는 1:N 관계일 때 엔티티를 최초 사용 시점에 DB에서 N에 해당하는 엔티티를 몇 개 만큼 가져올지 정의하는 옵션이다.
hibernate.default_batch_fetch_size으로도 설정이 가능하며 컬렉션 멤버 (@OneToMany)에 @BatchSize 애노테이션으로도 그 값을 정의할 수도 있다.
출처- 일대일, 다대일 같은 단일 값 연관 필드들은 페치 조인해도 페이징 가능
- 하이버네이트는 경고 로그를 남기고 메모리에서 페이징(매우 위험
나머지 다형성 쿼리, 엔티티 직접사용, Named쿼리, 벌크 연산은 필요할 때 듣도록 하자!! 빠른 시일 내에