
Amazon Athena
Amazon Athena는 서버리스 방식의 대화형 분석 서비스입니다.
Amazon Athena란?
- Amazon
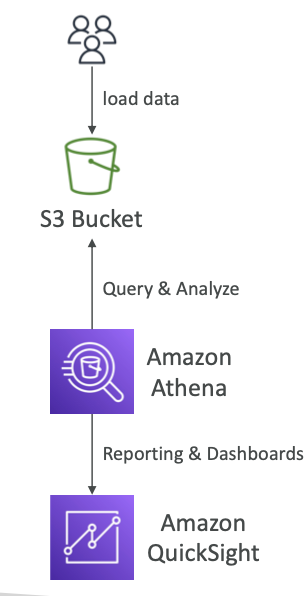
S3에 저장된 데이터를 분석하는 서버리스 쿼리 서비스 - 표준
SQL 언어를 사용하여 파일 쿼리(Presto 기반) - CSV, JSON, ORC, Avro 및 Parquet 지원
- 요금: 스캔한 데이터 TB당 $5.00
- 보고/대시보드를 위해 일반적으로 Amazon Quicksight와 함께 사용됨
- 사용 사례: 비즈니스 인텔리전스/분석/보고, VPC 흐름 로그 분석 및 쿼리, ELB 로그, CloudTrail 추적 등...
- 팁: 서버리스 SQL을 사용하여 S3에서 데이터 분석, Athena 사용
Athena 성능 개선
- 비용을 지불할 때 TB당 가격을 지불하므로, 절감을 위해 컬럼 데이터 사용(스캔 감소)
- Apache Parquet 또는 ORC 권장
- 엄청난 성능 향상
- Glue를 사용하여 데이터를 Parquet 또는 ORC로 변환
- Glue는 적재(ETL) 작업으로 CSV와 Parquet 간의 데이터를 변환하는 데 매우 유용
- 더 작은 검색을 위해 데이터 압축(bzip2, gzip, lz4, snappy, zlip, zstd...)
- 가상 열에서 쉽게 쿼리할 수 있도록 S3의 파티션 데이터 세트
s3://yourBucket/pathToTable /<PARTITION_COLUMN_NAME>=<VALUE> /<PARTITION_COLUMN_NAME>=<값> /<PARTITION_COLUMN_NAME>=<값> /등...- 예:
s3://athena-examples/flight/parquet/year=1991/month=1/day=1/
- Amazon S3에 작은 파일이 너무 많으면 Athena는 큰 파일이 있을 때보다 성능이 떨어집니다. 오버헤드 최소화하기위해 더 큰 파일(> 128MB)을 사용하면 성능향상이 가능합니다.
연합 쿼리
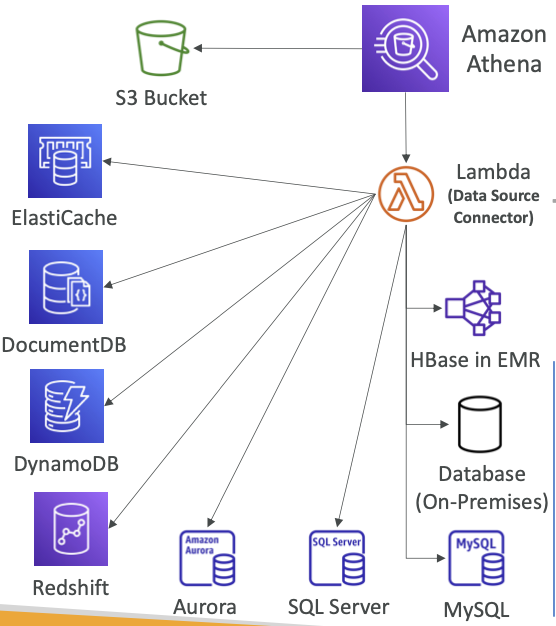
- Athena는 S3뿐만 아니라 어떤 곳의 데이터도 쿼리할 수 있습니다.
- 관계형, 비관계형, 개체 및 사용자 지정 데이터 소스(AWS 또는 온프레미스)에 저장된 데이터에 대해 SQL 쿼리를 실행할 수 있습니다.
- 연합 쿼리(예: CloudWatch Logs, DynamoDB, RDS 등)를 실행하기 위해 AWS Lambda에서 실행되는
데이터 원본 커넥터를 사용합니다. - 다양한 데이터베이스들의 쿼리를 조인하거나 비교할 수도 있습니다
- 결과를 Amazon S3에 다시 저장
Redshift
Redshift란?
Amazon Redshift는 클라우드에서 완벽하게 관리되는 페타바이트급 데이터 웨어하우스 서비스입니다.
- Redshift는
PostgreSQL을 기반으로 하지만OLTP에는 사용되지 않습니다.
-OLTP: 온라인 트랜잭션 처리
-OLAP: 온라인 분석 처리 OLAP입니다 – 온라인 분석 처리(분석 및 데이터 웨어하우징)- 다른 데이터 웨어하우스보다 10배 뛰어난 성능, 데이터 PB로 확장
- 데이터의 열 저장(행 기반 대신) 및 병렬 쿼리 엔진
- 기반으로 사용한 만큼 지불 프로비저닝된 인스턴스
- 쿼리를 수행하기 위한
SQL 인터페이스가 있습니다. - Amazon Quicksight 또는 Tableau와 같은 BI 도구가 통합됩니다.
- vs Athena: 인덱스 덕분에 더 빠른 쿼리/조인/집계
- Redshift는 먼저 가령 Amazon S3에서 모든 데이터를 Redshift에 로드해야 합니다. Redshift에 데이터를 로드하고 나면 Redshift의 쿼리가 더 빠르고 조인과 통합을 훨씬 더 빠르게 할 수 있는데, Athena에는 없는 인덱스가 있기 때문입니다.
Redshift는 데이터 웨어하우스가 높은 성능을 발휘하도록 인덱스를 빌드합니다. Amazon S3의 임시 쿼리라면 Athena가 좋은 사용 사례가 되지만 쿼리가 많고 복잡하며 조인하거나 집계하는 등 집중적인 데이터 웨어하우스라면 Redshift가 더 좋습니다.
- Redshift는 먼저 가령 Amazon S3에서 모든 데이터를 Redshift에 로드해야 합니다. Redshift에 데이터를 로드하고 나면 Redshift의 쿼리가 더 빠르고 조인과 통합을 훨씬 더 빠르게 할 수 있는데, Athena에는 없는 인덱스가 있기 때문입니다.
Redshift Cluster
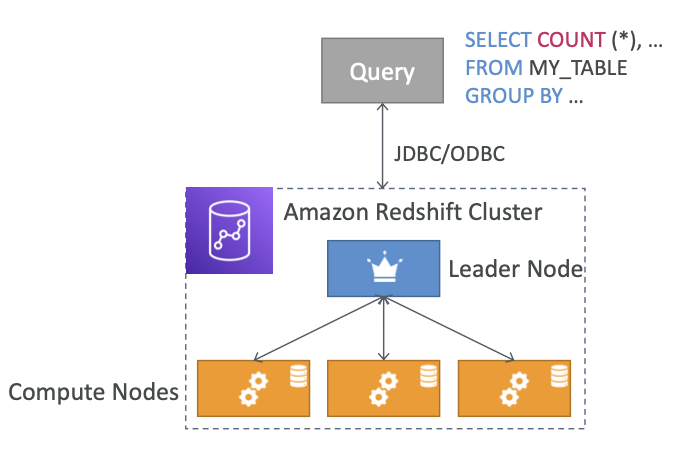
- 리더 노드: 쿼리 계획, 결과 집계용
- 컴퓨팅 노드: 쿼리 수행을 위해 리더에게 결과 전송
- 사전에 노드 크기를 프로비저닝합니다.
- 비용 절감을 위해 예약 인스턴스를 사용할 수 있습니다.
Snapshots & DR

- Redshift에는 다중 AZ 모드가 없고 클러스터가 한 개의 가용 영역에 있으므로 Redshift에 재해 복구 전략을 적용하려면 스냅샷을 사용해야 합니다.
- 스냅샷은 클러스터의 특정 시점 백업입니다.
- 스냅샷은 점진적입니다(변경된 항목만 저장됨).
S3에 내부적으로 저장 - 스냅샷을 새 클러스터로 복원할 수 있습니다.
- 자동: 8시간마다, 5GB마다 또는 예약할 수 있습니다.
- 수동: 직접 스냅샷을 삭제하기 전까지 스냅샷 유지
- Redshift의 정말 훌륭한 기능은 자동이든 수동이든 클러스터의 스냅샷을 다른 AWS 리전에 자동으로 복사하도록 Redshift를 구성하여 재해 복구 전략을 적용할 수 있다는 점입니다.
Loading data into Redshift: Large inserts are MUCH better
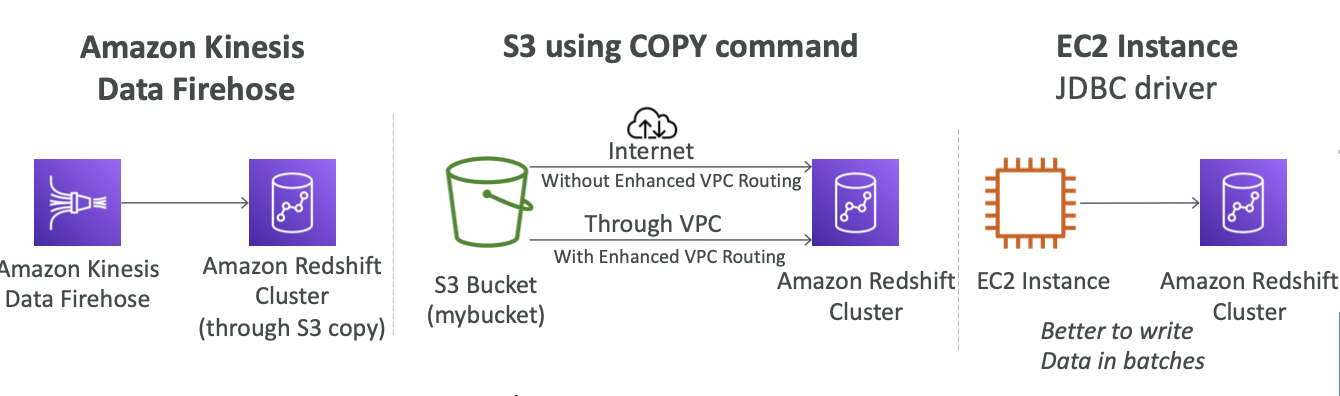
Redshift에 데이터를 주입하는 방법에는 총 세 가지가 있습니다.
1. Amazon Kinesis Data Firehose를 사용하는 방법
Firehose가 다양한 소스로부터 데이터를 받아서 Redshift에 보내는 것입니다. 먼저 Amazon S3 버킷에 데이터를 써야겠죠 그러면 자동으로 Kinesis Data Firehose가 S3 복사 명령을 실행해 Redshift에 데이터가 로드됩니다.
2. S3 using COPY command
S3에 데이터를 로드하고 Redshift에서 복사 명령을 실행하면 IAM 역할을 사용해 S3 버킷에서 Amazon Redshift 클러스터로 데이터를 복사합니다
copy customer
from 's3://mybucket/mydata’
iam_role 'arn:aws:iam::0123456789012:role/MyRedshiftRole';
여기엔 두가지 방법이 있는데, 첫번째로 S3 버킷이 퍼블릭이면 인터넷과 연결돼 있을 테니, 데이터가 인터넷을 통해 다시 Redshift 클러스터로 이동시킵니다. 이때는 향상된 VPC 라우팅 없이도 가능합니다.
두번째로 모든 네트워크를 가상 프라이빗 클라우드에 비공개 상태로 유지하고 싶다면 모든 데이터가 VPC로 완전히 이동되도록 향상된 VPC 라우팅을 사용하면 됩니다
향상된 VPC 라우팅을 사용하여 VPC를 통해 트래픽을 라우팅할 때 VPC 흐름 로그를 사용하여 COPY 및 UNLOAD 트래픽을 모니터링 할 수도 있습니다 .
3. EC2 Instance JDBC driver
JDBC 드라이버를 사용해 Redshift 클러스터에 데이터를 삽입하는 방법입니다.
예를 들어 애플리케이션에 Redshift 클러스터에 써야 하는 EC2 인스턴스가 있을 때 이 방법을 사용하면 됩니다
이때 Amazon Redshift에 큰 배치로 데이터를 쓰는 것이 좋습니다. 이 유형의 데이터베이스에 한 번에 한 행씩 쓰는 건 비효율적입니다.
Redshift Spectrum
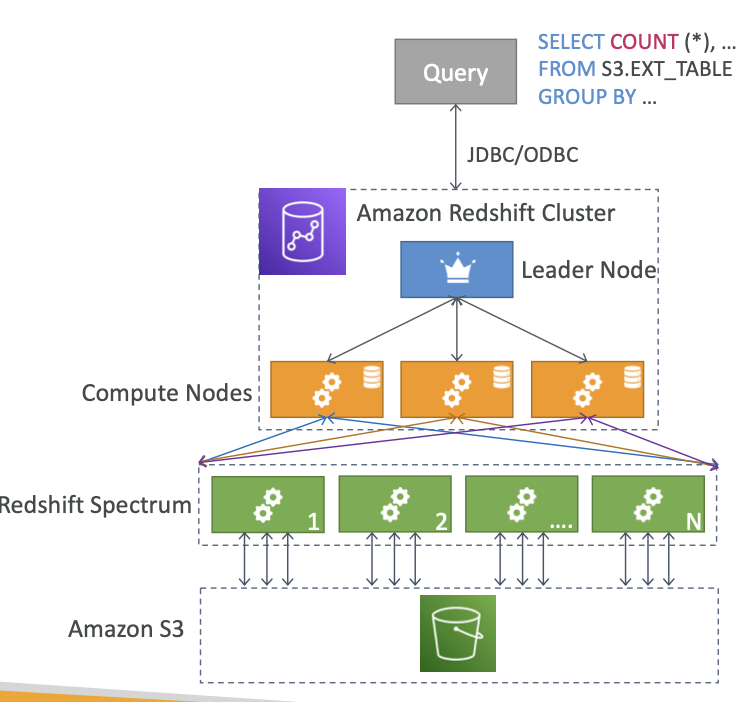
- S3에 이미 있는 데이터를 Redshift로 로드하지 않고 쿼리
- 쿼리를 시작하려면 Redshift 클러스터를 사용할 수 있어야 합니다.
- 쿼리는 수천 개의 Redshift Spectrum 노드에 제출됩니다.
OpenSearcher
OpenSearcher란?
OpenSearch는 Apache 2.0 라이선스 하에 제공되는 분산형 커뮤니티 기반 100% 오픈 소스 검색 및 분석 제품군으로, 실시간 애플리케이션 모니터링, 로그 분석 및 웹 사이트 검색과 같이 다양한 사용 사례에 사용됩니다.
- Amazon OpenSearch는 Amazon ElasticSearch의 후속 제품입니다.
- DynamoDB에서 쿼리는 기본 키 또는 인덱스로만 존재합니다. 반면에, OpenSearch를 사용하면
부분적으로 일치하는 필드를 포함하여 모든 필드를 검색할 수 있습니다. - 다른 데이터베이스를 보완하기 위해 OpenSearch를 사용하는 것이 일반적입니다.
- OpenSearch에는 인스턴스 클러스터가 필요합니다(
서버리스 아님). SQL을 지원하지 않음(자체 쿼리 언어 있음)- Kinesis Data Firehose, AWS IoT 및 CloudWatch Logs에서 수집
- Cognito 및 IAM을 통한 보안, KMS 암호화, TLS
- OpenSearch 대시보드와 함께 제공(시각화)
OpenSearch patterns DynamoDB
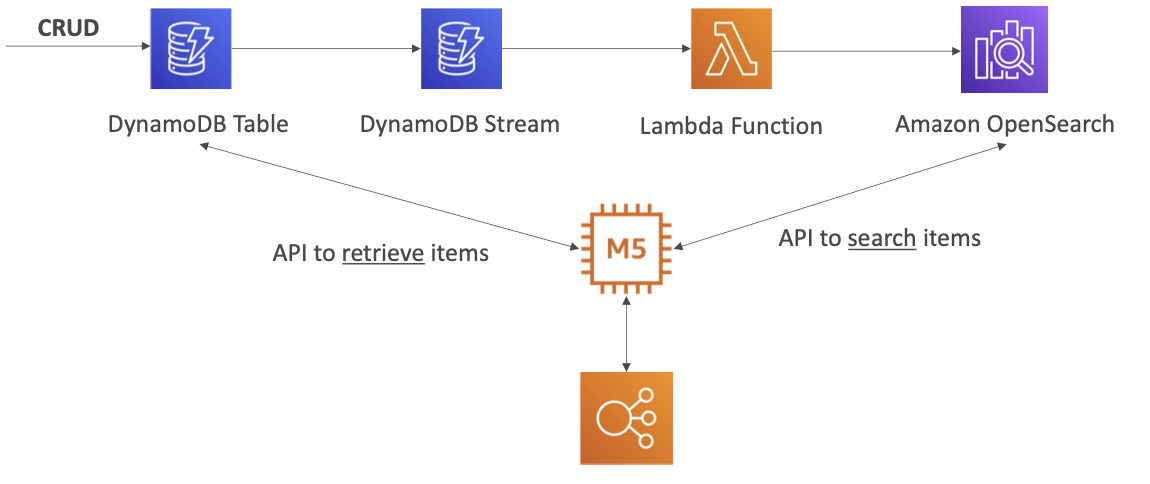
- 데이터가 포함된 DynamoDB가 있고 사용자가 이 데이터를 삽입, 삭제, 업데이트합니다.
- 모든 스트림을 DynamoDB Stream으로 보내면 Lambda 함수가 받아 Amazon OpenSearch에 실시간으로 데이터를 삽입합니다
- 이러한 과정을 통해 애플리케이션은 특정 항목을 찾을 수 있게 됩니다.
- 예를 들면 항목의 이름을 부분 검색해 항목 ID를 알아낼 수 있습니다. 항목 ID를 얻은 후에는 DynamoDB를 호출해 DynamoDB 테이블에서 전체 항목을 검색합니다.
- OpenSearch로 검색하지만 메인 소스 데이터는 DynamoDB에 남아 있습니다.
OpenSearch patterns CloudWatch Logs

- CloudWatch Logs로 OpenSearch에 데이터를 주입할 수도 있습니다.
- 먼저 AWS Lambda 함수에
실시간으로 데이터를 전송하는 CloudWatch Logs 구독 필터를 사용하고, Lambda 함수는 Amazon OpenSearch에 실시간으로 데이터를 보냅니다 - 아니면 CloudWatch Logs에서 구독 필터로 보낸 다음 Kinesis Data Firehose로 구독 필터의 데이터를 읽고 Amazon OpenSearch에
거의 실시간으로 데이터를 주입할 수도 있습니다
OpenSearch patterns Kinesis Data Streams & Kinesis Data Firehose

- Kinesis Data Streams의 스트림을 Amazon OpenSearch로 보낼 때 두 가지 전략이 있습니다
- Kinesis Data Firehose는
거의 실시간 유형의 서비스입니다.
Lambda 함수를 사용해 일부 데이터를 변환한 다음에 Amazon OpenSearch로 전송하는 옵션도 있어요 - 아니면 Kinesis Data Streams에서 데이터 스트림을 실시간으로 읽는 Lambda 함수를 생성하고 커스텀 코드를 작성해서 Lambda 함수가 Amazon OpenSearch에 실시간으로 데이터를 쓰게 할 수도 있습니다.
