Compact Strings
- 자바 9부터 지원되기 시작한 String 객체의 새로운 저장 방식.
- char[]을 사용해 문자열을 저장하는 것이 아니라 byte[]을 저장하는 것이 특징이다.
왜 char[]을 사용하지 않고 byte[]를 사용할까?
- 기본적으로 자바의 char 자료형은 UTF-16 인코딩 방식을 사용하기 때문에 자료형의 크기가 2 byte다.
- 하지만 문자열 객체에서 사용되는 대부분의 문자들은 1 byte로 표현할 수 있는 Latin-1에 속하는 문자들인데 이런 문자들에 2 byte를 할당하는 것은 메모리 낭비다.
Latin-1이란?
- 국제표준화기구(ISO)에서 인정하는 8 비트 character set.
- alphabets of Western European languages를 표현함.
- ISO-8859-1이라고도 불리며 유닉스, 윈도우에서 사용된다.
- Extended ASCII라고도 불림.
- why?
- ASCII는 128가지 문자를 표현하는 7비트 인코딩.
- 출력 가능한 문자 94개(영문 52개, 숫자 10개, 특수 문자 32개) + 출력 불가능한 문자 33개.
- 7 bits는 정보를 표현, 마지막 1 bit는 오류 검출을 위한 parity bit.
String class의 내부
문자열 저장 방식
- char[] 배열을 사용하여 문자열을 저장하지 않고 byte[]을 사용해 저장.
- 문자열의 모든 문자가 Latin-1으로 표현 가능하다면 문자 하나 당 1 byte를 사용하여 저장.
- 문자열의 문자 중 하나라도 UTF-16로 표현해야 한다면 모든 문자는 문자 하나 당 2 byte를 사용하여 저장.
그럼 문자열 연산은 어떻게 이루어질까?
- 문자열 연산을 하기 위해서는 문자열 객체가 Latin-1로 표현된 문자열인지 UTF-16으로 표현된 문자열인지 구분할 필요가 있다.
- 내부적으로 coder라는 변수를 두어 Latin-1로 표현된 문자열이면 0, UTF-16으로 표현된 문자열이면 1을 할당한다.
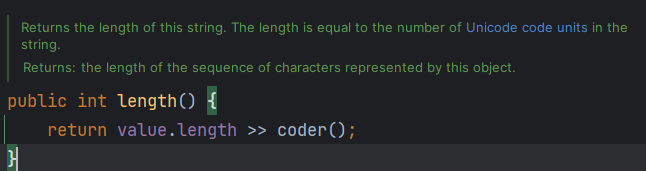
- 많은 문자열 연산은 문자열 객체의 coder 값에 따라 연산 방식이 나뉘어진다.
문제점
- 케이스에 따라 연산 방식이 나뉘어져 코드가 복잡해진다.
- 오버로드된 메소드들임에도 불구하고 한 메소드는 내장 함수를 호출하는가 하면 다른 메소드는 내장 함수를 호출하지 않아 코드가 직관적이지 못하다.
참고
