
지난시간에 이어서 오늘도 한번 Oracle 실습을 진행해보도록 하겠다.
// 학생 테이블
// 학번, 이름, 강의실, 국어, 영어, 수학, 등록일자
CREATE TABLE student (
no NUMBER PRIMARY KEY, // 기본키
name VARCHAR2(20),
classroom CHAR(1),
kor NUMBER(3),
eng NUMBER(3),
math NUMBER (3),
regdate TIMESTAMP DEFAULT CURRENT_DATE
);위와 같이 학생 테이블에 들어갈 항목들과 길이를 지정해주도록 한다.
생성한 이후 STUDENT 테이블을 우클릭하여 편집을 누르면
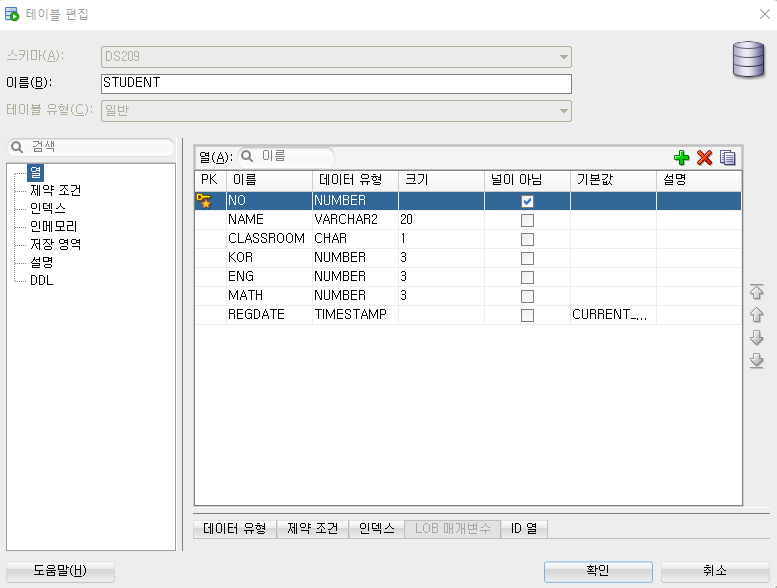
잘 생성된것을 확인 할 수 있다.
이번 테이블의 경우 이름이 아니라 'no'라는 항목을 만들어 따로 기본키로 지정해주었다.

따로 지정해주지 않아 아무 값이나 입력된 모습이다.
(현재 실습은 실제 학생 데이터와 연관없는 아무 값이나 넣고 있기에 따로 가리지 않았다.)
// 학생 시퀀스 만들기
CREATE SEQUENCE seq_student_no START WITH 1 INCREMENT BY 1 NOMAXVALUE NOCACHE;
// 학생정보 입력
INSERT INTO student(no, name, classroom, kor, eng, math)
VALUES(seq_student_no.NEXTVAL, '이름', 'A', 40, 50, 60);
INSERT INTO student(no, name, classroom, kor, eng, math)
VALUES(seq_student_no.NEXTVAL, '이름2', 'B', 40, 50, 60);
INSERT INTO student(no, name, classroom, kor, eng, math)
VALUES(seq_student_no.NEXTVAL, '이름3', 'C', 40, 50, 60);
INSERT INTO student(no, name, classroom, kor, eng, math)
VALUES(seq_student_no.NEXTVAL, '이름4', 'D', 40, 50, 60);
INSERT INTO student(no, name, classroom, kor, eng, math)
VALUES(seq_student_no.NEXTVAL, '이름5', 'E', 40, 50, 60);
COMMIT;이후 학생 정보를 넣어주도록 하자.
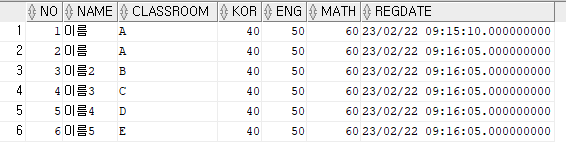
잘 들어갔다.
이번에는 학생들이 들어갈 강의실을 만들어 보자.
// 강의실 테이블 생성
CREATE TABLE classroomtbl (
code CHAR(1) PRIMARY KEY, -- 기본키는 code, 코드값은 지정하지 않음
room VARCHAR2(10),
teachar VARCHAR2(20),
regdate TIMESTAMP DEFAULT CURRENT_DATE
);똑같이 강의실 정보를 한번 넣어보도록 하자.
이번에는 넣는 방법을 두가지 알아보도록 하겠다.
// java의 auto 커밋은 데이터를 하나하나COMMIT 하다가 중간에서 꺼지게 되면 이전에 넣었던 데이터들을 다시 ROLLBACK해야함.
// (이후에 오류때문에 데이터가 들어가지 않을 수 있기 때문)
// 3개 추가후 마지막에 COMMIT
INSERT INTO classroomtbl(code, room, teachar)VALUES('F', '301호', '교사1');
INSERT INTO classroomtbl(code, room, teachar)VALUES('A', '302호', '교사2');
INSERT INTO classroomtbl(code, room, teachar)VALUES('Z', '303호', '교사3');
COMMIT;어제 Java 실습을 진행할 때 사용했던 MybatisContext의 경우에는 입력 정보를 하나 넣고 COMMIT을 하고, 또 하나를 넣고 COMMIT을 하는 형태였다.
하지만 만약 정보를 차례로 넣다가 중간에 컴퓨터가 꺼지거나 오류가 발생하기라도 하면 기존에 넣었던 데이터들을 모두 롤백하여 새로 처음부터 넣어야 할 수도 있다.
그렇기에 데이터가 한꺼번에 추가될 수 있도록 아래의 일괄추가 방법을 사용하는것이 최선이라고 할 수 있겠다.
// 3개 일괄적으로 추가한 후 COMMIT
INSERT ALL
INTO classroomtbl(code, room, teachar)VALUES('C', '301호', '교사4')
INTO classroomtbl(code, room, teachar)VALUES('D', '302호', '교사5')
INTO classroomtbl(code, room, teachar)VALUES('E', '303호', '교사6')
SELECT * FROM DUAL;굿굿
한번 조회해보도록 하겠다.
// 강의실 테이블 조회하기
SELECT c.* FROM classroomtbl c;
SELECT s.* FROM student s;조회방법은 위와 같으며, 따로 필터는 설정해놓지 않았다.
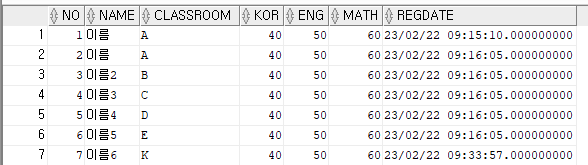
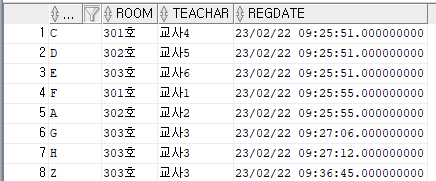
두 테이블에 데이터가 잘 들어간 모습이다.
그렇다면 이번엔 들어간 위의 자료들을 SELECT(확인) 하는 여러가지의 JOIN문법에 대해서 알아보도록 하겠다.
SQL JOINS
필터된 데이터들의 밴다이어그램
// 학생테이블, 강의실테이블의 교집합 자료만 나옴.(inner join 교집합)
// 모든 SQL에서 수행X
SELECT s.*, c.* FROM student s, classroomtbl c WHERE s.classroom = c.code;
// 모든 SQL 수행O, ANSI 표준
// 둘 다 동일한 문법임.
SELECT s.*, c.* FROM student s INNER JOIN classroomtbl c ON s.classroom = c.code;
INNER JOIN
위의 코드는 inner join을 설명하기 위한 코드이다.
결론적으로 두 코드는 같은 결과를 도출한다.
하지만 위의 코드와 달리 아래의 코드는 어떤 SQL도 수행시킬수 있는 표준 문법이라는 장점이 있다.

위의 결과이다. (학생강의실과 강의실코드가 일치하는 자료만)
// right outer join => classroom의 모든것 = student는 일치하는것 없으면 null로 처리
SELECT s.*, c.* FROM student s, classroomtbl c WHERE s.classroom(+) = c.code;
SELECT s.*, c.* FROM student s RIGHT OUTER JOIN classroomtbl c ON s.classroom = c.code; // ANSI 표준RIGHT OUTER JOIN
다음으로는 right outer join을 설명하기 위한 코드이다.
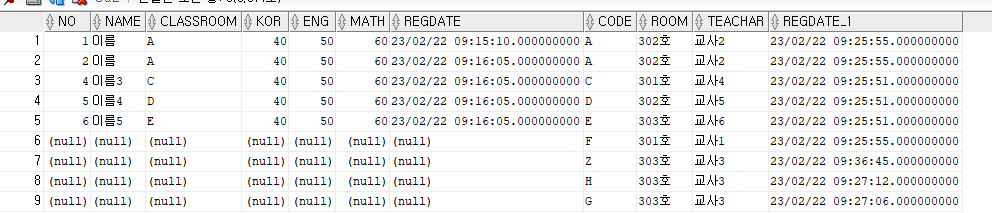
// left outer join => student의 모든것 = classroom은 일치하는것 없으면 null로 처리
SELECT s.*, c.* FROM student s, classroomtbl c WHERE s.classroom = c.code(+);
SELECT s.*, c.* FROM student s LEFT OUTER JOIN classroomtbl c ON s.classroom = c.code; // ANSI 표준LEFT OUTER JOIN
다음으로는 left outer join,
// full outer join => student의 모든것 = classroom은 일치하는것 없으면 null로 처리
SELECT s.*, c.* FROM student s, classroomtbl c WHERE s.classroom = c.code(+);
SELECT s.*, c.* FROM student s FULL OUTER JOIN classroomtbl c ON s.classroom = c.code; // ANSI 표준FULL OUTER JOIN
그리고 full outer join이 있다.
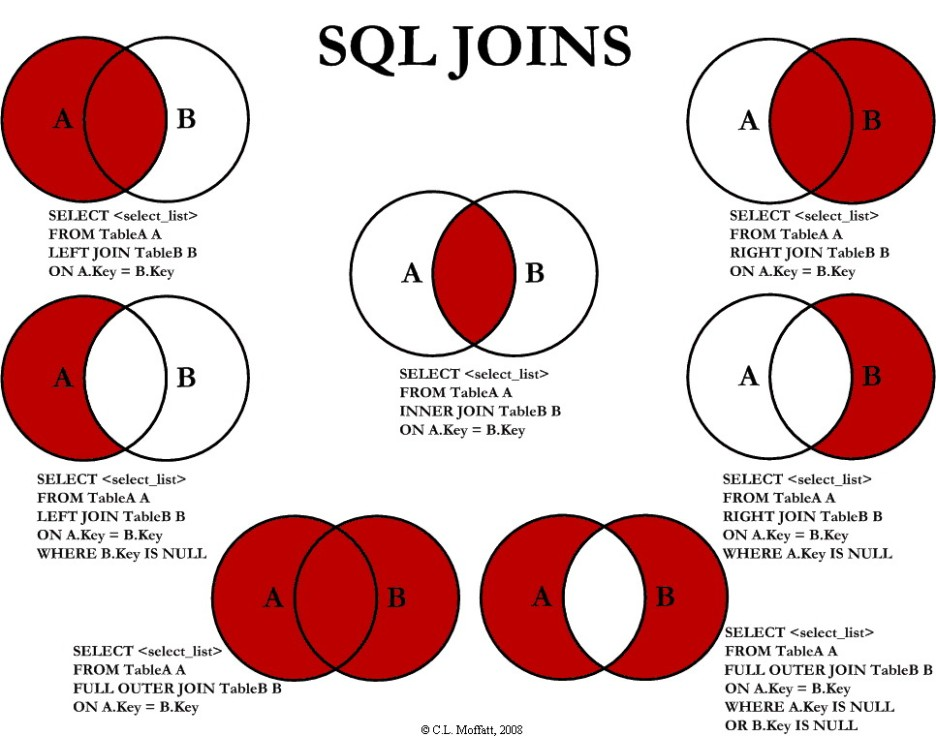
위의 그림은 방금의 과정들을 보기 쉽게 눈으로 표현한것이다.
출처
위를 바탕으로
위에서 생성해두었던 학생, 강의실 테이블을 황용하여
예제 문제를 한번 풀어보았다.
/* 문제1) CLASS가 A, B인것만 조회 */
SELECT sv.* FROM studentview sv WHERE classroom = 'A' OR classroom = 'B';
SELECT sv.* FROM studentview sv WHERE classroom IN('A','B');
//--------------------------------------------------------------------------------
/* 문제2) 교사 1, 교사3인것만 조회. '같지않다<>' */
SELECT sv.* FROM studentview sv WHERE classroom<>'교사1' AND classroom<>'교사3';
SELECT sv.* FROM studentview sv WHERE classroom NOT IN('교사1','교사3');
//--------------------------------------------------------------------------------
/* 문제3) total 컬럼이 마지막에 추가되어 점수합계 구하기, avg */
CREATE OR REPLACE VIEW studentview1 AS // studentview1이라는 값에다가 저장을 할 예정이다.
SELECT
sv.*, // sv(studentview)의 전체 파일
(sv.kor +sv.eng+sv.math) total, // 성적 점수총합 'total'이라는 항목으로 저장
ROUND((sv.kor + sv.eng + sv.math)/3,1 )avg, // 세 과목 성적 평균'avg'저장
case // if문과 동일
WHEN( ROUND((sv.kor + sv.eng + sv.math)/3 , 1) >=90 ) THEN 'a' // (ROUND (x, n) : x값의 소수점 n자리까지 도출)
WHEN( ROUND((sv.kor + sv.eng + sv.math)/3 , 1) >=80 ) THEN 'b'
WHEN( ROUND((sv.kor + sv.eng + sv.math)/3 , 1) >=70 ) THEN 'c'
else 'd'
END grade // grade라는 이름으로 'a','b','c' 값으로 데이터시트 마지막에 학력등급 추가
FROM
studentview sv; // 이 모든 자료는 studentview 에서 가져왔음.
//--------------------------------------------------------------------------------
// 자료 확인해보기
SELECT sv1.* FROM
studentview1 sv1;3번 문제를 푼 뒤
결과를 확인해보면
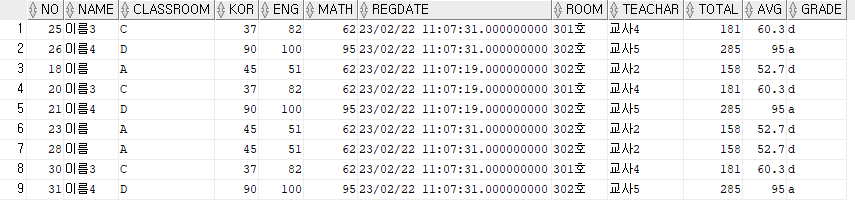
위와 같이 표의 뒷부분에 TOTAL, AVG, GRADE의 세가지 항목들이 적용이 됨을 알 수 있다.
(대부분의 등급이 a 아니면 d등급이다..)
위를 바탕으로 생성된 studentview1 을 가지고 또다른 예제를 풀어보도록 하자.
SELECT
sv1.grade,
MAX(sv1.total) max,
MIN(sv1.total) min,
SUM(sv1.total) sum,
AVG(sv1.total) avg,
COUNT(*) cnt
FROM
studentview1 sv1
GROUP BY
sv1.grade;위의 코드는 studentview1에서의 코드를 바탕으로
등급 abcd에 따른 토탈값의 최대, 최소, 합, 평균과 갯수를 나타내는 코드이다.
등급이 a,d등급뿐이기에 자료 종류는 두가지 뿐이다 ㅠㅠ
// 그룹수행후에 필터?? : HAVING
// 전체데이터에서 필터링을 먼저하고 그룹을 수행 : WHERE
SELECT // sv1 조회
sv1.classroom,
MAX(sv1.total) max,
MIN(sv1.total) min,
SUM(sv1.total) sum,
AVG(sv1.total) avg,
COUNT(*) cnt
FROM
studentview1 sv1
WHERE
sv1.kor>=70 // 국어점수 70점 이상 필터링
GROUP BY --sv1 에서
sv1.classroom
HAVING
COUNT (sv1.total) > 2;이번엔 강의실별로 각 값들을 도출하여
국어점수가 70점이상인 데이터만 필터링 후
다시 갯수가 2개 초과인 교실만 필터링해보도록 하겠다.

결과는 다음과 같다.
이번에는 회원, 물품, 구매 테이블을 view로 합쳐
강사님이 주시는 예제 문제들을 해결해보도록 하겠다.
SELECT m.* FROM member m; -- 회원
SELECT i.* FROM item i; -- 물품
SELECT p.* FROM purchase p; -- 구매
SELECT pv.* FROM purchaseview pv; -- 회원+물품+구매
// 문제1) 주문금액을 컬럼추가 (total)
SELECT pv.*, (price * cnt) total FROM purchaseview pv;
// 문제2) 남은 수량 컬럼추가 (quantitycnt)
CREATE OR REPLACE VIEW purchaseview1 AS
SELECT pv.*,
(price - cnt)total,
(quantity -cnt)quantitycnt
FROM purchaseview pv;
// 문제3) 연령대별 컬럼추가 (age) 0~9 => 0, 10~19 => 1, 20~29 => 2 .. 90~99=> 9
CREATE OR REPLACE VIEW purchaseview1 AS
SELECT
pv.*,
(price - cnt)total,
(quantity -cnt)quantitycnt,
FLOOR(userage/10) age
FROM
purchaseview pv;이렇게 3번문제까지 마치고 purchaseview1 뷰까지 생성을 완료하였다.
다음 예제로 넘어가보도록 하자.
SELECT pv.* FROM purchaseview pv; // 회원 + 물품 + 구매
SELECT pv1.* FROM purchaseview1 pv1; // 회원 + 물품 + 구매
// SELECT 통계함수() * FROM 테이블명 GROUP BY 그룹 조건
------------------------------
// 문제 1) 연령대별 주문수량 합계
SELECT
age, name, price, // ag는 위에서 설정해둔 연령대별 필터(10대20대...)
SUM(cnt) orderAgeCnt
FROM
purchaseview1
GROUP BY
age, name, price;
------------------------------------------------------------
// 문제 2) 상품별 주문수량
SELECT
code,
SUM(cnt) orderItemCnt
FROM
purchaseview1
GROUP BY
code;
------------------------------------------------------------
// 문제 3) 성별 주문수량, 주문금액합계
SELECT
usergender 성별,
SUM(cnt) 주문수량,
SUM(price * quantity) 주문금액합계
FROM
purchaseview1
GROUP BY
usergender;
------------------------------------------------------------
// 문제 4) 시간대별 주문수량 0시 1시 2시 23시
SELECT
TO_CHAR (pv1.regdate, 'HH24') hour,
SUM(pv1.cnt) orderTimeCnt
FROM
purchaseview1 pv1
GROUP BY
TO_CHAR (pv1.regdate, 'HH24');
------------------------------------------------------------
// 문제 5) 주문수량이 2개 이상인 주문의 연령대별 주문수량, 평균 구매금액
SELECT
pv1.userage,
SUM(pv1.cnt) orderAgeCnt,
AVG((pv1.price * pv1.cnt)/ pv1.age) avg
FROM
purchaseview1 pv1
WHERE
pv1.cnt>=2 // WHERE이랑 HAVING의 차이는 데이터를 그룹화 하기 이전과 이후로 나뉜다.
GROUP BY
pv1.userage;
------------------------------------------------------------
// 문제 6) 상품별 주문수량 개수가 3개 이상인 것
SELECT
pv1.code, pv1.name,
SUM(pv1.cnt) cnt
FROM
purchaseview1 pv1
WHERE
pv1.cnt>=3
GROUP BY
pv1.code, pv1.name;위와 같이 문제의 요구사항에 해당하는 값들을 불러올 수 있겠다.
안그래도 Java와 다르게 문법이 반대이기때문에 세로로 길게 정렬하다보니 이해가 잘 되지 않을 수 있는데,
아래의 구문 순서를 참고해서 개념을 다 잡도록 하자.
SELECT 구문의 순서
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> LIMIT
-
FROM : 어느 테이블을 대상으로 할 것인지를 먼저 결정 (어디서 데이터를 가져올것인지)
-
WHERE : 해당 테이블에서 특정 조건(들)을 만족하는 ROW들만 선별 (어떤 데이터만 선별할것인지)
-
GROUP BY : row 들을 그루핑 기준대로 그루핑, 하나의 그룹은 하나의 row로 표현됨 (어떤 기준으로 분류할건지)
-
HAVING : 그루핑 작업 후 생성된 여러 그룹들 중에서 특정 조건(들)을 만족하는 그룹들만 선별 (분류가 끝난 데이터를 어떻게 다시 분류할건지)
-
SELECT : 모든 컬럼 또는 특정 컬럼들을 조회. SELECT절에서 컬럼 이름에 alias(AS)를 붙인게 있다면 이 이후 단계(ORDER BY, LIMIT)부터는 해당 alias 사용 가능 (어떤 데이터를 표시할건지)
-
ORDER BY : 각 row를 특정 기준에 따라서 정렬 (어떻게 보기좋게 나열할건지)
-
LIMIT : 이전 단계까지 조회된 row들 중 일부 row들만들 추림 (어디까지만 조회할건지)
최대한 풀어서 써보았다.
예시를 하나 지정하여 직접 풀어서 설명해보도록 하겠다.
"purchaseview"에서 남성멤버"들의 "구매수량"을 "월별"로, "구매수량 오름차순 분류"
-- 1. 먼저 "어디서" 데이터를 가져올건지 정한다.
SELECT * FROM "purchaseview" ; // *은 전체를 뜻함. 세부사항은 아직 설정하지 않음.
-- 2. 다음으로 어떤 데이터만 "선별" 할건지 정한다.
SELECT * FROM purchaseview WHERE " usergender = 'M' ";
-- 3. 그다음으로, "기준"을 정한다.
SELECT * FROM purchaseview WHERE usergender = 'M' GROUP BY "TO_CHAR (regdate, 'MM')";
-- 4. 그리고 "표시할 데이터"를 입력해준다.
SELECT "TO_CHAR (regdate, 'MM') 월별, SUM(cnt), 구매수량"
FROM purchaseview WHERE usergender = 'M' GROUP BY TO_CHAR (regdate, 'MM');
-- 5.그리고 "나열할 방법"을 입력해준다.
SELECT TO_CHAR (regdate, 'MM') 월별, SUM(cnt) 구매수량
FROM purchaseview WHERE usergender = 'M' GROUP BY TO_CHAR (regdate, 'MM') "ORDER BY SUM(cnt) ASC";
-- 6. 최종코드
SELECT TO_CHAR (regdate, 'MM') 월별, SUM(cnt) 구매수량
FROM purchaseview WHERE usergender = 'M' GROUP BY TO_CHAR (regdate, 'MM') ORDER BY SUM(cnt) ASC;
이렇게 코드를 완성하였다.
이를 Oracle 에서 실행시켜보면..

오 성공적으로 작동이 된다!
(null)값은 내가 데이터를 입력할 때 날자값을 입력시키지 않아서 발생한 빈값이다.
어쨋든 정상적으로 작동함을 확인하였다.
이번에는 지난시간처럼 eclipse에서 코드를 작성하여
Oracle과 연동해보도록 하겠다.
package dto;
import java.util.Date;
import lombok.Data;
@Data
public class Purchase {
private long no;
private long cnt;
private long code;
private String userid;
private Date regdate;
}
먼저 dto 패키지에 구매 테이블과 똑같이 값을 넣을 수 있는 클래스를 만들어 준다.
package mapper;
import java.util.List;
import java.util.Map;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import dto.Purchase;
@Mapper
public interface PurchaseMapper {
// 주문하기
@Insert({ " INSERT INTO purchase ( no, cnt, code, userid ) ",
"VALUES( seq_menu_no.NEXTVAL, #{cnt}, #{code}, #{userid} )" })
public int insertPurchase(Purchase obj);
// 주문수량변경
@Update({ " UPDATE purchase SET cnt =#{cnt} ", " WHERE no =#{no} " })
public int updatePurchase(Purchase obj);
// 아이디별 주문목록조회 purchase 테이블에서 조회
@Select({ " SELECT * FROM purchase ", " WHERE userid =#{userid} ORDER BY no ASC" })
public List<Purchase> selectPurchaseList(String userid);
// 해당아이디별 주문목록조회 purchaseView에서 조회
@Select({ " SELECT * FROM purchaseview ", " WHERE userid =#{userid} ORDER BY no ASC " })
public List<Map<String, Object>> selectPurchaseViewList(String userid);
// 입력값이 존재할때만 =#{}를 사용!
// ----------------------아래 5개 항목 실습 완료--------------------(메인 실행)
// 성별에 따른 구매수량 조회
@Select({ " SELECT SUM(cnt), usergender FROM purchaseview GROUP BY usergender " })
public List<Map<String, Object>> selectGenderViewList();
// 고객별 구매수량, 총 구매금액 조회
@Select({ " SELECT SUM(cnt), SUM(price*cnt), userid FROM purchaseview GROUP BY userid " })
public List<Map<String, Object>> selectPurchaseViewGroupByUserid();
// 물품별 구매수량, 구매횟수, 총 구매금액 조회
@Select({ " SELECT SUM(cnt), COUNT(*), SUM(price*cnt), code FROM purchaseview GROUP BY code " })
public List<Map<String, Object>> selectPurchaseViewGroupByCode();
// 월별 구매수량 조회
@Select({ " SELECT TO_CHAR (regdate, 'MM'), SUM(cnt) FROM purchaseview GROUP BY TO_CHAR (regdate, 'MM')" })
public List<Map<String, Object>> selectPurchaseViewGroupByMonth();
}
다음으로, 구매 Mapper를 인터페이스로 만들어
작동시키고자 하는 기능들을 코드로 작성해준다.
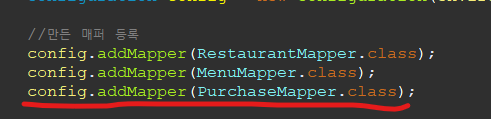
이렇게 만들어진 Mapper를 MybatisContext에 추가해주도록 하자.
이제 메인에서 한번씩 실행해볼 차례다!
package main;
import dto.Purchase;
import java.util.Date;
import java.util.List;
import java.util.Map;
import connection.MyBatisContext;
import mapper.MenuMapper;
import mapper.PurchaseMapper;
import mapper.RestaurantMapper;
public class Main {
public static void main(String[] args) {
PurchaseMapper pMapper = MyBatisContext.getSqlSession().getMapper(PurchaseMapper.class);
// --------------------------------------구매 - 성별로 주문목록 조회 (map)
List<Map<String, Object>> list = pMapper.selectGenderViewList();
for(Map<String, Object> map : list) {
System.out.println(map.toString());
}
// --------------------------------------구매 - 고객별 구매수량, 총구매금액 조회 (map)
List<Map<String, Object>> list = pMapper.selectPurchaseViewGroupByUserid();
for(Map<String, Object> map : list) {
System.out.println(map.toString());
}
// --------------------------------------물품별 구매수량, 구매횟수, 총 구매금액 조회 (map)
List<Map<String, Object>> list = pMapper.selectPurchaseViewGroupByCode();
for (Map<String, Object> map : list) {
System.out.println(map.toString());
}
// --------------------------------------월별 구매수량조회 (map)
List<Map<String, Object>> list = pMapper.selectPurchaseViewGroupByMonth();
for (Map<String, Object> map : list) {
System.out.println(map.toString());
}
}
}위에서부터 하나씩 작동시켜보도록 하겠다.




마지막친구같은 경우에는 위에서 본것처럼
날짜를 지정해주지 않아 null로 잡혀서 뜨지 않는 경우이다
