문제 설명
- Table : ONLINE_SALE
Column
ONLINE_SALE_ID : 온라인 상품 판매 ID
USER_ID : 회원 ID
PRODUCT_ID : 상품 ID
SALES_AMOUNT : 판매량
SALES_DATE : 판매일
※ 동일한 날짜, 회원 ID, 상품 ID 조합에 대해서는 하나의 판매 데이터만 존재
- 동일한 회원이 동일한 상품을 재구매한 데이터를 구하여, 재구매한 회원 ID와 재구매한 상품 ID를 출력
결과는 회원 ID를 기준으로 오름차순 정렬! 회원 ID가 같다면 상품 ID를 기준으로 내림차순 정렬
1차
내가 생각한 알고리즘은 다음과 같다.
COUNT(USER_ID) > 1와COUNT(PRODUCT_ID) > 1를 동시에 만족하는 record를 찾는다.- 해당 record의 날짜와 일치하는 날짜의 USER, PRODUCT를 select하면 된다고 생각했다! 왜냐면 동일한 회원이 동일한 상품을 재구매한 날짜가 다르니까 하나의 user와 product만 수집하기 위해서! 데헤헷
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
WHERE SALES_DATE IN (
SELECT CASE WHEN (COUNT(USER_ID) > 1 AND COUNT(PRODUCT_ID) > 1) THEN SALES_DATE END
FROM ONLINE_SALE
)
ORDER BY USER_ID ASC, PRODUCT_ID DESC;
 적으면서 깨달았다.. 이건 완전 잘못된 알고리즘이라는 것을...
적으면서 깨달았다.. 이건 완전 잘못된 알고리즘이라는 것을...
문제 해결
나는 다음과 같은 문제를 간과했다. GROUP BY를 안 해준 것!!!!!
// GROUP BY 안 함
SELECT COUNT(USER_ID), USER_ID
FROM ONLINE_SALE;
// GROUP BY 해줌
SELECT COUNT(USER_ID), USER_ID
FROM ONLINE_SALE
GROUP BY USER_ID;위의 코드 결과는 각각 다음과 같다.

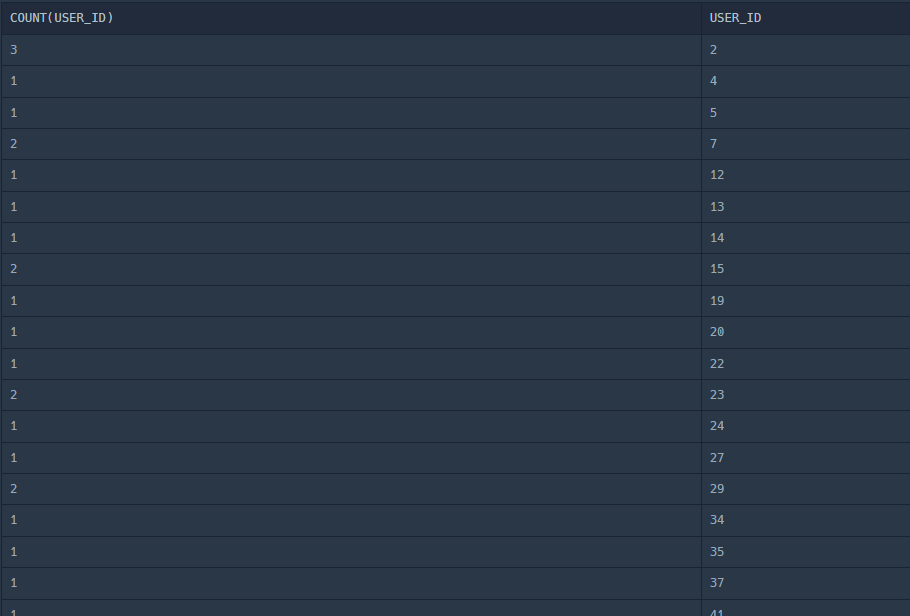
차이가 느껴지는가?! 즉 위의 코드(GROUP BY X)에서 COUNT(USER_ID)는 전체 record의 개수와 같고 USER_ID는 가장 첫 번째로 나오는 record의 USER_ID를 보여준다.
그러나 아래의 코드(GROUP BY O)에서 COUNT(USER_ID)는 USER_ID끼리 그룹을 묶고 해당 USER_ID의 개수를 보여준다. USER_ID는 해당 그룹의 USER_ID를 나타낸다
SELECT COUNT(USER_ID) > 1 AND COUNT(PRODUCT_ID) > 1 AS RESULT, USER_ID FROM ONLINE_SALE

따라서 COUNT(USER_ID) > 1 AND COUNT(PRODUCT_ID) > 1 부분은 122 > 1 AND 122 > 1 == True AND True == True(1) 의 의미와 동일하다.
즉, 나의 코드는
WHERE절에서CASE WHEN이 TRUE이므로 가장 첫 번째 record의 SALES_DATE를 얻는다.- 해당 SALES_DATE를 가지는 모든 record의 user_id, product id를 조사한다.

라는 엉뚱한 알고리즘이다..
2차
그럼 GROUP BY를 사용해볼까?!
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
WHERE USER_ID IN (
SELECT CASE WHEN COUNT(USER_ID) > 1 AND COUNT(PRODUCT_ID) > 1 THEN USER_ID END
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
)
ORDER BY USER_ID ASC, PRODUCT_ID DESC;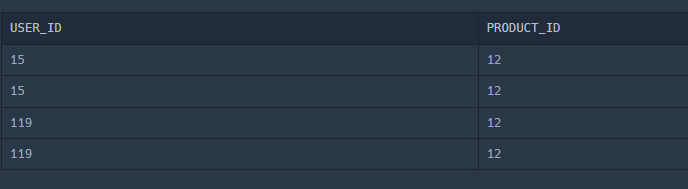 오호라! 재구매한 USER를 잘 구했으나 당연히 해당 USER_ID와 같은 모든 record를 리턴하기 때문에 중복되어 나타난다!!
오호라! 재구매한 USER를 잘 구했으나 당연히 해당 USER_ID와 같은 모든 record를 리턴하기 때문에 중복되어 나타난다!!
HAVING
SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s) HAVING condition ORDER BY column_name(s);
- HAVING 절은 where 절에 집계함수를 사용할 수 없기 때문에 사용하는 절이다! 즉 집계함수를 통해 record를 필터링하고 싶다면 HAVING을 사용하면 된다고!!
- 또한 HAVING 절은 GROUP BY로 묶여진 그룹에 대해 필요한 데이터만 뽑는 구문이다!!
잠깐!!
WHERE= 행별, 개별 조건
HAVING= 그룹별, 그룹 조건
3차
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(PRODUCT_ID) > 1
ORDER BY USER_ID ASC, PRODUCT_ID DESC;해당 알고리즘은 GROUP BY USER_ID, PRODUCT_ID를 통해서 USER_ID가 같은 것끼리 그룹화 하고 그 중에서 PRODUCT_ID가 같은 것끼리 그룹화를 한다. 이후에 PRODUCT_ID의 개수가 2개 이상인 그룹의 USER_ID와 PRODUCT_ID를 조사한다.

