EKS를 사용할때 가장 먼저 작업하는것이 이 노드 그룹을 만드는 것이다
그러나 매번 새로운 서비스를 런칭할 때 마다 노드 그룹을 새로 만들거나
서비스의 리소스를 고려하지 못한 채 서버가 만들어져 문제가 생기면 서버를 수동으로 확장해야 한다
어느정도 AWS내에 있는 ASG는 이를 완벽히 대체할 수 없었고
찾아보던 중 amazon에서 개발한 karpenter가 있어 이를 적용한 방식과 성능을 이야기 하고자 한다
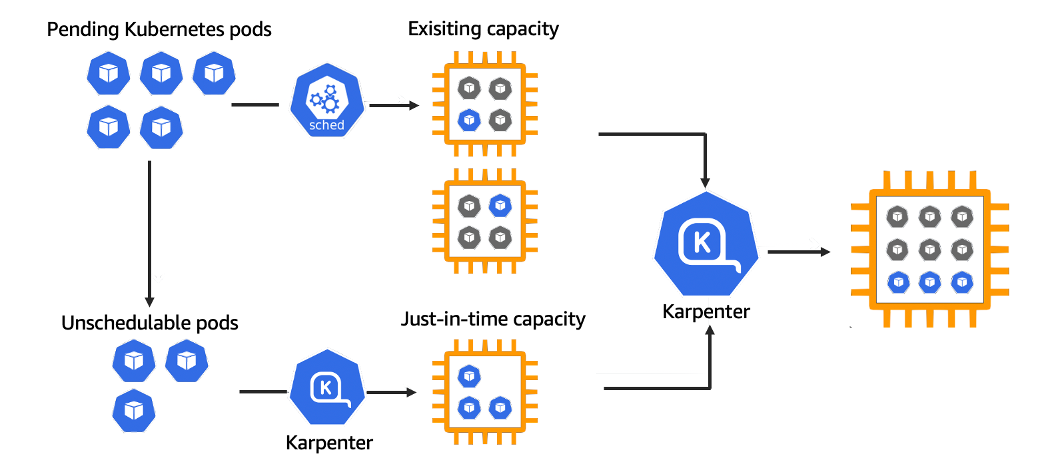
karpenter의 기본 동작 원리
https://aws.amazon.com/ko/blogs/aws/introducing-karpenter-an-open-source-high-performance-kubernetes-cluster-autoscaler/
우선 Karpenter의 기본 동작 원리는 매우 간단하다
-
pod가 생성되었을 때 조건에 맞는 노드(서버)가 없어 pending 상태에 놓이면 karpenter가 감지해 원하는 조건을 확인해 서버를 늘려준다
-
pod가 제거 될 때 리소스를 측정해 노드(서버)에 남아있는 리소스를 체크한 후 노드 타입 혹은 개수를 줄이고 pod를 재배치 해준다
다른 ASG는 한개의 노드에 pod를 몰아넣고 노드(서버)의 리소스가 부족하면 다른 노드가 생성되어 특정 노드는 리소스가 남을 수 있지만
karpenter는 pod의 리소스를 확인해 여러 노드에 서비스가 골고루 분포함과 동시에 한개의 pod만 내려갔다 올라갔다 해도 분주하게 리소스 손실 없이 바꾸려 한다
https://github.com/aws/karpenter-provider-aws/tree/main/charts/karpenter
설정 또한 간단하다
공식 github에 helm chart를 제공해주고 있으며
branch별 버전을 따 이를 설치해주기만 하면 된다
argo로 설치한 모습
설치 하면 karpenter의 crd를 볼 수 있고 이를 통해 설정하기만 하면 된다
이제부턴 커스텀의 영역이다
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: karpenter-node-pool
annotations:
kubernetes.io/description: "Node pool service"
spec:
template:
metadata:
labels:
scope: karpenter-service
spec:
nodeClassRef:
name: default
requirements:
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: ["t", "m"]
- key: "karpenter.k8s.aws/instance-cpu"
operator: Lt
values: ["8"]
- key: "karpenter.k8s.aws/instance-generation"
operator: In
values: ["4", "6"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["ap-northeast-2a", "ap-northeast-2b"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["on-demand", "spot"]
disruption:
consolidationPolicy: WhenUnderutilized
limits:
cpu: "20"
memory: 100Gi
weight: 50우선 NodePool이라는 CRD를 설정하는데
labels를 지정해 해당 label이 설정된 node들만 동작하도록 한다
그렇지 않으면 서버를 내릴때 치명적인 서비스가 있는 노드들도 영향을 받아 운영에 문제가 생길 수 있다
requirements는 원하는 대로 수정하면 되는데
위에서부터 instance 타입은 t와 m, cpu는 8코어 미만, 타입 세대는 4 또는 6, os와 type은 2가지 모두 선택할 수 있도록 했다
그리고 karpenter를 굴릴 모든 노드들의 코어와 메모리는 20, 100gi를 넘지 않도록 한다 (무분별한 확장을 막기 위함)
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
annotations:
kubernetes.io/description: "General purpose EC2NodeClass for running Amazon Linux 2 nodes"
spec:
amiFamily: Bottlerocket
role: "AmazonEKSNodeRole"
subnetSelectorTerms:
- id: subnet-01aaaaaaaaaaaaaaa
- id: subnet-02aaaaaaaaaaaaaaa
securityGroupSelectorTerms:
- tags:
kubernetes.io/cluster/my-cluster: "owned"
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeType: gp3
volumeSize: 2Gi
deleteOnTermination: true
- deviceName: /dev/xvdb
ebs:
volumeType: gp3
volumeSize: 20Gi
deleteOnTermination: true그리고 Ec2NodeClass를 지정해 생성할 노드의 ami 템플릿을 지정한다
bottlerocket os를 사용해 subnet과 cluster, ebs로 gp3를 설정해 주었다
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
revisionHistoryLimit: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: 8080
resources:
limits:
memory: "0.5Gi"
cpu: "0.25"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/arch
operator: In
values:
- arm64
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: ["t"]
- key: "karpenter.k8s.aws/instance-cpu"
operator: In
values: ["2", "4"]
- key: "karpenter.k8s.aws/instance-generation"
operator: In
values: ["4"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["ap-northeast-2a", "ap-northeast-2b"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot"]적용할 서비스에는 requirements에 설정했던 값들중 해당 pod의 조건들을 넣어 주고 배포하면 된다
타입은 t, cpu는 2,4코어, 4세대에 스팟 노드에만 해당 pod가 scheduling 하겠다는 뜻이다
메모리 조건이 없으므로 조건을 만족하는 인스턴스 타입은 t4gnano, t4gmicro, t4gsmall, t4gmedium, t4glarge, t4gxlarge의 spot 노드이다
조건을 만족하는 노드들에 scheduling 할 수 있는지 확인하고 없다면 리소스 상황을 고려해 karpenter가 생성해 준다
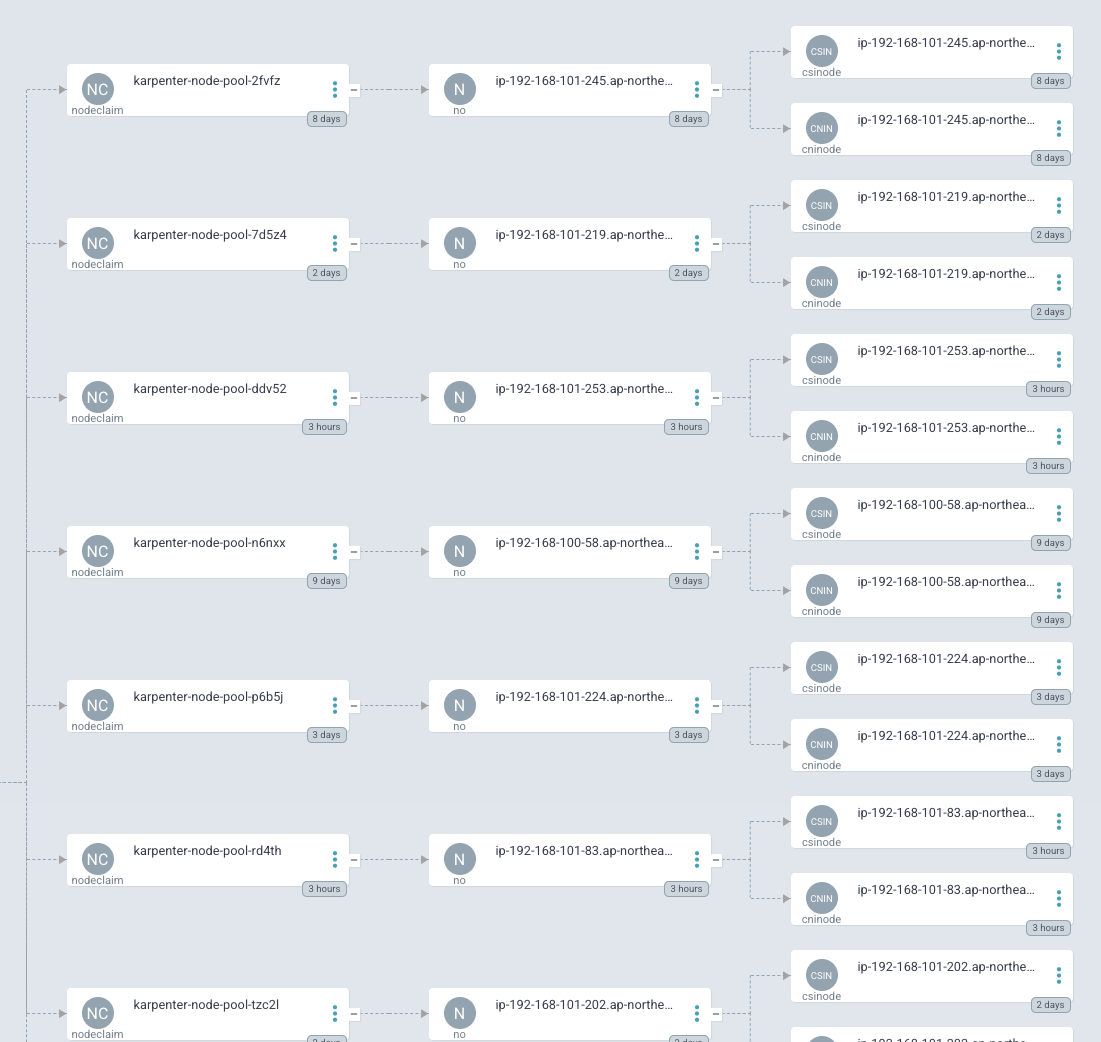
적용후 argo에서 확인한 모습
적용 후 node pool은 pending된 pod들을 확인 후 관리하는 node를 생성한다
서버 생성주기도 들쭉날쭉한게 지속적으로 서버를 교체해주고 자리가 없으면 추가하고 제거하는 일을 계속 한다
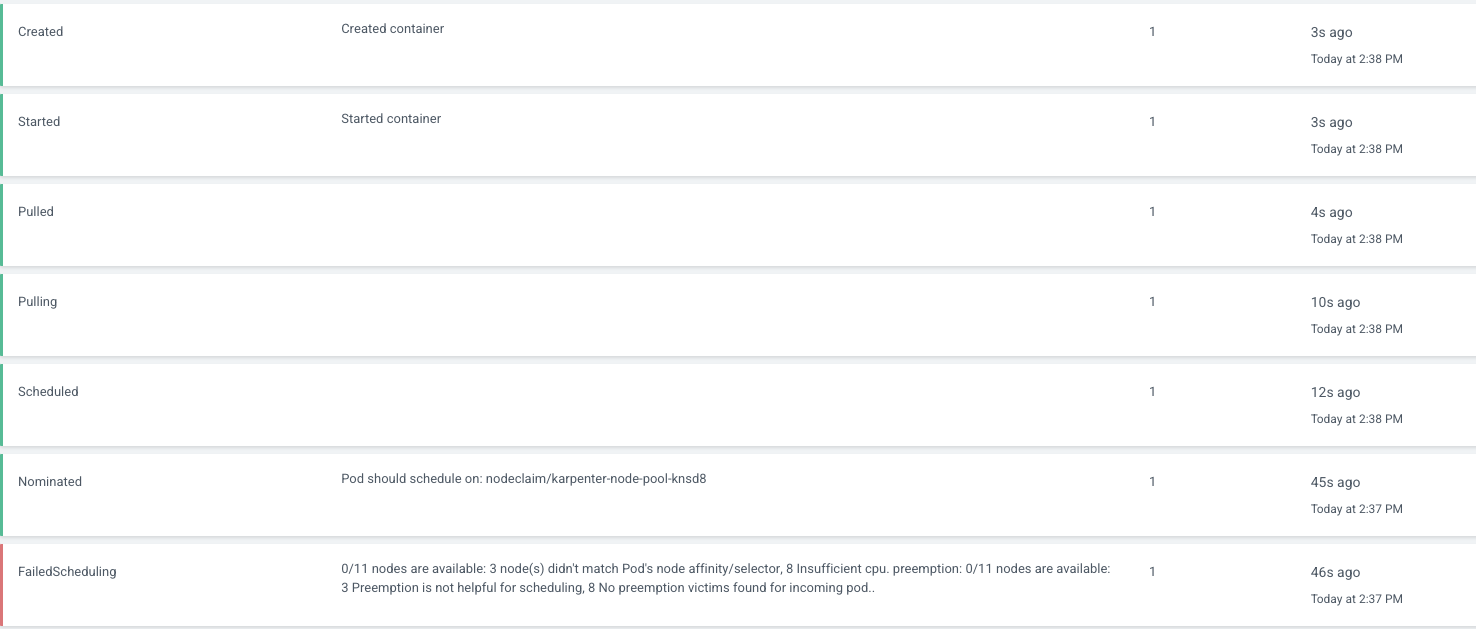
이를 변경하는 주기도 상당히 빠르다
1초만에 감지해 node pool을 scheduling 시키고
30초 만에 노드를 생성해 빠르게 creating 시켜준다
bottlerocket이 상당히 부팅속도가 빠른편이라 30초지만 그래도 정말 빠른 시간내에 해결한다
karpenter 적용에 대해 알아 보았다
생각보다 간단한 설정과 좋은 성능으로 많은 곳에서 사용하지 않을까 싶다
이번에 Azure에서도 사용 가능하다고 하니 AKS를 사용하시는 분도 적용할 수 있을 것 같다
https://learn.microsoft.com/en-gb/azure/aks/node-autoprovision?tabs=azure-cli
