kafka, zookeeper 클러스터
1
kafka 기본 설정
1.카프카란
- 데이터 파이프 라인에서 메시지의 발생과 구독을 담당하는 서버
- 데이터 : 메시지
- 메트릭, 로그, 추적메시지
- 토픽: 메시지 분류 단위, 파티션 : 분류된 메시지 뭉치 , 배치: 파티션 크기
- 카프카 설치
- 순서
- 자바 설치 -> 주키퍼 설치 -> 카프카 브로커 설치(https://kafka.apache.org/) -> 브로커 옵션 조정 - 카프카 브로커 옵션
- broker.id
- 클러스터 내의 브로커의 고유한 식별자, - port :
- tcp port번호 기본값 9092 - zookeeper.connect
- 주키퍼의 위치, 기본값 localhost:2181 - log.dirs :
- 로그 디렉토리 - num.recovery.threads.per.data.dir
- 로그 디렉토리 마다의 스레드 수, 해당 옵션 × 로그 디렉토리 : 전체 스레드 수 - auto.create.topics.enable
- 토픽 자동생성, 직접 토픽생성을 관리하기위한다면 false로 설정, 기본값 ture - num.partition
- 토픽당 파티션 수, 적절한 파티션 수 선정 방법 추가 - log.retention.ms(minutes, hour, bytes)
- 로그를 얼마나 보존할 것인지, 작은 단위의 옵션으로 적용됨 - log.segment.bytes(ms)
- message.max.bytes
- 메시지 최대 크기
- broker.id
kafka, zookeeper 설치
- https://downloads.apache.org/kafka 에서 맞는 버전의 다운로드 링크를 가져와 설치
% wget https://downloads.apache.org/kafka/2.8.1/kafka_2.12-2.8.1.tgz
% tar -xvzf kafka_2.12-2.8.1.tgz
- 3개의 노드 실행을 위한 디텍토리 복사
% cp -r kafka_2.12-2.8.1 kafka_1
% cp -r kafka_2.12-2.8.1 kafka_2
% cp -r kafka_2.12-2.8.1 kafka_3- 카프카 인스턴스들의 로그 저장용 폴더 생성
% mkdir logs_1
% mkdir logs_2
% mkdir logs_3- 주키퍼 data 폴더 생성
% mkdir data
% cd data
% mkdir zookeeper_1
% mkdir zookeeper_2
% mkdir zookeeper_3- 주키퍼 고유 id 설정, myid에 담긴 정수값을 고유 id로 갖는다.
% echo 1 > zookeeper_1/myid
% echo 2 > zookeeper_2/myid
% echo 3 > zookeeper_3/myidKafka, zookeeper 첫 세팅
- ~/kafka_1/config 의 zookeeper.properties 파일 수정
~
dataDir=/Users/publicai/kafka/data/zookeeper_1
~
clientPort=2181
~
# admin.serverPort=8080
tickTime=2000
initLimit=5
syncLimit=2
server.1=localhost:2666:3666
server.2=localhost:2667:3667
server.3=localhost:2668:3668- kafka_2, 3의 경우
- clientPort=2182, 2183 으로
- ~/kafka/data/zookeeper_2, 3으로 설정
- 해당 방식은 개별 서버를 흉내내는 방식이라 실제 여러대의 서버에서 사용한다면 localhost 대신 해당 서버의 ip 주소를 넣어주면된다
- server.properties 파일 수정
# The id of the broker. This must be set to a unique integer for each broker. broker.id=1 .. ############################# Socket Server Settings ############################# listeners=PLAINTEXT://localhost:9092 ... ############################# Log Basics ############################# log.dirs=/Users/publicai/kafka/logs_1 ... ############################# Zookeeper ############################# zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
- kafka_2,3의 경우
- broker.id=2, 3으로
- listeners=PLAINTEXT://localhost:9093, 4로
- log.dirs=/Users/publicai/kafka/logs_2, 3으로
카프카 주피터 클러스터 실행
- 총 6개의 터미널 창에서 진행 (추후 도커 등을 활용하는 방향으로)
- 3개의 주키퍼 먼저 실행하고 주키퍼가 서로를 인식하고 선도자를 뽑는다.
- 나머지 터미널에서 카프카를 실행하고 토픽과 생산자, 소비자를 생성하여 메시지가 잘 전송되는지 확인
-- 주키퍼 실행
bin/zookeeper-server-start.sh config/zookeeper.properties
-- kafka 실행
bin/kafka-server-start.sh config/server.properties -
주피터 터미널 3개

-
kafka 터미널 3개
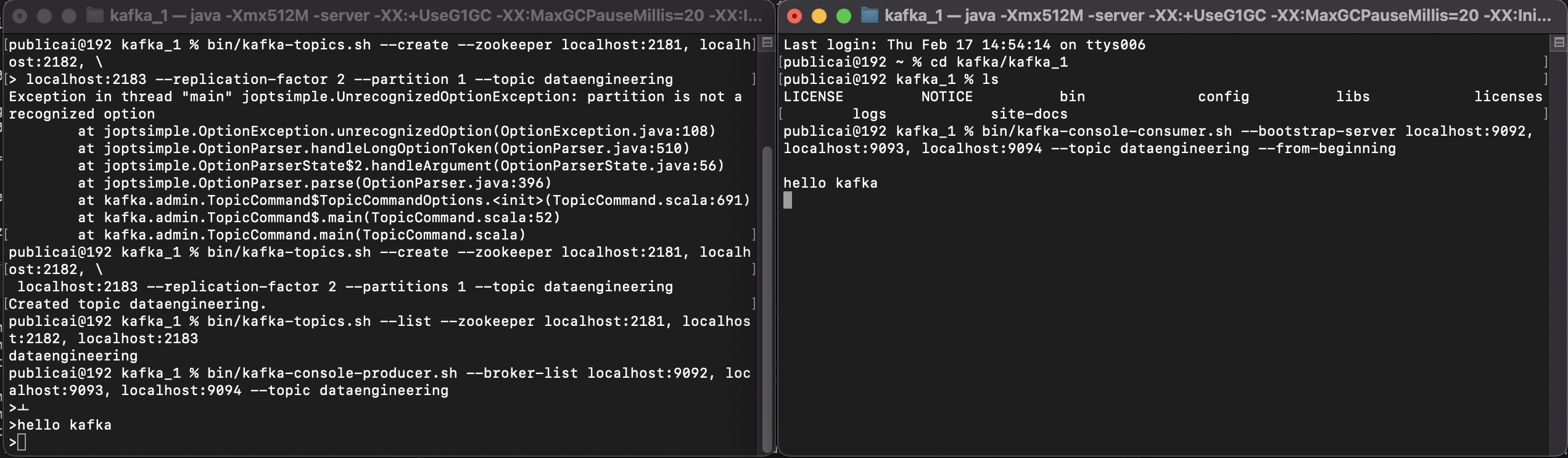
- topic 생성
% bin/kafka-topics.sh --create --zookeeper localhost:2181, localhost:2182, \
localhost:2183 --replication-factor 2 --partitions 1 --topic dataengineering아래 메시지가 뜨면 토픽 생성 완료

- topic 리스트 확인 명령어
bin/kafka-topics.sh --list --zookeeper localhost:2181, localhost:2182, localhost:2183생산자와 소비자로 메시지 전송 해보기
생산자 생성
bin/kafka-console-producer.sh --broker-list localhost:9092, localhost:9093, localhost:9094 --topic dataengineering- --broker-list : 카프카 클러스터 서버 주소
- --topic : 토픽 이름
소비자 생성
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092, localhost:9093, localhost:9094 --topic dataengineering --from-beginning- --bootstrap-server : 카프카 클러스터 서버 주소
- --topic : 토픽 이름
- --from-beginning : 토픽의 메시지를 모두 읽어온다는 설정
생산자 : 왼쪽, 소비자 : 오른쪽

가끔 기록하는 velog