명령어
학습 목표
- 고급 언어와 저급 언어의 차이를 이해한다.
- 컴파일 언어와 인터프리터 언어의 차이를 이해한다.
- 명령어를 구성하는 연산 코드와 오퍼랜드에 대해 학습한다.
- 명령어의 주소 지정 방식에 대해 학습한다.
소스 코드와 명령어
핵심 키워드 :
고급 언어저급 언어기계어어셈블리어컴파일 언어인터프리터 언어
고급 언어와 저급 언어
컴퓨터는 C, C++, JAVA와 같은 프로그래밍 언어를 이해할 수 있을 것 같지만, 그렇지 않다.
컴퓨터가 이해할 수 있는 언어는 저급 언어이기 때문에 컴퓨터 내부에서 고급 언어에서 저급 언어로 변환되는 과정이 필요하다.
- 고급 언어 : 사람이 이해하고 작성하기 쉽게 만든 언어
- 대부분의 프로그래밍 언어
- 저급 언어 : 컴퓨터가 이해하고 실행할 수 있는 언어
- 기계어
- 0과 1의 명령어 비트로 이루어진 언어
- 기계어가 무엇을 뜻하고, 컴퓨터를 어떻게 작동시키는지 언어만 보고 파악하기 어려움
- 어셈블리어
- 0과 1로 이루어진 기계어를 읽기 편한 형태로 번역한 저급 언어
- 기계어
💡) 저급 언어 왜 알아야 할까?
개발자가 어셈블리어를 이용해 복잡한 프로그램을 만드는 것은 어렵지만, 하드웨어와 밀접하게 맞닿아 있는 프로그램을 개발하는 임베디드 개발자, 게임 개발자, 정보 보안 분야 등은 어셈블리어를 많이 이용한다. 어떤 개발자가 되길 희망하는지에 따라 중요성이 달라진다.
또한 어셈블리어를 읽으면 컴퓨터가 프로그램을 어떤 과정으로 실행하는지, 프로그램이 어떤 절차로 작동하는지 근본적인 단계에서 하나하나 추적하고 관찰 할 수 있다.
컴파일 언어와 인터프리터 언어
개발자들이 고급 언어로 작성한 소스 코드는 결국 저급 언어로 변환되어 실행된다. 고급 언어를 저급 언어로 변환되는 방식에는 크게 두 가지 방식이 있다.
- 컴파일 언어
- 컴파일러에 의해 전체 코드가 저급 언어로 변환되어 실행되는 고급 언어
- 소스 코드 내에서 오류를 하나라도 발견하면 소스 코드 전체가 실행되지 않음
- 컴파일러 : 컴파일을 수행해주는 도구
- 목적 코드 : 컴파일러를 통해 저급 언어로 변환된 코드
- 인터프리터 언어
- 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어
- 소스 코드 전체를 저급 언어로 변환하는 시간을 기다릴 필요 없음
- 소스 코드 내에서 오류가 있으면, 오류 발생 전까지의 코드는 실행되고, 오류가 있는 코드 이후의 시점부터 코드가 실행되지 않음
💡) 컴파일 언어와 인터프리터 언어는 정확하게 구분될까?
명확하게 구분되는 언어도 있지만, 경계가 모호한 경우가 많다. 하나의 프로그래밍 언어가 반드시 둘 중 하나의 방식만으로 작동한다고 생각하는 것은 오개념이다. 컴파일이 가능한 언어라고 해서 인터프리트가 불가능하거나, 인터프리트가 가능하다고 해서 컴파일이 불가능한 것은 아니다.
두 언어를 정확하게 구분하는 것보다, 고급 언어가 저급 언어로 변환되는 대표적인 방법에 두 가지 방식이 있다고 이해하는 것이 좋다.
💡) 목적 파일과 실행 파일
목적 코드로 이루어진 파일을 목적 파일, 실행 코드로 이루어진 파일을 실행 파일이라고 한다.
목적 코드는 저급 언어이기 때문레, 목적 코드가 실행 파일이 되기 위해서는 링킹 이라는 작업을 거쳐야 한다. 링킹은 여러 개의 코드와 데이터를 모아서 연결하여, 메모리에 로드될 수 있고 실행될 수 있는 한 개의 파일로 만드는 작업이다.
어떤 프로그램을 위한 두 개의 소스 코드를 만들었다고 했을 때, 소스 코드 1에 없는 외부 기능인 소스 코드2에 있는 관련 기능을 연결 짓는 작업을 말한다.
명령어의 구조
핵심 키워드 :
명령어연산 코드오퍼랜드주소 지정 방식
연산 코드와 오퍼랜드
명령어는 '무엇을 대상으로, 어떤 작동을 수행하라'는 구조로 되어 있다. 명령어는 연산 코드와 오퍼랜드로 구성되어 있다.
- 연산 코드 : 명령어가 수행할 연산
- 연산 코드의 종류와 생김새는 CPU마다 다르고, 매우 많지만, 크게 네 가지로 나눌 수 있음
- 연산 코드 종류
- 데이터 전송
- MOVE : 데이터를 옮겨라
- STORE : 메모리에 저장해라
- LOAD(FETCH) : 메모리에서 CPU로 데이터 가져와라
- PUSH : 스택에 데이터 저장해라
- POP : 스택의 최상단 데이터를 가져와라
- 산술/논리 연산
- ADD/SUBTRACT/MULTIPLY/DIVIDE : 덧셈/뺼셈/곱셈/나눗셈을 수행하라
- INCREMENT/DECREMENT: 오퍼랜드에 1을 더하라/오퍼랜드에 1을 뺴라
- AND/OR/NOT : 해당 연산을 수행하라
- COMPARE : 두 숫자 혹은 TRUE/FALSE 값을 비교하라
- 제어 흐름 변경
- JUMP : 특정 주소로 실행 순서를 옮겨라
- CONDITIONAL JUMP : 조건에 부합할 때 특정 주소로 실행 순서를 옮겨라
- HALT : 프로그램의 실행을 멈춰라
- CALL : 되돌아올 주소를 저장할 채 특정 주소로 실행 순서를 옮겨라(함수 호출)
- RETURN : CALL을 호출할 때 저장했던 주소로 돌아가라(리턴)
- 입출력 제어
- READ(INPUT) : 특정 입출력 장치로부터 데이터를 읽어라
- WRITE(OUTPUT) : 특정 입출력 장치로 데이터를 써라
- START IO : 입출력 장치를 시작하라
- TEST IO : 입출력 장치의 상태를 확인하라
- 데이터 전송
- 오퍼랜드 : 연산에 사용할 데이터, 연산에 사용할 데이터가 저장된 위치
- 숫자, 문자등을 나타내는 데이터 또는 메모리나 레지스터 주소가 올 수 있음
- 대부분 저장된 위치가 담기기 때문에, 주소 필드라고 부름
- 명령어 안에 하나도 없을 수도 있고, 여러 개가 있을 수도 있음(0-주소 명령어, 1-주소 명령어, 2-주소 명령어, 3-주소 명령어)
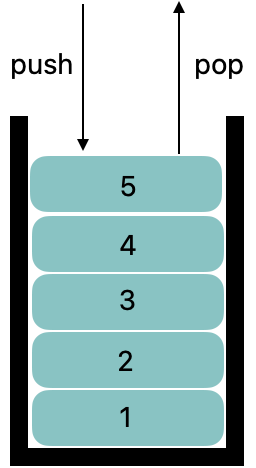
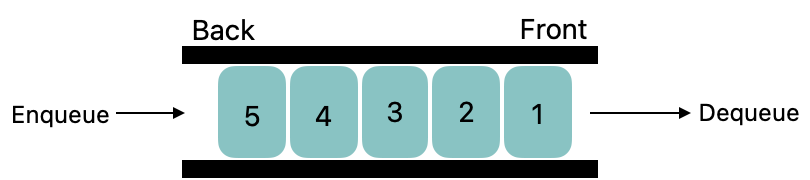
💡) 스택과 큐
스택은 한쪽 끝이 막혀 있는 통과 같은 저장 공간을 말한다. 막혀있지 않은 쪽으로 데이터를 쌓아 저장하고, 저장한 자료를 빼낼 때는 마지막으로 저장한 데이터부터 빼낸다.(LIFO) 예를 들어, 1-2-3-4-5 순으로 데이터를 저장하면, 빼낼 때는 5-4-3-2-1순으로 빼낸다.
큐는 스택과는 달리 양쪽이 뚫려 있는 통과 같은 저장 공간이다. 한쪽으로는 데이터를 저장하고, 다른 한쪽으로는 먼저 저장한 순서대로 데이터를 빼낸다.(FIFO)
주소 지정 방식
오퍼랜드 필드에 메모리나 레지스터의 주소를 담는 이유는 명령어의 길이 때문이다. 연산 코드와 오퍼랜드로 표현할 수 있는 비트의 수가 크지 않기 때문에 메모리나 레지스터 주소를 담아 데이터의 크기에 상관 없이 표현한다.
- 유효 주소 : effective address, 연산에 사용할 데이터가 저장된 위치
- 주소 지정 방식 : addressing mode, 연산에 사용할 데이터 위치를 찾는 방법
- 즉시 주소 지정 방식 : immediate addressing mode
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식(가장 간단한 형태)
- 연산에 사용할 데이터의 크기가 작아질 수 있음
- 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는 과정이 없기 때문에 빠름
- 직접 주소 지정 방식 : direct addressing mode
- 오퍼랜드 필드에 유효 주소 직접적으로 명시하는 방식
- 즉시 주소 지정 방식보다 데이터 크기가 커짐
- 유효 주소를 표현할 수 있는 크기가 연산 코드만큼 줄어듦(유효 주소에 제한이 생길 수 있음)
- 간접 주소 지정 방식 : indirect addressing mode
- 오퍼랜드 필드에 유효 주소의 주소를 명시
- 두 번의 메모리 접근 필요
- 앞선 주소 지정 방식들에 비해 속도가 느림
- 레지스터 주소 지정 방식 : register addressing mode
- 연산에 사용할 데이터가 저장된 레지스터를 오퍼랜드 필드에 직접 명시하는 방식
- 메모리(CPU 외부)에 접근하는 속도보다 레지스터(CPU 내부)에 접근하는 것이 빠름
- 직접 주소 방식과 비슷한 문제 공유
- 레지스터 간접 주소 지정 방식 : register indirect address mode
- 연산에 사용할 데이터를 메모리에 저장하고, 그 주소를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법
- 간접 주소 지정 방식과 비슷하지만, 메모리 접근하는 횟수가 한 번으로 줄어듦
- 즉시 주소 지정 방식 : immediate addressing mode
* 나중에 복습하면서 주소 지정 방식 그림으로 그려보기