문자열이 메모리에 저장되는 방식 실험해보기
CS50 강의를 듣던 중, 메모리에 문자열이 저장되는 방식이 꽤나 흥미로웠다.
string, 즉 문자열은 문자로 이루어진 배열이다.
names라는 배열을 만든 후에 "EMMA" 라는 값을 한 인덱스 안에 넣어주면,
해당 문자열의 길이는 4자리가 될 것이다.
그러나 실제로 차지하는 메모리는 4바이트가 아닌 5바이트인데,
그 이유는 데이터간의 구분을 위해 문자열의 마지막을 알리는 Null 종단 문자가 포함되기 때문이다.
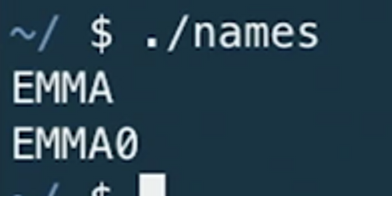
다음과 같이, 존재하지도 않을 거 같은 문자열의 5번째 자리를 int로 출력하면 0이 출력된다.
(C언어 기반)
string names[4];
names[0] = "EMMA";
names[1] = "RODRIGO";
names[2] = "BRIAN";
names[3] = "DAVID";
printf("%s\n", names[0]);
printf("%c%c%c%c%i\n", names[0][0], names[0][1], names[0][2], names[0][3], names[0][4]);결과:
names가 실제 메모리 상에 저장된 예시를 이해하기 쉬운 그림으로 표현하면 다음과 같다.

여기까지 듣고 내 노트북 메모리 속은 어떻게 생겼을지(?)가 궁금해져서 다음과 같은 코드를 짜서 확인해봤다.
대략적인 코드
int main(void)
{
string name[2];
name[0] = "EMMA";
name[1] = "JAMES";
printf("name[0] 위치 출력: ");
for (int i = 0; i < 4; i++)
{
if (name[0][i] == '\0'){
printf(" ");
} else{
printf("%c",name[0][i]);
}
}
printf("\n\n");
printf("name[1] 위치 출력: ");
for (int i = 0; i < 4; i++)
{
if (name[1][i] == '\0'){
printf(" ");
} else{
printf("%c",name[1][i]);
}
}
printf("\n");
}name[0][i]에는 E -> M -> M -> A -> ... 이 저장되어 있을 거고name[1][i]에는 J -> A -> M -> E -> S ... 가 저장되어 있을 거다.- 조건문을 달아서 null(
\0)이 있을 경우 띄어쓰기를 통해 구분되도록 했다.
- 4자리까지 찍어본 결과(위 코드):

- 30자리까지 찍어본 결과:

- 500자리까지 찍어본 결과(name[0][i]만 출력):
내 메모리 속에서, name[0]과 name[1]에 해당하는 위치에는
저런 순서로 character들이 저장되어 있는 거다!
재밌다

넓이에 깊이 더하기