
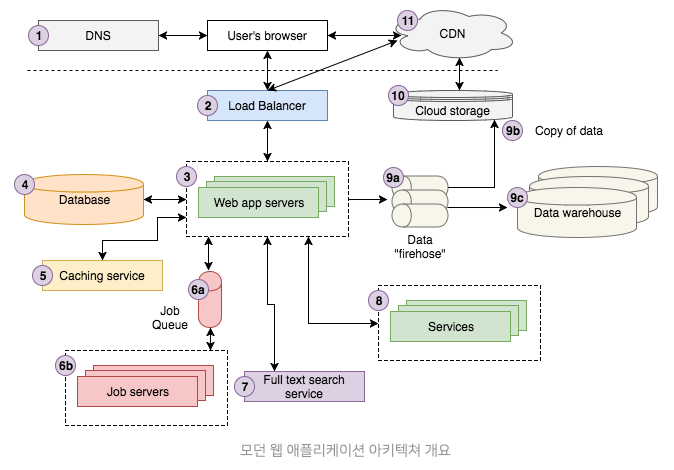
1. DNS
- “Domain Name Server”의 약자
- 가장 기본적인 레벨의 DNS는 도메인 이름에서 IP 주소로의 키/값 조회를 제공
- 도메인에서 IP 주소를 찾기 위해서는 DNS가 필요
2. 로드 밸런서
- 수평적 vs 수직적 애플리케이션 확장(scaling)
- 수평적 확장 : 더 많은 장치를 새로 추가
- 수직적 확장 : 사용하고 있던 장치의 성능(예. CPU, RAM)을 높이는 것
- 로드 밸런서는 수평적 확장이 가능하돌고 하는 마술
- 로드 밸런서는 요청을 복제/미러링 된 수많은 애플리케이션 서버 중의 하나로 연결하고 서버의 응답을 다시 클라이언트로 보낸다(요청을 적절히 분배해주는 일)
3. 웹 애플리케이션 서버
- 사용자의 요청이 들어오면 핵심 비즈니스 로직을 실행하고 그 결과를 HTML에 담아 브라우저로 보낸다
- 앱 서버 구현은 특정 언어를 선택하고 그에 맞는 웹 MVC 프레임워크를 선택
4. 데이터베이스 서버
모든 모던 웹 애플리케이션은 정보를 저장하기 위해 한 개 이상의 데이터베이스를 사용
- SQL과 NoSQL
- SQL은 “Structured Query Language”의 약자
- 만약 SQL에 대해서 잘 알지 못한다면 나는 Khan Academy에서 찾을 수 있는 것같은 같은 튜토리얼을 공부하길 강력히 권한다
- NoSQL, “Non-SQL”의 약자
- 대규모 웹 애플리케이션에 의해 생성되는 많은 양의 데이터를 처리하기 위해 등장한 최신 데이터베이스 기술의 집합
- https://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html 참고
- https://www.mongodb.com/resources 참고
5. 캐싱 서비스
- 캐싱 서비스는 정보를 (거의 O(1) 시간 안에) 찾을 수 있는 단순한 키/값 데이터 저장소를 제공한다.
- 0(1) :https://stackoverflow.com/questions/697918/what-does-o1-access-time-mean/697935#697935
- 애플리케이션은 캐싱 서비스를 통해 자원이 많이 소모되는 연산의 결과를 다시 계산하지 않고 캐시에서 가져옴으로써 효율을 높인다
- 애플리케이션은 데이터베이스의 쿼리 결과, 외부 서비스 호출 결과, 주어진 URL의 HTML 등을 캐시에 저장
- 가장 널리 사용되는 캐싱 서버 기술 2개는 Redis와 Memcache다
6. 잡 큐(job queue) & 서버
- 거의 모든 웹 애플리케이션은 사용자의 요청에 대한 응답과는 직접적인 관련이 없는 작업을 백그라운드에서 비동기적으로 실행할 필요가 있다
- 비동기적인 작업을 가능하게 하는 여러 가지 아키텍쳐가 있지만 가장 널리 사용되는 것은 “잡 큐” 아키텍처다
- 2개의 컴포넌트로 구성 : “잡”으로 이루어진 큐, 그리고 큐에 들어있는 잡을 실행하는 1개 이상의 잡 서버
- 잡 큐는 비동기적으로 실행될 잡 목록을 저장하고 있다
- (큐 : 자료구조 : https://ko.javascript.info/array#ref-1538)
- 잡 서버는 잡을 처리 한다. 그들은 잡 큐를 가져와서 할 일이 있는지 확인하고, 있다면 큐에서 잡을 뽑아내서 실행한다. 잡 서버로 사용할 수 있는 언어와 프레임워크는 너무나 다양하다
7. 전체 텍스트 검색 서비스
- 많은 웹 앱이 사용자가 텍스트 입력(보통 ‘쿼리’라고 불리는)을 입력을 하면 검색을 하고 가장 ‘관련 있는’ 결과를 보여주는 기능을 제공
- 전체 텍스트 검색은 쿼리 키워드를 포함하는 문서를 빠르게 찾기 위해 역 인덱스(inverted index)를 활용
- 어떤 데이터베이스에서는 전체 텍스트 검색을 바로 사용할 수 있지만(MySQL은 전체 텍스트 검색을 지원), 보통 역 인덱스를 연산하고 쿼리 인터페이스를 제공하는 “검색 서비스”를 분리해서 운영하는 사례가 많다
- 가장 인기 있는 전체 텍스트 검색 플랫폼은 Elasticsearch
8. 서비스
- 앱이 특정 규모에 도달하면 별도의 애플리케이션으로 분리해서 운영하기 위핸 ‘서비스’가 생기게 된다
- 계정 서비스 : 우리의 모든 사이트의 사용자 정보를 저장해서 교차 판매 기회를 더 쉽게 제공하고, 더 일관적인 사용자 경험을 가능하게 한다.
- 컨텐츠 서비스 : 우리의 모든 비디오, 오디오, 이미지의 메타데이터를 저장한다. 또 콘텐츠 다운로드 인터페이스와 다운로드 이력을 보여주는 기능을 제공한다.
- 결제 서비스 : 고객이 카드로 결제할 수 있는 인터페이스를 제공한다.
- HTML → PDF 서비스 : HTML을 PDF로 변환하는 간단한 인터페이스를 제공한다.
9. 데이터
- 특정 규모에 도달하면 데이터를 제어, 저장, 분석하기 위해 데이터 파이프라인을 사용한다. 전형적인 파이프라인은 3개의 주요 단계를 가진다.
- 사용자 상호작용으로 발생한 데이터를 데이터 ‘firehose’라 불리는 곳으로 전달, 데이터를 받아들이고 처리할 수 있는 스트리밍 인터페이스를 제공, 가공되지 않은 원시 데이터는 변형되거나(transformed) 추가 정보와 함께(augmented) 다른 firehose로 전달. AWS Kinesis와 Kafka는 이러한 작업을 위한 대표적인 기술
- 원시 데이터와 최종 데이터는 모두 클라우드 스토리지에 저장. AWS Kinesis는 원시 데이터를 AWS의 클라우드 스토리지(S3)에 저장할 수 있도록 매우 쉽게 사용할 수 있는 ‘firehose’로 불리는 설정을 제공한다
- 변형/추가된 데이터는 종종 분석을 위해 데이터 웨어하우스(DW)에서 로드된다. 우리는 AWS Redshift를 사용한다. 큰 기업에서는 Oracle이나 기타 독점적인 웨어하우스 기술을 사용하고 있지만, 스타트업 업계에서는 RedShift를 많이 사용하고 있으며 점유율도 계속 오르고 있다. 만약 데이터가 충분히 축적되었다면 Hadoop같은 NoSQL MapReduce 기술이 분석을 위해 필요하게 될 것이다.
10. 클라우드 스토리지
“클라우드 스토리지는 인터넷을 통해 데이터를 저장, 접근, 공유할 수 있는 단순하고 확장성 있는 방법”이다. 당신은 로컬 파일 시스템에 저장할 수 있는 거의 모든 것을 RESTful API를 사용해서 HTTP를 통해 클라우드에 저장하고 접근할 수 있다. 아마존의 S3는 현재로써는 가장 인기 있는 클라우드 스토리지
11. CDN
- CDN은 ‘Content Delivery Network’의 약자
- 정적인 데이터를 웹을 통해 1개의 원본(origin) 서버를 사용하는 것보다 더 빠르게 제공하기 위한 기술
- 콘텐츠를 전 세계의 많은 ‘엣지(edge)’ 서버에 분산시킴으로써 동작
- 사용자는 데이터를 원본 서버 대신 가장 가까운 엣지 서버에서 다운로드
출처 : https://www.creative-artworks.eu/why-use-a-content-delivery-network-cdn/
출처 : https://blog.rhostem.com/posts/2018-07-22-web-architecture-101

Hi there 👋 i'm backend developer