
이전포스팅에 이어서 웹 생태계를 파악하는 포스트입니다.
V8 엔진이 어떻게 일을 하는지 기록을 남기려고 한다.
한번 읽어봤지만 내용이 간단하지않아서 나중에 또 볼 수 있는 문서를 만드는것이 목적이다.
로고가 가슴이 웅장해진다..
Github Mirror : https://github.com/v8/v8
V8 엔진이란?
구글에서 C++로 작성한 고성능 JS & WASM 엔진이다. 킹왕짱이다.
Chrome 과 Node.js 그외에 곳에서 사용되고 있고,
ECMAScript 와 Web Assembly 표준에 맞게 구현했다. ( 여기서 ECMAScript는 스크립팅 언어 표준인데, 매우 중요하다. 다음에 덧붙일 예정 )
- C++ 로 작성된 자바스크립트 엔진이다.
- Chakra(MS), SpiderMonkey(Mozilia) 보다 범용성이 좋은 엔진이다.
- 자바스크립트를 해석하여, 컴파일러와 인터프리터를 통해 컴퓨터가 이해할수있는 Low Level 언어로 변환해준다.
- Javascript 기반으로 C++ 서버 프로그래밍을 할 수도 있다. C++로 작성하면 더 빠른코드(File I/O) 일경우 C++로 선언해놓고, 자바스크립트에서 동작을 실행할 수 있다. ( 이미 이렇게 되어있는것으로 알고있다. )
- 각각의 feature 를 담당하는 단위가 실제 자동차엔진과 동일한 용어를 사용한다. (Ignition, TurboFan)
재밌다
Javascript 와 Web Assembly (wasm) 상세한 내용은 아래에 정리해봤다.
https://velog.io/@juhojung/WebAssembly-VS-Javascript
V8 엔진이 구동되는 순서를 간단하게 보여준 이미지다.
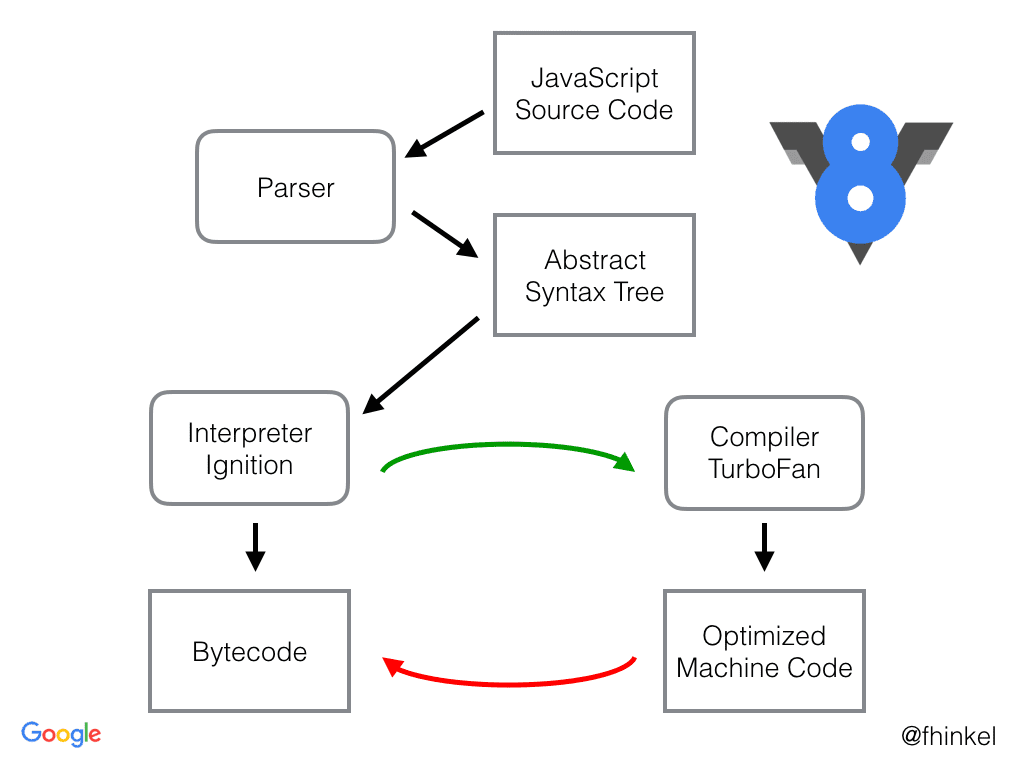
아래 링크에서 V8 엔진의 역사와 현재의 형태에 대한 summary 를 볼 수 있다.
https://docs.google.com/presentation/d/1chhN90uB8yPaIhx_h2M3lPyxPgdPmkADqSNAoXYQiVE/edit#slide=id.g18d89eb289_1_431
1. Parser ( Make AST )
이부분은 상당히 브라우저렌더링 방식과 유사하다.
JS로 되어있는 소스코드를 Parser 가 넘겨받는다. Parser 는 코드를 해석하여 AST(추상 구문 트리) 를 생성해준다. ( 마치 HTML 을 파싱하여 DOMTree 를 만들어주는 HTML Parser 와 유사하다. )
이 과정에서 우리가 let, const 처럼 지역변수 함수 등을 스코프별로 나눠지고 사용하는것들의 스코프가 정해진다.
컴퓨터가 이해하기 쉽도록 트리형태로 이루어진 구조를 만드는 과정이다. (컴파일러 구문해석과 동일)
2. Ignition ( Make Bytecode )

Ignition, 번역하면 점화 라는 뜻이다. 뭘 점화하는가?
High Level 소스코드를 가상머신이 이해하기 쉽게 중간코드로(기계어보다는 추상적이다.) 변환하는것으로, 내 소스코드에 불을 지펴서 시동을 거는 과정이다.
특징으로 컴파일 방식이 아닌 인터프리터 방식이다. Ignition 의 장점은 다음과 같다.
- 메모리 사용량 감소 : JS 를 기계어로 한번에 컴파일 하는것보다 바이트코드로 변환하는것이 메모리 점유율이 낮다.
- 파싱시 오버헤드 감소 :
먼저 오버헤드란 사용하려는 기능과 별개로 간접적인 요소(코드)로 인해 필요하게되는 자원이다.
바이트코드는 재 파싱시 오버헤드가 적다고한다.. - 컴파일 파이프 라인의 복잡성 감소.
Optimizing이든Deoptimizing이든 바이트 코드 하나만 생각하면 되기 때문에 편하다.
마지막으로 바이트코드를 NodeJS 에서 출력하는 방법 (이해를 못해도 순서를 봐보면 궁금해서라도 찾게되더라)
$ node --print-bytecode index.js
3. TurboFan ( cooling & optimizing )

TurboFan 은 최적화 담당 컴파일러이다. 기존에 Crankshaft 컴파일러를 대체한 최적화 컴파일러이다.
지속적인 확장을 위해 여러 레이어로 계층화 해서 유연하게 확장이 용이하도록 설계한것이다.
V8은 런타임 중에 Profiler 라는 기능을 하는 도구가 여러 데이터를 수집한다. (함수 호출등)
수집한 데이터를 TurboFan 이 받아서 코드를 최적화한다.
최적화 기법은
히든클래스(Hidden Class) : 데이터를 사용하는 부분에 있어서 데이터를 직렬화하고, 데이터의 위치정보(property)는 따로 만들어서 최적화한다.
인라인 캐싱(Inline Caching) : 효율성을 위해 데이터 재사용을 하는 캐싱기능과 동일하다. 동일한 객체가 계속 리턴되는 함수가 있다면, 해당 함수를 optimized code 로 만들어서 쓰기 편하게 리턴되는 객체자체로 변환한다.
등이 있다.
최적화를 적용하는 기준은
kHotAndStable은 코드가 뜨겁고 안정적이라는 것인데, 쉽게 말하면 자주 호출되고(뜨겁고) 코드가 안 변함(안정적)이라는 것이다. 매번 같은 행동을 수행하는 반복문 내에 있는 코드 같은 경우가 여기에 해당하기 쉽다.
kSmallFunction은 말 그대로 인터프리팅된 바이트 코드의 길이를 보고 특정 임계점을 넘기지 않으면 작은 함수라고 판단해서 최적화를 진행하는 것이다. 작고 단순한 함수는 크고 복잡한 함수보다 동작이 매우 추상적이거나 제한적인 확률이 높기 때문에 안정적이라고 볼 수 있다.
이렇게 있는데 실제로, 적용되는걸 확인해보자.
$ node --trace-opt index.js
터보팬이 하는 일을 미루어서 코드를 최적화하는것과 연결지어서 쓸수있다. 아래코드를 보자.
Inline Caching 의 경우
function findUser(username : string){
return `OH Find User! ${username} `;
}
findUser("Juho");위 상태에서 보면, findUser("Juho")라인은 계속 동일한 리턴값이다.
따라서 TurboFan 은 "OH Find User! Juho" 로 문자열을 대체한다.
Hidden Class 의 경우
case A
let a = {type : "fruit", str : "apple"}
let b = {type : "fruit", str : "banana"}
let c = {type : "fruit", str : "cherry"}
-----------------------------------------
case B
let a = {type : "fruit", str : "apple"}
let b = {type : "fruit", str : "banana"}
let c = {str : "cherry", type : "fruit"}케이스 A와 B 중 더 오래걸리는건 B이다. Hdden Class 는 케이스 A일 경우 type과 str 키를 빼고 일렬로 정렬하여 정의하고, property 정보를 따로 저장한다.
Property
property information 1 = {
첫 번째 값(type) 위치
...
}
property information 2 = {
두 번째 값(str) 위치
...
}variable 정의
let a = {"fruit", "apple"}
let b = {"fruit", "banana"}
let c = {"fruit", "cherry"}이렇게 오브젝트의 키가아닌 위치로 접근하게 된다.
그러나 케이스 B는 str과 type의 위치가 다른 c가 있기때문에 히든클래스를 더 생성해야하고, 그로인해 더 느려진다. 오오
결론
- V8 엔진이 예전에 비해 많이 간소화, 최적화 되서 멀리서보면 디벨롭하는데 편해졌다.
- 실제로 프로그래밍 하는데에 직접적인 영향은
TurboFan을 보는게 좋아보인다. (최적화와 직접적인 연관이있기에.) - 테스트코드 작성하면서 흐름을 눈으로 보는게 확실하다.
참고자료
https://evan-moon.github.io/2019/06/28/v8-analysis/
https://velog.io/@gay0ung/V8-엔진이-JS를-기계-코드로-바꾸는-방법
https://v8.dev/
