
Kinesis
Amazon Kinesis는 다양한 서비스의 대규모 데이터 스트림을 실시간으로 처리하도록 설계된 Amazon Web Service입니다.
- Kinesis를 이용해 Application logs, Metrics, Website clickstreams, IOT 등을 처리할 수 있습니다.

- Kinesis는 네 가지 요소로 이루어져 있습니다.
- Kinesis Data Streams: 데이터 스트림을 캡쳐, 처리, 저장
- Kinesis Data Firehose: AWS 데이터 스토어에 데이터 스트림을 분석
- Kinesis Data Analytics: SQL이나 Apache Flink로 데이터 스트림을 분석
- Kinesis Video Streams: 비디오 스트림을 캡쳐, 처리, 저장하는 역할
Kinesis 종류
Kinesis Data Streams
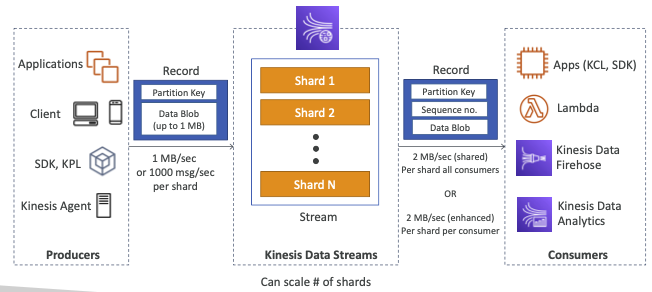
- Kinesis Data Streams는 Stream으로 이루어져 있습니다.
- Stream은 N개의 샤드로 구성되며 이 샤드 개수는 스케일링할 수 있습니다. (즉, 원하는 개수 만큼의 샤드를 가질 수 있습니다).
- Kinesis Data Streams에 샤드가 많을수록 스트림을 통과할 수 있는 처리량이 증가하게 됩니다.
- 만약 생산자가 동일한 partition key를 사용하면 동일한 샤드로 데이터가 이동합니다.
- 요금은 프로비저닝 된 샤드 마다 부과됩니다.
- Retention은 1일 ~ 365일까지 가능합니다.
- 1일이 기본값입니다.
- 만약 데이터가 한 번 Kinesis로 들어가면 해당 데이터는 삭제할 수 없습니다. (immutability).
- 데이터끼리 서로 같은 partition key를 가지면 해당 데이터들은 같은 샤드로 들어갑니다. (ordering).
생산자
- SDK, KPL, Kinesis 에이전트를 사용할 수 있습니다.
소비자
- KCL, SDK를 직접 만듬
- AWS Lambda, Kinesis Data Firehose Kinesis Data Analytics 같은 관리된 소비자
용량 모드 :
- 프로비저닝된 용량 모드
- 프로비저닝할 샤드 수를 정하고 직접 또는 API를 통해 조정합니다.
- 온디맨드 모드
- 용량을 프로비저닝하거나 관리할 필요가 없습니다.
- 기본적으로는 초당 4 MB 또는 4,000개의 레코드를 처리합니다.
- 용량은 자동으로 최근 30일 간 최대 사용량에 따라 조정됩니다.
- 시간 단위로 스트림당 데이터량(GB)에 따라 비용이 부과됩니다.
Kinesis Data Streams Security
- IAM 정책을 사용하여 액세스/인증 제어
- HTTPS endpoint를 사용하여 전송 중 암호화
- KMS를 사용한 미사용 암호화
- 클라이언트 측에서 데이터의 암호화/복호화를 구현할 수 있습니다(어려움).
- Kinesis가 VPC 내에서 액세스할 수 있는 VPC 엔드포인트
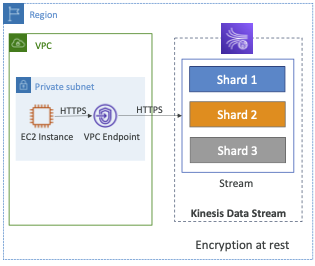
- CloudTrail을 사용하여 API 호출 모니터링
Kinesis Data Firehose
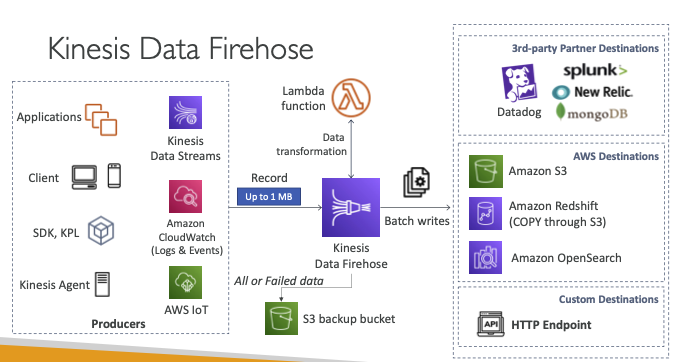
- 목적지까지 전송되는 데이터를 저장하는 것입니다.
- 거의 실시간 서비스라 할 수 있습니다.
- 별도로 관리할 필요가 없고 자동으로 확장되며 서버가 없습니다.
- AWS의 Redshift, Amazon S3, and Elasticsearch
- 3rd party partner: splunk, MongoDB, DataDog, NewRelic
- 사용자 지정 HTTP 엔드 포인트어디든 보낼 수 있습니다.
- 비용은 Firehose에서 처리한 데이터에만 부과됩니다.
- 거의 실시간에 가깝게 처리됩니다.
- 수신처로 데이터 배치를 쓰기 때문
- 배치가 아닌 경우, 지연 시간은 최소 60초 이거나 한번에 적어도 1MB의 데이터를 보내야합니다.
- 여러 형태의 데이터 포맷과 변환 압축을 지원하고 앞서 설명한 Lambda를 통한 사용자 지정 데이터 변환도 지원합니다.
- 처리에 실패하거나 처리된 모든 데이터를 S3 백업 버킷에 보낼 수도 있습니다.
Kinesis Data Streams vs Firehose
- Kinesis Data Streams
- 대규모로 데이터를 수집하는 스트리밍 서비스
- 사용자 지정 코드를 작성해
데이터 전송과소비에 사용할 수 있습니다. - 실시간 처리 (0 ~ 200 ms)
- 스케일링 관리 (샤드 추가/분할/통합)
- 1-365일간 보존되며 따라서 같은 스트림에서 읽어올 수 있고, 재생 기능을 지원합니다.
- Kinesis Data Firehose
- S3 Redshift, Elasticsearch 타사, HTTP로 전송하는 것이 목적입니다.
- 완전 관리형 서비스
- 데이터는 버퍼에서 배치로 쓰이기 때문에 거의 실시간으로 작동합니다.
- 확장은 자동으로 이루어집니다.
- 데이터 저장소가 없습니다.
- 데이터를 재생할 수 없습니다.
Kinesis Data Analytics
- 완전 관리형 모델
- 프로비저닝할 서버가 없습니다.
- 자동으로 확장됩니다.
- 실시간 분석이 목적입니다.
- 비용은 처리된 만큼 부과되므로, 실제 사용량에 기반하며 실시간 쿼리를 통해 스트리밍을 생성할 수 있습니다.
- 사용 :
- 시계열 분석, 실시간 대시보드, 실시간 지표
Kinesis vs SQS FIFO ordering
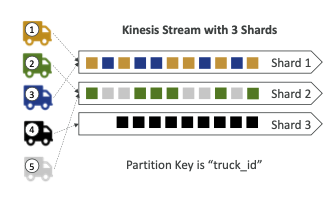
각각 트럭 ID를 가지고 있는 100대의 트럭이 있고 GPS 위치를 주기적으로 AWS에 보낼 겁니다. 이제 각 트럭의 순서대로 데이터를 소비해서 트럭의 이동을 정확하게 추적하고 그 경로를 순서대로 확인하려고 합니다 어떻게 Kinesis로 데이터를 전달할까요?
-
Kinesis Data Streams
- 파티션 키를 사용하면됩니다.
- 동일한 파티션 키는 동일 한 샤드로 들어가기 때문에, 평균적으로 가지는 값은 샤드당 트럭 20대 입니다.
- 하지만 트럭과 각각의 샤드 사이가 직접적으로 연결된 것은 아닙니다. Kinesis가 파티션 키를 해시해서 어느 샤드로 보낼지 결정하지요. 다시 말해 안정된 파티션 키를 얻으면 바로 트럭이 그 데이터를 같은 샤드로 전달하고 그러면 샤드 레벨에서 각 트럭의 순서에 따른 데이터를 얻을 수 있게 됩니다.
-
SQS FIFO
-
SQS 표준의 경우 주문이 없습니다.
-
SQS FIFO의 경우 그룹 ID를 사용하지 않으면 메시지는 보낸 순서대로 소비되며 소비자는 한 명뿐입니다.

-
소비자 수를 늘리고 싶지만 메시지가 서로 관련될 때 "그룹화"되기를 원합니다.
-
그런 다음 그룹 ID를 사용합니다(Kinesis의 파티션 키와 유사).
-
-
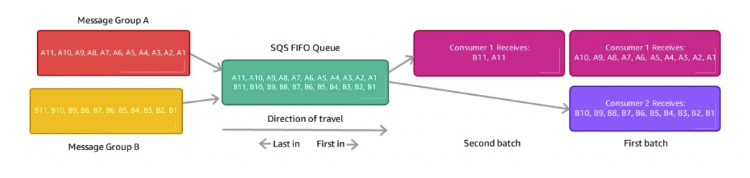
SQS FIFO 대기열이 하나
- 각 트럭 ID에 상응하는 그룹 ID를 100개 생성합니다.
- 소비자도 최대 100개가 될 수 있습니다.
- 규모를 보면 SQS FIFO에서 최대 초당 300, 혹은 배치를 사용하면 3,000개의 메시지를 가집니다.
Kinesis, SQS FIFO 차이점
트럭 100대, Kinesis 샤드 5개, SQS FIFO 1개를 가정해 보겠습니다.
- Kinesis 데이터 스트림:
- 평균적으로 샤드당 20대의 트럭이 있습니다.
- 트럭은 각 샤드 내에서 데이터를 정렬합니다.
- 우리가 가질 수 있는 최대 병렬 소비자 수는 5입니다. • 최대 5MB/s의 데이터를 수신할 수 있습니다.
- SQS FIFO
- SQS FIFO 대기열이 하나만 있습니다.
- 100개의 그룹 ID를 갖게 됩니다.
- 최대 100명의 소비자를 가질 수 있습니다(100개의 그룹 ID로 인해).
- 초당 최대 300개의 메시지가 있습니다(또는 일괄 처리를 사용하는 경우 3000개).
SQS vs SNS vs Kinesis
- SQS
- 메시지를 요청해서 데이터를 가져오는(pull) 모델
- 데이터를 처리 후에 소비자가 대기열에서 삭제하서 다른 소비자가 읽을 수 없게 합니다.
- 작업자나 소비자 수가 제한이 없습니다.
- 관리된 서비스이므로 처리량을 프로비저닝할 필요가 없습니다.
- 순서를 보장하려면 FIFO 대기열을 활성화합니다.
- 각 메시지에 지연 기능이 있습니다.
- SNS
- 다수의 구독자에게 데이터를 푸시하면 메시지의 복사본을 받게됩니다.
- SNS 주제별로 1,250만 명의 구독자까지 가능합니다.
- 데이터가 한 번 SNS에 전송되면 지속되지 않습니다.
- 제대로 전달되지 않는다면 데이터를 잃을 가능성이 있습니다.
- 게시-구독 모델은 최대 10만 개의 주제로 확장 가능합니다.
- 처리량을 프로비저닝하지 않아도 됩니다.
- 팬아웃 아키텍처 패턴을 이용하면 SQS와 결합할 수 있습니다.
- SNS FIFO 주제를 SQS FIFO 대기열과 결합할 수 있죠.
- Kinesis
- 표준모드
- 소비자가 Kinesis로부터 데이터를 가져옵니다.(pull)
- 샤드당 2 MB/s의 속도를 지원해요
- 향상된 팬아웃 유형의 소비 메커니즘
- 샤드 하나에 소비자당 2 MB/s의 속도가 나옵니다.
- 데이터를 다시 재생할 수 있어요.
- Kinesis 데이터 스트림에서는 데이터가 지속되기 때문에
- 실시간 빅 데이터 분석, ETL 등에 활용됩니다.
- 샤드 레벨에서 정할 수 있습니다.
- 1에서 365일까지 데이터를 보존할 수 있습니다.
- 프로비저닝 용량 모드
- Kinesis 데이터 스트림으로부터 원하는 샤드 양을 미리 지정합니다.
- 온 디맨드 용량 모드
- 샤드 수가 Kinesis 데이터 스트림에 따라 자동으로 조정됩니다.
- 표준모드
Amazon MQ
온프레미스에서 기존 애플리케이션을 실행하는 경우 개방형 프로토콜인 MQTT, AMQP, STOMP, WSS Openwire 등을 사용하곤 합니다.
애플리케이션을 클라우드에 마이그레이션하는 경우 SQS, SNS 프로토콜 혹은 API를 사용하기 위해 애플리케이션을 다시 구축하고 싶지 않고 MQTT, AMQP 등과 같은 기존에 쓰던 프로토콜을 사용하고 싶을 때 사용하는 것이 바로 Amazon MQ입니다.
즉, 애플리케이션을 마이그레이션할 때 전부 재설계를 하는 대신
메시지 대기열을 클라우드로 그냥 옮길 수 있습니다.
- Amazon MQ는 RabbitMQ와 ActiveMQ를 위한 관리된 메시지 브로커서비스입니다.
- RabbitMQ와 ActiveMQ는 온프레미스 기술로 앞서 말했던 개방형 프로토콜 엑세스를 제공합니다.
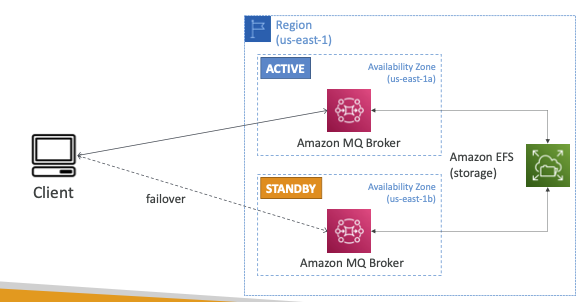
- Amazon MQ는 서버에서 실행되므로 서버 문제가 있을 수 있기 때문에, SQS나 SNS 만큼 확장되지 않습니다.
- 전용 머신에서 실행됩니다.
- 장애 조치에 대해 고가용성을 설정할 수 있습니다.
- SQS처럼 대기열 기능도 있습니다.
- SNS처럼 주제 기능도 있습니다.
