이번 포스팅은 매핑과 연관관계에 대해서 정리해 보려고 한다.
@Entity - JPA를 사용해서 테이블과 매핑할 클래스에 붙여준다.
- 기본 생성자는 필수다.(public, protected)
- final클래스, enum, interface, inner 클래스는 사용할 수 없다.
@Table - 매핑할 테이블 이름
ex) @Table(name = "CAT") 해주면 DB 테이블 이름이 바뀐다.
ddl-auto 옵션
<property name="hibernate.hbm2ddl.auto" value="create" />
value = ??? 에 무엇을 넣냐에 따라 달라진다.
- if 컬럼을 삭제한 후 update를 해도 달라지지 않는다.
주의할 점
- 운영 장비에서는 절대 crate, create-drop, update 사용하면 안된다.
- 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
여러 애노테이션
@Column - 객체 필드를 테이블의 컬럼에 매핑시켜주는 애노테이션이다.
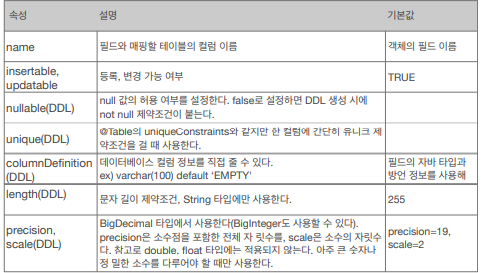
ex) @Column(unique = true, nullable = false, length = 10)@Enumerated - enum타입 매핑.
ex) @Enumerated(EnumType.STRING)
- EnumType.ORDINAL: enum 순서를 데이터베이스에 저장
- EnumType.STRING: enum 이름을 데이터베이스에 저장
ORDINAL 사용은 지양하자. 순서가 바뀌거나 추가 되었을 때 곤란혀.
@Temporal - 날짜 타입 매핑.
ex) @Temporal(TemporalType.TIMESTAMP)TemporalType에는 3 가지가 있다.
DATE, TIME, TIMESTAMP 각각 날짜 시간 날짜시간 이다.
@Lob - BLOB, CLOB 매핑.
큰 컨텐츠를 사용하고 싶을 때 붙여주면 된다.
@Transient - 특정 필드를 매핑하지 않는다.
기본 키 매핑방법
@Id로 직접 할당한다.
자동할당은 @GeneratedValue 을 사용한다.
ex) @GeneratedValue(strategy = GenerationType.IDENTITY)IDENTITY
IDENTITY: 기본 키 생성을 데이터베이스에 위임, MYSQL
Id 값을 NULL로 하면 DB가 알아서 AUTO_INCREMENT 해준다.
이 친구만 특이하게 em.persist(); 를 하는 시점에 커밋을 해준다.
왜냐면 IDENTITY는 DB에 쿼리를 날려봐야 PK값을 알 수 있기 때문이다.
- 영속성 컨텍스트에 있으려면 PK값이 있어야 한다.
SEQUENCE
SEQUENCE: 데이터베이스 시퀀스 오브젝트 사용, ORACLE
@SequenceGenerator 를 추가적으로 선언해줘야 한다.
@SequenceGenerator(
name = "MEMBER_SEQ_GENERATOR",
sequenceName = "MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 50)(추가) 이렇게 해준 후
@GeneratedValue(strategy=GenerationType.SEQUENCE, generator = "MEMBER_SEQ_GENERATOR")@GeneratedValue 에서 generator 값을 @SequenceGenerator 의 name 값을 넣어준다.
name: 식별자 생성기 이름 (필수)
sequenceName: 데이터베이스에 등록되어 있는 시퀀스 이름 (기본값: hibernate_sequence)
initialValueDDL: 생성 시에만 사용됨. 시퀀스 DDL을 생성할 때 처음 시작하는 수를 지정 (기본값: 1)
allocationSize: 시퀀스 한 번 호출에 증가하는 수 (기본값: 50)
catalog, schema: 데이터 베이스 catalog, schema 이름
em.persist();persist를 한 번 한다고 가정하자.
initialValueDDL, allocationSize 값도 1, 50 이라고 가정하자.
그렇게 되면 call next value for MEMBER_SEQ 가 두 번 호출이 된다.
왜??
성능 최적화 때문이다.
50개씩 써야하는 데 1개밖에 안쓰니 문제가 있는 줄 알고 50 + 1 을 해준다.
em.persist(); // 1, 51
em.persist(); // MEMORY
em.persist(); // MEMORYTABLE
TABLE: 키 생성용 테이블 사용, 모든 DB에서 사용
name, value로 사용할 Column을 생성하여 DB Sequence를 흉내내는 전략이다
create table MY_SEQUENCES (
sequence_name varchar(255) not null,
next_val bigint,
primary key ( sequence_name )
)Key 생성용 테이블을 선언한 후 @TableCenerator 을 사용해 Entity를 매핑한다.
TableGenerator(
name = "MEMBER_SEQ_GENERATOR",
table = "MY_SEQUENCES",
pkColumnValue = “MEMBER_SEQ", allocationSize = 1)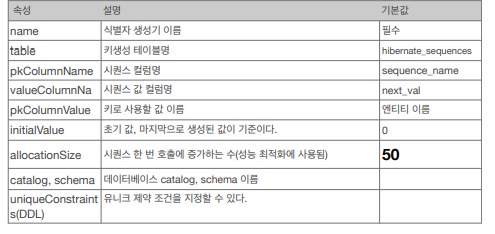
AUTO
AUTO: 방언에 따라 자동 지정, 기본값
연관관계
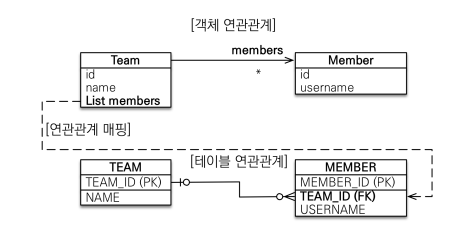
단방향 연관관계

public class Member
{
.
.
@ManyToOne
@JoinColumn(name="TEAM_ID")
private Team team;
.
.
}하나의 Team에 많은 Member들이 소속될 수 있으므로 1:N 관계이다.
연관관계 어노테이션을 써줄 때 항상 그 클래스 기준으로 써준다.
양방향 연관관계
public class Team
{
.
.
@OneToMany(mappedBy = "team");
private List<Member> members = new ArrayList<>();
}mappedBy = 뒤에는 연관관계가 맺어진 테이블에서 엮여있는 컬럼명을 써준다.
과제를 할 때 이상함을 느꼈지만 그냥 대수롭지 않게 여겼던 부분을 김영한님 강의에서 강조하셔서 참 신기했다.
양방향 연관관계를 맺으면 누가 주인일까?
Team으로 외래키를 관리할까 Member로 외래키를 관리할까??
그래서 주인을 정해야 한다.
양방향 매핑 규칙
- 객체의 두 관계중 하나를 연관관계의 주인으로 지정
- 연관관계의 주인만이 외래 키를 관리(등록, 수정)
- 주인은 mappedBy 속성 사용X
- 주인이 아닌쪽은 읽기만 가능
- 주인이 아니면 mappedBy 속성으로 주인 지정
주인은 외래키를 가지고 있는 곳으로 정한다.
즉 1:N 관계에서는 N이 주인이 되는 것이다.
Team과 Member로 예를 들어보자.
Member가 N 이고, 즉 Member가 주인이다.
실수 ex)
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
//역방향(주인이 아닌 방향)만 연관관계 설정
team.getMembers().add(member);
em.persist(member);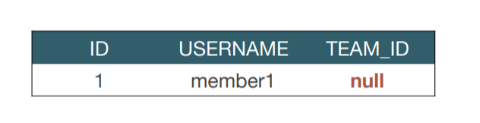
TeamId 에 Null이 들어간다.
왜? 주인이 아닌쪽은 읽기만 가능하기 때문이다.
정상 ex)
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
//team.getMembers().add(member); 써도되고 안써도 된다.
//연관관계의 주인에 값 설정
member.setTeam(team); //**
em.persist(member);정상적으로 데이터가 들어온다.
Member 안에 있는 team이 주인인데,
윗 코드는 역방향에 값을 넣어줘서 외래키에 null 값이 들어간다.
중요!!!!!!!
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setTeam(team);
//team.getMembers().add(member);
//em.flush();
//em.clear();
Team findTeam = em.find(Team.class, team.getId()); //1차 캐시
List<Member> members = findTeam.getMembers();
for (Member m : members) {
System.out.println("m = " + m.getUsername());
}Team findTeam = em.find(Team.class, team.getId());
→ .find()로 Team을 조회하면 1차 캐시에 저장된 Team 엔티티를 반환한다.
그 후 List<Member> members = findTeam.getMembers(); 를 해주면 아무것도 반환되지 않는다.
이유
team.getMembers().add(member); 얘가 없어서이다.
이 부분이 주석처리가 되어있어도 .commit() 을 호출하는 시점에는 데이터베이스에 정상적으로 반영이 되기 때문에 DB에 저장하는 것 자체는 문제가 없지만 저 시점에서 team.getMembers() 로 회원을 조회해오면 컬렉션에는 저장되어 있지 않아서 헷갈리고 실수를 하게 된다.
(항해 1타강사님 감사합니다)
그래서 넣어줄 때 헷갈리기 때문에 연관관계 편의 메소드 생성을 지향하자.
Member.java중 setter
public void setTeam(Team team){
this.team = team;
team.getMembers().add(this); //*********
}this 는 member 나 자신.
이렇게 되면 team.getMembers().add(member); 코드는 지울 수 있다.
!!이름은 의미있는 것으로 바꿔주는 것을 추천한다.
!!연관관계 편의 메소드가 양쪽에 다 있으면 toString() 호출시 계속해서 서로 호출하는 무한 루프 문제가 생길 수 있다
양방향 매핑 정리
- 먼저 단방향 매핑으로 연관관계 매핑을 끝낸다.
- 단방향 매핑을 잘 하고 양방향은 필요할 때 추가해도 된다.
(테이블에 영향을 주지 않음)
정리가 아직 많이 부족하고 내 머리에서도 뭔가 붕 뜬 느낌이다.
많이 해보고 또 공부를 해야할 것 같다.
다양한 연관관계 매핑
연관관계 매핑 시 고려해야하는 상황
- 다중성
- 단방향, 양방향
- 연관관계의 주인
N:1
위에서 간단히 다뤘다.
1:N
1이 주인이 되는 상황이다.
하지만 외래키는 MEMBER가 가지고 있다.
단점
- 엔티티가 관리하는 외래 키가 다른 테이블에 있다.
- Update Query가 한 번 더 나간다.
team.getMembers().add(member); 라고 했을 때
MEMBER에서 Update를 실행해야 되기 때문이다.- 테이블이 많아지면 운영이 힘들어진다.
1:1
주 테이블이나 대상 테이블 중 외래키를 선택해서 넣을 수 있다.
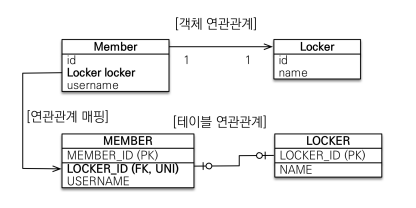
@OneToOne
@JoinColumn(name="LOCKED_ID")
public Locker locker;어노테이션은 @OneToOne 사용한다. 다대일이랑 비슷하다.
주 테이블에 외래 키
• 주 객체가 대상 객체의 참조를 가지는 것 처럼
주 테이블에 외래 키를 두고 대상 테이블을 찾음
• 객체지향 개발자 선호
• JPA 매핑 편리
• 장점: 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인 가능
• 단점: 값이 없으면 외래 키에 null 허용
대상 테이블에 외래 키
• 대상 테이블에 외래 키가 존재
• 전통적인 데이터베이스 개발자 선호
• 장점: 주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변경할 때 테이블 구조 유지
• 단점: 프록시 기능의 한계로 지연 로딩으로 설정해도 항상 즉시 로딩됨(프록시는 뒤에서 설명)
다대다[N:M]
관계형 DB는 테이블 2개로 다대다 관계를 표현할 수 없다.
따라서 중간에 연결을 해주는 연결 테이블을 추가해줘야 한다.
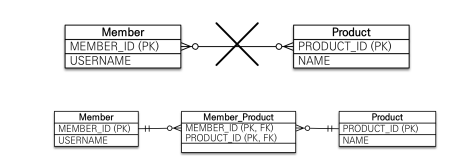
@ManyToMany
@JoinTable(name = "MEMBER_PRODUCT")
private List<Product>products = new ArrayList<>();이런식으로 @ManyToMany 와@JoinTable 어노테이션을 사용한다.
BUT 추가 정보를 넣는 것 자체가 불가능하고, 중간 테이블이 숨겨져 있기 때문에 예상하지 못하는 Query들이 나간다.
그래서 실무에서는 사용X
다대다 극복하는 방법
@ManyToMany => @OneToMany 와 @ManyToOne 로 변경

@Entitypublic class Member {
@OneToMany(mappedBy = "member")
private List<MemberProduct> memberProducts = new ArrayList<>();
.
.
}
Member.java
@Entitypublic class Product {
@OneToMany(mappedBy = "product")
private List<MemberProduct> members = new ArrayList<>();
.
.
}Product.java
그 다음 연결 테이블을(MemberProduct) 엔티티로 승격시킨다.
public class MemberProduct {
@Id
@GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "MEMBER_ID")
private Member member;
@ManyToOne
@JoinColumn(name = "PRODUCT_ID")
private Product product;
}
MemberProduct.java
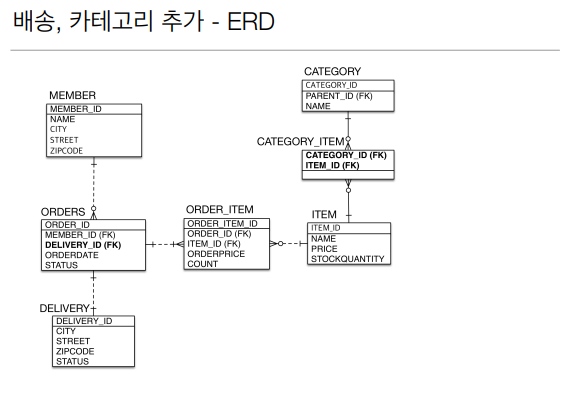
예시는 @ManyToMany 인데 이렇게 하면 안된다.
@ManyToMany
@JoinTable(name="CATEGORY_ITEM",
joinColumns = @JoinColumn(name="CATEGORY_ID"),
inverseJoinColumns = @JoinColumn(name = "ITEM_ID")
)
private List<Item>items = new ArrayList<>();Category.java
Item과 Catrgory간 연관관계 매핑 중,
@JoinTable 어노테이션은 중간 연결테이블을 만들어 주는 것이다.
joinColumns-> 내가 조인하는 것
inverseJoinColumns-> 반대쪽이 조인하는 것
@ManyToMany(mappedBy = "items")
private List<Category> categories = new ArrayList<>();Item.java
Order과 Delivery는 1대1 관계라서 양쪽에 @OneToOne 어노테이션을 사용하면 된다.
고급 매핑
상속관계 매핑
객체의 상속과 구조와 DB의 슈퍼타입 서브타입 관계를 매핑하는 것이다.
객체에는 상속 관계가 있지만 관계형 데이터베이스는 상속관계가 없다.
BUT 슈퍼타입, 서브타입 관계라는 모델링 기법이 객체 상속과 유사하다.
상속관계 매핑을 하는 방법(슈퍼타입 서브타입 논리 모델을 실제 물리 모델로 구현하는 방법)은 세 가지가 있다.
- 각각 테이블로 변환 -> 조인 전략
- 통합 테이블로 변환 -> 단일 테이블 전략
- 서브타입 테이블로 변환 -> 구현 클래스마다 테이블 전략
‼ 꼭 부모클래스는 추상 클래스로 만들어주자.
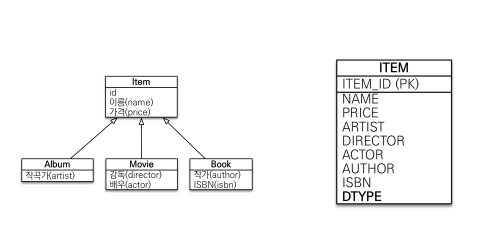
조인 전략
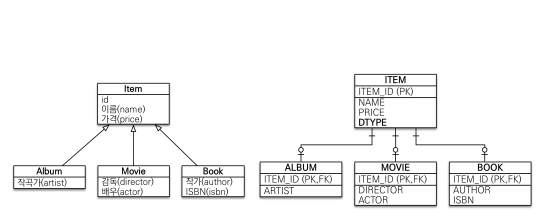
INSERT는 두 번 이루어진다.
JPA와 가장 유사한 모델이다.
DTYPE 이라는 구분하는 컬럼을 두고 ALBUM이면 ALBUM이랑 조인해서 가져온다.
사용법
@Inheritance(strategy = InheritanceType.JOINED)부모 클래스에 @Inheritance 붙여준 후
자식 클래스에 extends Item으로 Item을 상속받아 주면 된다.
Movie movie = new Movie();
movie.setDirector("aaaa");
movie.setActor("bbbb");
movie.setName("바람과 함께 사라지다.");
movie.setPrice(10000);
em.persist(movie);이 코드에 대한 실행 결과는
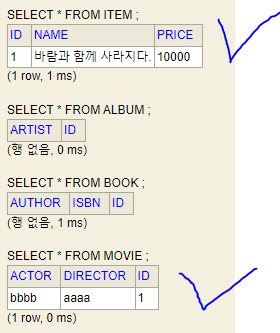
잘 들어가는 것을 볼 수 있다. 또한 조회를 할 때 자동으로 Join을 해준다.
또한 @DiscriminatorColumn 을 붙여주면

DTYPE에 Movie가 들어온 것을 볼 수 있다.
또한 DTYPE에 들어오는 이름을 자식 클래스의 이름이 아닌 설정을 해주고 싶다면 @DiscriminatorValue() 를 사용하면 된다.
em.flush();
em.clear();🧨영속성 컨텍스트에 있는 것들을 DB에 저장 후 깔끔히 제거한다. 1차캐시가 깨끗해진다.
전에 설명해주셨는데 이해가 잘 안된다.
왜 비워주고 해야되나??
(추가) 여기 를 보면 이해할 수 있다.
장점
• 테이블 정규화
• 외래 키 참조 무결성 제약조건 활용가능
• 저장공간 효율화
단점
• 조회시 조인을 많이 사용, 성능 저하
• 조회 쿼리가 복잡함
• 데이터 저장시 INSERT SQL 2번 호출
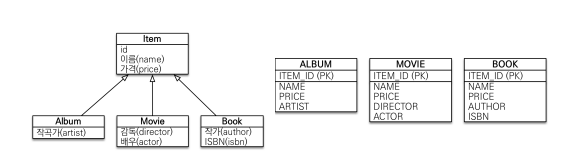
단일 테이블 전략
한 테이블로 합치는 것이다. 성능이 좋다.
사용법
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)부모 클래스에 @Inheritance 붙여준다.

짠!! 신기방구
또한 조인 전략에서는 DTYPE을 사용하기 위해 @DiscriminatorColumn 를 사용했었는데, 단일 테이블 전략에선 어노테이션을 생략해도 된다.
장점
• 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
• 조회 쿼리가 단순함
단점
• 자식 엔티티가 매핑한 컬럼은 모두 null 허용
• 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 상
황에 따라서 조회 성능이 오히려 느려질 수 있다
구현 클래스마다 테이블 전략
Item 테이블을 없애고 Item 속성들을 각각 다 넣어서 가지고 있는 것이다.(ex name, price)
사용법
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)부모 클래스에 @Inheritance 붙여준다.
@DiscriminatorColumn 이 친구는 이 전략에서는 필요가 없다.
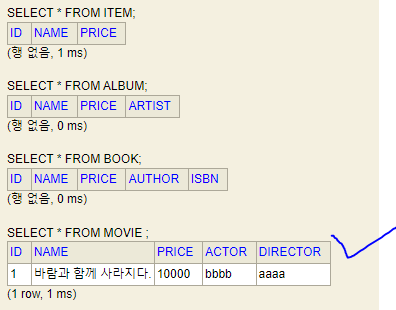
Item의 속성들이 다 들어간 모습이다.
장점
• 서브 타입을 명확하게 구분해서 처리할 때 효과적
• not null 제약조건 사용 가능
단점
• 여러 자식 테이블을 함께 조회할 때 성능이 느림(UNION SQL 필요)
• 자식 테이블을 통합해서 쿼리하기 어려움
@MappedSuperclass
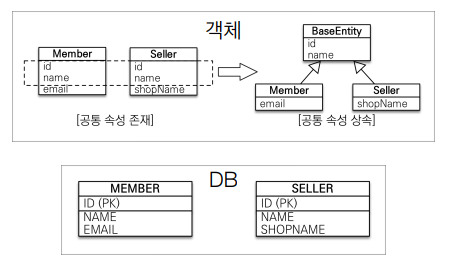
공통 매핑 정보가 필요할 때 사용한다.
ex) 속성을 각 DB마다 추가해야 하는데, 그 수고를 덜어주기 위해? 사용한다.
그림을 보면 이해가 쉽다!
사용법
@MappedSuperclass
public class BaseEntitiy {
private String createdBy;
private LocalDateTime createdDate;
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;
}@MappedSuperclass 얘 빼먹지 말자!!!!!!!
BaseEntity.class 를 만든 후 이 속성을 사용할 클래스들은 다 extends 해준다.
짚고 넘어가자
- 상속관계 매핑X
- 엔티티X, 테이블과 매핑X
- 부모 클래스를 상속 받는 자식 클래스에 매핑 정보만 제공
- 조회, 검색 불가(em.find(BaseEntity) 불가)
- 직접 생성해서 사용할 일이 없으므로 추상 클래스 권장
- 테이블과 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑
정보를 모으는 역할- 주로 등록일, 수정일, 등록자, 수정자 같은 전체 엔티티에서 공통
으로 적용하는 정보를 모을 때 사용- 참고: @Entity 클래스는 엔티티나 @MappedSuperclass로 지
정한 클래스만 상속 가능
실습?
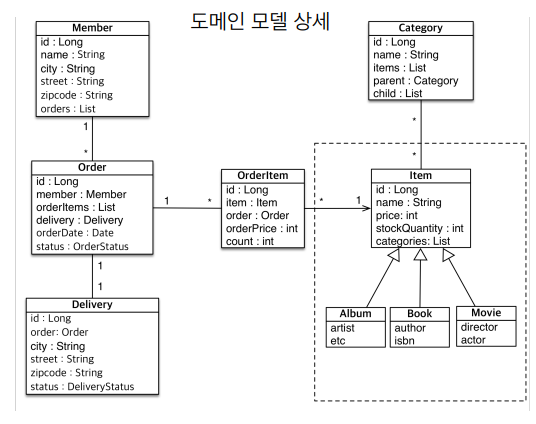
기존 도메인 모델에서 Item 쪽에만 추가가 되었고,
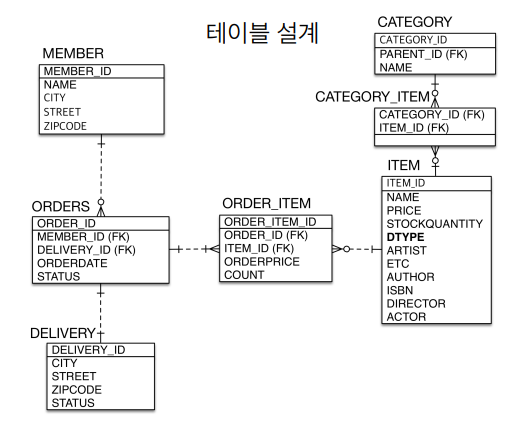
상속관계 전략은 단일 테이블 전략을 사용했다.
시작!!!!!
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn
public abstract class Item {Item.class 에 이 부분을 추가해준 후
Book book = new Book();
book.setName("Jpa");
book.setAuthor("김영한");
em.persist(book);값을 집어넣어 주면

짠!!!
BaseEntity 사용은 생략하겠다!
여기까지 강의를 듣고 느낀점은 공부할 게 너무너무너무 많고 어렵다는 것이다.
배움에 거부감이 없는 나는 열심히 도전할 것이다.
내일부턴 과제를 해야겠다.
최대한 빨리 끝낸 후 미니 프로젝트 시작 전에 ORM 표준 JPA 기본 강의를 다 들었으면 좋겠다. 파이팅 하자!!!!!!!!!!!!!!
