
결론
API latency를 줄여달라는 요청이와서 개선 가능여부 확인 - 코드 수정 - 리뷰 - 카나리 배포 - 전체 배포까지 약 2시간이 소요되었습니다.
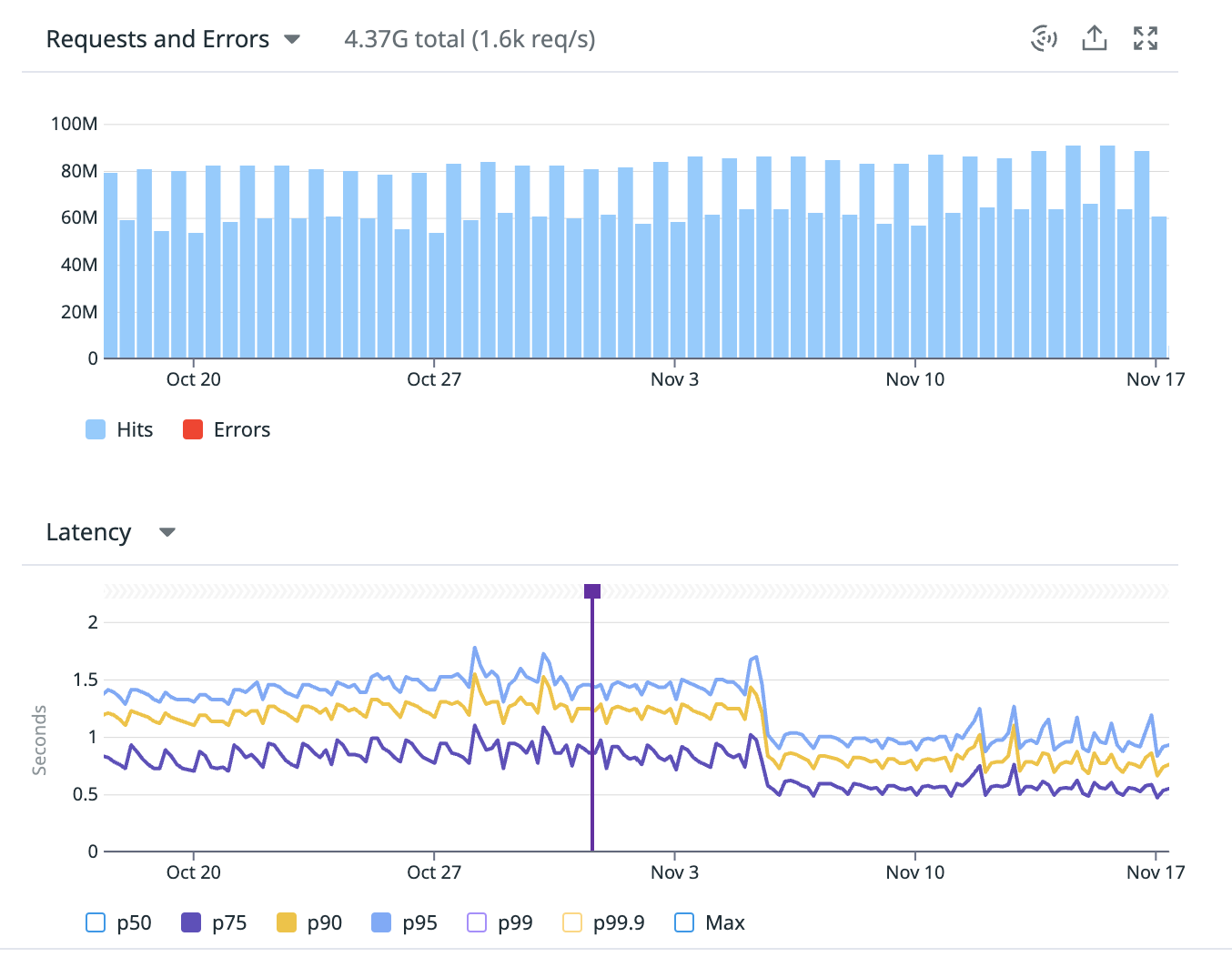
해당 개선 로직이 여러 API에서 공통적으로 쓰이는 로직이다보니 각 API들을 합쳤을 때 일 약 2억건 이상의 트래픽이 발생하고 있는 상황입니다. 개선 후 모니터링하니 해당 전체적인 트래픽들에서 약 30% 가 감소되었습니다.
API 중 하나만 공유해보자면, p90 이상에서 약 1.3s 에서 0.8s 로 latency가 개선되었고 p75이상 트래픽에서 전반적인 개선을 할 수 있었습니다.
개선한 부분
golang server 에서 특정 로직에 loop 이 돌아가는데 각 loop 에서 동기로 kafka produce 하는 로직을 비동기로 변경하였습니다.
Kafka producer client는 기본적으로 비동기로 동작합니다. 이를 동기로 처리하려면 client에서 동기로 동작하도록 변경해야하지만 이는 권장하는 방법은 아닙니다.
producer client에서 Produce method를 호출 시, 각 topic partition 별로 queue에 enqueue가 되며 enqueue까지 처리되면 Produce method는 이에 대한 결과를 return 합니다.[ 관련 문서 링크 ]
librdkafka 내부 코드를 보면 실제 kafka server(broker)에 요청 이 발생하는건 별도 thread에서 round-robin로 각 partition 별 queue에서 적재된 msg를 batch로 produce 하도록 되어있습니다.
이 글의 주제와는 별개로 produce 시 내부적으로 batch로 처리가 되다보니 트래픽이 없던 개발환경에서 테스트 시 produce가 왜 되지 않는지, 확인하다가 flush timeout이 설정이 필요던 기억이 나네요.
기존에는 내부 partition 별 queue에 enqueue, produce, broker 간 replication, 응답받기 까지 소요되던 시간을 partition 별 queue에 enqueue 까지만 레이턴시가 발생하도록 변경하였습니다.
관련 코드
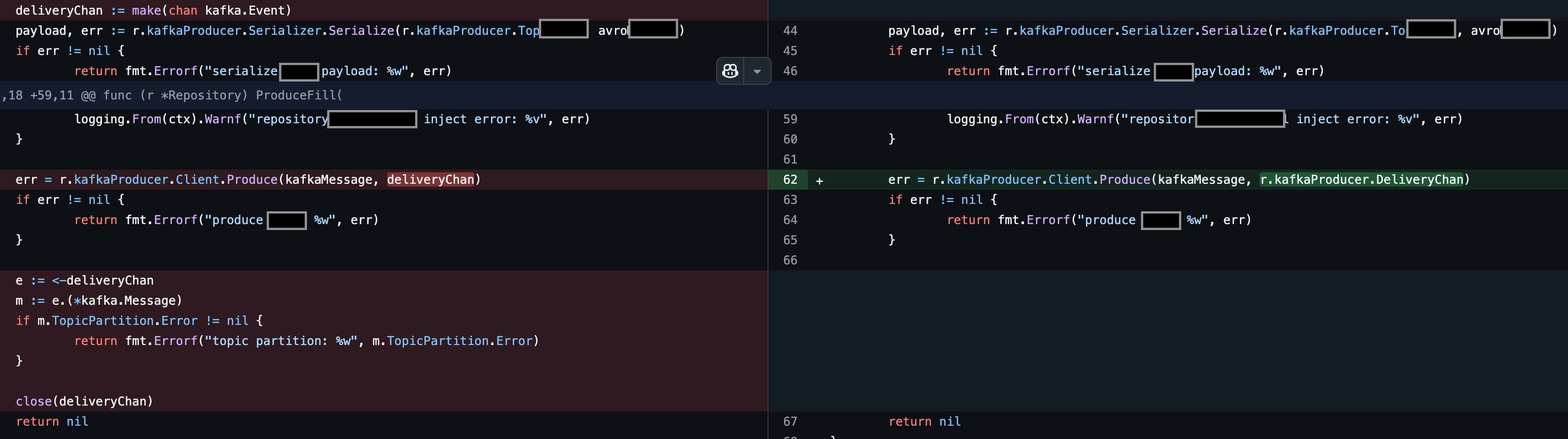
변경 전
deliveryChan := make(chan kafka.Event) // 요청 결과를 받을 channel 생성
...
// 비동기 produce 요청
err = r.kafkaProducer.Client.Produce(kafkaMessage, deliveryChan) // 비동기 요청 처리 결과를 받을 channel을 함께 전달
if err != nil { // enqueue에 대한 실패처리
return fmt.Errorf("produce: %w", err)
}
// 여기까진 내부에서 실행되는 로직이다보니 10 ms 도 발생하지 않음
// 비동기 요청의 응답을 받을 때 까지 block 이 발생하는 부분. 여기서 약 60ms 이상 소요됨
// 내부적으로 msg 이 batch 처리, 외부 broker에 요청, broker(server)간 msg replication 처리, 응답받기까지 block 되는 상황
e := <-deliveryChan
m := e.(*kafka.Message) // broker (server) 까지 결과에 따른 에러처리
if m.TopicPartition.Error != nil {
return fmt.Errorf("topic .. : %w", m.TopicPartition.Error)
}
close(deliveryChan)변경 후
...
// 각 요청 마다 응답 받을 channel을 생성 및 block 되던 방식에서 client가 모든 요청의 response를 받을 하나의 channel를 갖고 있고, 이를 사용도록 변경
// cr.kafkaProducer.deliveryChan은 별도 하나의 goroutine이 while loop을 돌면서 각 실패건에 대한 handling 하도록 함
err = r.kafkaProducer.Client.Produce(kafkaMessage, r.kafkaProducer.deliveryChan)
if err != nil {
return fmt.Errorf("produce: %w", err)
}
...
구체적인 도메인 관련 코드는를 가려두었습니다^^;
개선 결과

하나의 produce에서 약 60ms 씩 loop으로 돌며 약 500ms 발생하던 로직이
각 요청 별 enqueue까지 약 10ms 내로 처리되며 enqueue 이후 로직은 비동기로 병렬로 처리되었습니다. (노란색 trace).
일 약 2억 트래픽에서 약 p75이상 25% 트래픽에 개선, 트래픽 당 약 0.5s 개선이라고 볼 때,
2,500만 초 (5,000만 x 0.5s), 일 평균 약 6944시간 이상의 유저들의 시간을 절약할 수 있었습니다 : )
주의해야할 점
내부적으로 비동기 호출 및 batch 처리 가 되다보니 단건 동기처리를 위해서는 생각보다 이번 케이스처럼 latency가 발생할 수 있습니다. 트래픽이 적다면 flush 설정을 통해서 produce 처리되는 케이스들이 발생할 텐데 이 또한 best-practice가 아닐 수 있습니다.
이러하다보니 produce 시 아키텍처나 전반적인 로직처리에 대한 고민이 필요합니다. 비동기 처리가 가능한 로직인지, 혹은 어떻게 실패처리를 할 것인지나 msg 유실, 혹은 파티션에 커밋된 것은 순서가 보장된다하더라도 producer에서 partition 커밋까지는 순서가 보장되지 않을 수 있다는 점 등을요^^
참고문서
https://developer.confluent.io/courses/architecture/broker/
궁금하신 부분이나 오타 혹은 문서에 잘못 기재된 부분이 있다면 댓글로 부탁드리겠습니다 (_ _)
