4. 스프링과 문제 해결 - 트랜잭션
문제점들
-
순수한 서비스 계층
- 웹 애플리케이션은 보통 컨트롤러, 서비스, 리포지토리 계층으로 나뉜다.
- 컨트롤러
- UI 관련 처리 담당
- 요청, 응답 담당
- 요청으로부터 들어오는 데이터 검증
- 서비스
- 비즈니스 로직 담당
- 리포지토리
- DB 접근 담당
- 컨트롤러
- 왜 3가지 계층으로 나눌까?
- 서비스 계층을 특정 기술로부터 격리시키기 위함이다.
- 컨트롤러, 리포지토리 계층은 다양한 기술을 사용할 수 있다.
- 컨트롤러 계층은 HTTP API, GRPC 등을 사용한다.
- 리포지토리 계층도 JDBC, MyBatis, JPA 등 많은 DB 접근 기술을 사용할 수 있다.
- 만약 계층을 분리하지 않으면 클라이언트 요청/응답 또는 DB 접근 시에 사용하는 기술이 바뀔 때마다 서비스 로직에 해당하는 코드까지 변경해야 하는 문제가 발생한다.
- 계층을 분리하면 컨트롤러, 리포지토리 계층에서 사용하는 기술이 바뀌어도 서비스 계층은 변경없이 유지할 수 있다.
- 컨트롤러, 리포지토리 계층은 다양한 기술을 사용할 수 있다.
- 서비스 계층을 특정 기술로부터 격리시키기 위함이다.
- 따라서 서비스 계층을 특정 기술에 의존하지 않도록 구현하는 것이 중요하다.
- 웹 애플리케이션은 보통 컨트롤러, 서비스, 리포지토리 계층으로 나뉜다.
-
JDBC를 이용해 트랜잭션을 사용할 때의 문제점
- JDBC 구현 기술이 서비스 계층에 누수
- 서비스 계층에서 트랜잭션을 처리하기 위해 JDBC의 트랜잭션 처리 코드에 의존하는 문제가 발생한다.
- 즉, 서비스 계층이 특정 기술의 트랜잭션 처리 코드에 의존한다.
- 서비스 계층이 순수하지 못하고 특정 기술에 의존하는 문제가 발생했다.
- OCP 위반
- 만약 DB 접근 기술을 JDBC에서 JPA로 변경하면 JDBC와 JPA의 트랜잭션 처리 방식이 다르기 때문에 트랜잭션 처리 코드를 전부 수정해야 한다.
- SRP 위반
- 서비스 계층이 비즈니스 로직, 트랜잭션 처리라는 2가지 책임을 가진다.
- 즉, 서비스 계층이 특정 기술의 트랜잭션 처리 코드에 의존한다.
- 서비스 계층에서 트랜잭션을 처리하기 위해 JDBC의 트랜잭션 처리 코드에 의존하는 문제가 발생한다.
- JDBC 구현 기술이 서비스 계층에 누수
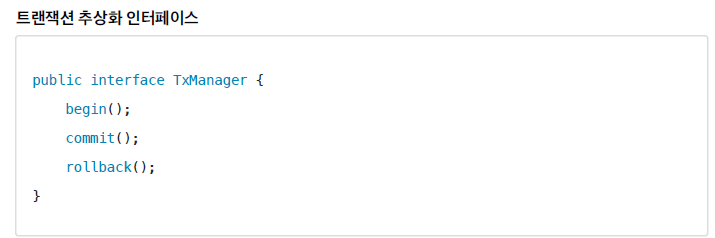
트랜잭션 추상화
- 서비스 계층이 특정 기술의 트랜잭션 처리 코드에 의존하는 것을 방지하려면 어떻게 해야 할까?
- 트랜잭션 기능을 추상화하면 된다.
-
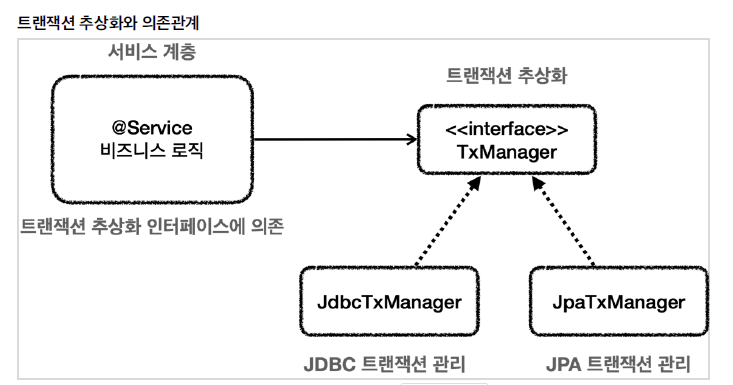
트랜잭션 처리 부분을 추상화하여 서비스 계층이 여기에 의존하도록 만들면 된다.
- DB 접근 기술이 JDBC이면 JDBC를 이용해 트랜잭션을 처리하는 구현체를 DI하고, JPA를 사용하면 JPA를 이용해 트랜잭션을 처리하는 구현체를 DI하면 된다.
-
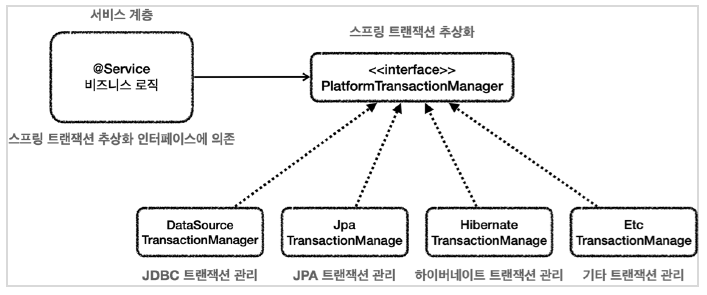
하지만 스프링은 이미 이런 트랜잭션 추상화 인터페이스와 트랜잭션 처리를 담당하는 구현체를 제공하고 있으므로 굳이 만들지 않아도 된다.
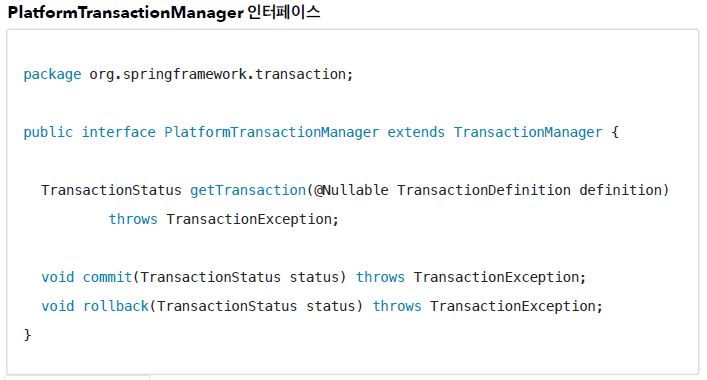
- getTransaction()
- 트랜잭션을 시작한다.
- commit()
- 커밋한다.
- rollback()
- 롤백한다.
트랜잭션 동기화
-
스프링 트랜잭션 매니저가 제공하는 기능은 2가지다.
- 트랜잭션 추상화
- 리소스 동기화
-
트랜잭션 추상화
- DB 접근 기술마다 트랜잭션을 처리하는 방식이 다른데 이를 인터페이스로 추상화하여 서비스 계층이 여기에 의존하도록 함으로써 특정 DB 기술의 트랜잭션 처리 코드에 의존하지 않도록 해준다.
-
리소스 동기화
- 트랜잭션 내의 쿼리들은 모두 같은 커넥션을 이용해 수행되어야 한다. 스프링 트랜잭션 매니저는 쓰레드 로컬(ThreadLocal)을 이용해 개발자가 같은 커넥션을 유지하는 것을 신경쓰지 않도록 해준다.
-
트랜잭션 매니저와 트랜잭션 동기화 매니저
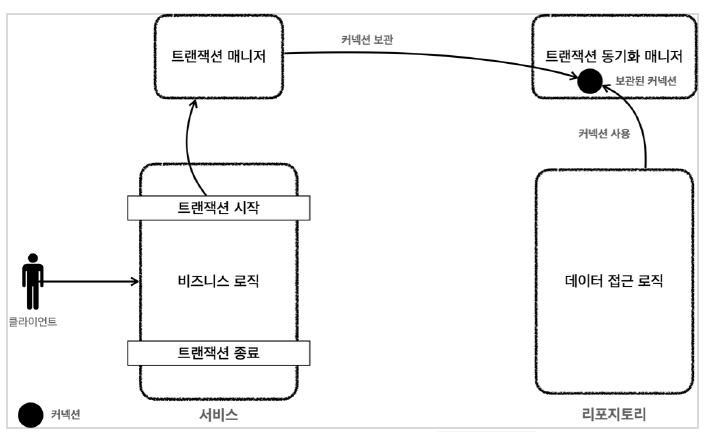
-
트랜잭션 동기화 매니저
- 트랜잭션 매니저는 내부적으로 트랜잭션 동기화 매니저를 이용해 커넥션 동기화를 수행한다.
- 트랜잭션 동기화 매니저는 쓰레드 로컬(ThreadLocal)을 이용해 멀티 쓰레드 환경에서 안전하게 커넥션을 수행한다.
- 쓰레드가 같다면 서비스 계층과 리포지토리 계층에서 같은 커넥션 객체에 접근할 수 있다.
-
동작 방식
- 트랜잭션을 시작하기 위해서는 커넥션 객체가 필요하다. 트랜잭션 매니저는 데이터 소스로부터 커넥션 객체를 가져온다.
- 가져온 커넥션 객체를 트랜잭션 동기화 매니저에 보관한다.
- 쓰레드 로컬을 사용하기 때문에 쓰레드 별로 별도의 저장소가 할당이 된다.
- 리포지토리 계층에서 트랜잭션 동기화 매니저에 보관된 커넥션 객체를 꺼내서 사용한다.
- 트랜잭션이 종료되면 트랜잭션 매니저는 트랜잭션 동기화 매니저에 보관된 커넥션 객체를 가져와 트랜잭션을 종료하고, 커넥션도 종료한다.
-
트랜잭션 매니저를 사용하면 커넥션 동기화 작업을 해주어 코드가 깔끔해진다.
- 트랜잭션 매니저를 사용하지 않을 때는 커넥션 객체를 리포지토리 계층의 메소드 인자로 넘겨주면서 직접 동기화를 하느라 코드가 지저분해졌다.
