참고 내용
본문
"데이터를 정규화 하는것이 왜 필요할까?" 라는 고민을 해왔다.
데이콘이나 캐글에서 데이터를 가져와서 쓸 때 고수분들이 하는 코드를 보면 수치형 데이터에 항상 데이터의 정규화가 있었기 때문이다. 전에 어떤 선배가 알려주기를 데이터의 스케일이 달라 모델에서 스케일에 따라서 중요도를 반영할수도 있기 때문이라고 했다.
또 책에는 이런 말이 나온다. 같은 90점이라도 평균이 30점인 시험과 평균이 99점인 시험에서 90점은 의미가 다르기 때문에 정규화를 통해 이것을 통일된 지표로 활용한다고 말이다.
둘 다 맞는 얘기 같다. 정규화를 쓰는 이유가 1가지 뿐만은 아닐 것이다.
다음 질문은 "어떻게 정규화를 하는지이다".
표준화
z = (x - x_평균) / 표준변차
다음이 표준화(정규화의 일종인듯 하다)를 나타내는 식이라고 한다.
이는 Z 점수라고도 표현한다고 하는데 코드로 나타내면 다음과 같다.
#scores는 np.array이다.
z = (scores - np.mean(scores)) / np.std(scores)
이를 이용해서 편차값이라는 값을 구할 수 있다.
예를 들어, 평균이 50이고 표준편차가 10이 되도록 정규화한 값을 구하기 위해서는 다음과 같이 값을 대입한다.
z = 50 + 10 * ((scores - np.mean(scores)) / np.std(scores))
다음과 같이 기본 표준화 식에서 파생해서 사용하는 것을 알 수 있다.
라이브러리
데이콘이나 캐글의 데이터를 보면 저런 기본적인 식보다는 라이브러리를 많이 사용한다. 하지만 어떤 원리로 작동하는지 이해하기 위해서 위의 글들을 작성했다.
예전에 데이콘에서 작성한 코드를 조금 가져와서 보여주자면
from sklearn.preprocessing import StandardScaler
standard = StandardScaler()
standard_fitted = standard.fit_transform(numerical_columns_df)다음과 같이 간단하게 정규화 중 하나인 StandardScaler(표준화)를 진행할 수 있다.
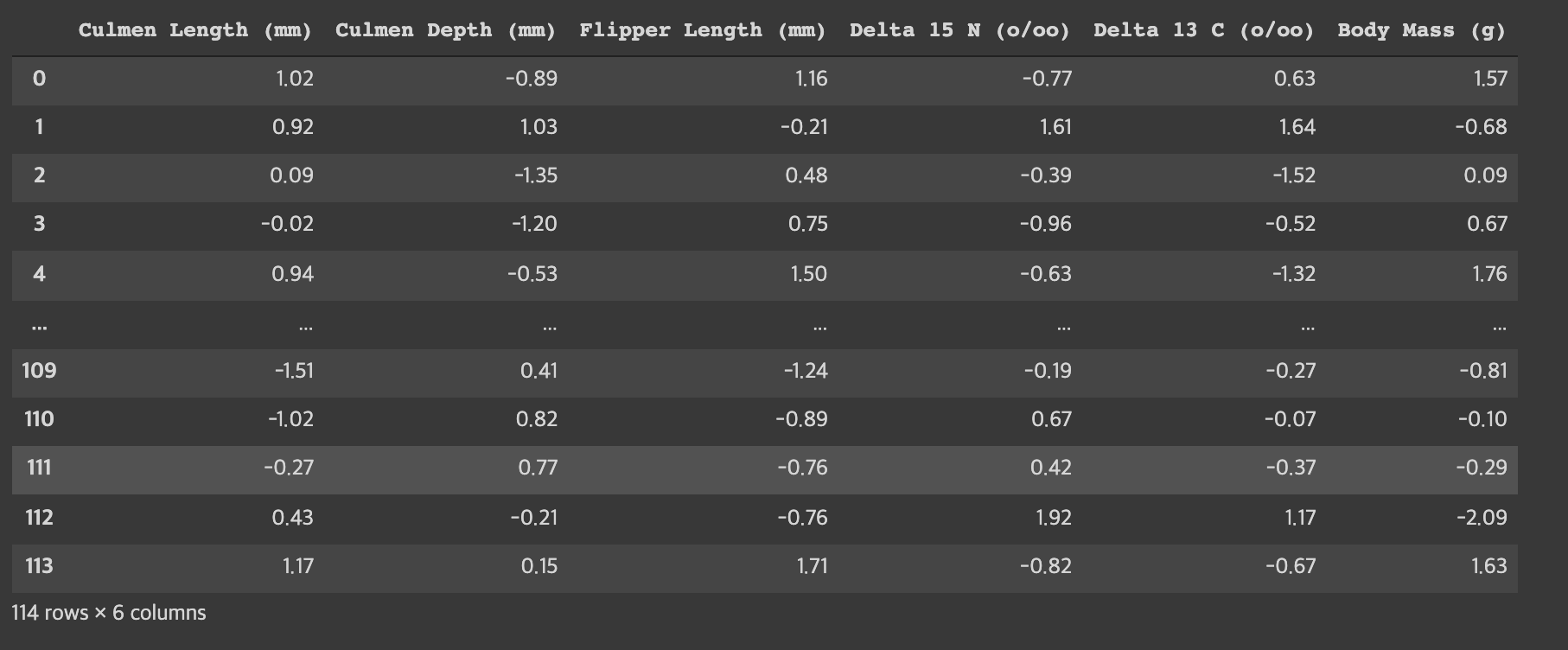 (그림1. 결과 예시)
(그림1. 결과 예시)
