Concordance Coefficient Correlation(CCC)란?
Concordance Coefficient Correlation(CCC)는 affect recognition에서 주로 쓰이는 평가 metric이다.
원래 어떤 상황에 쓰이는가??
예를 들어 연구자가 학생 100명의 키를 두번에 걸쳐 계측했다고 하자. 어떤 학생들에 대해서는 1차 2차 시기의 계측값이 똑같을 수도 있겠지만 아마 대부분의 학생들의 경우 1차 2차 시기의 계측값이 최소한 0.1mm 정도는 차이가 있을 것이라고 예상이 된다. 이 때 연구자의 질문은 이렇다. 1차, 2차 시기의 계측값이 어느 정도 일치(concordance)할까? 1차 2차 시기의 계측값 차이가 통계적으로 유의한지, 즉 심각한 상황인지 확인할 수 있는 방법은 없을까? 이에 대한 답을 줄 수 있는 계수는 다음과 같다.

그러면 affect recognition에서는 왜 쓰이는가? (with chatGPT)
Affective computing에서 arousal와 valence에 대한 Concordance Correlation Coefficient (CCC)를 loss function으로 사용하는 이유는 주로 다음과 같다.
감정 강도 측정의 정확도: CCC는 감정 강도를 측정하기 위한 효과적인 메트릭 중 하나로 간주된다. 이는 arousal와 valence와 같은 감정 차원의 정확한 측정을 목표로 하는 affective computing 작업에 유용함
감정 데이터의 분포 보존: CCC는 예측 값과 실제 값 사이의 관계를 평가하는 데 사용되며, 분포, 분산 및 평균과 같은 통계적 특성을 고려한다. 따라서 CCC를 사용하면 모델이 감정 데이터의 분포를 보다 잘 보존하도록 도와줌.
로버스트한 평가 지표: CCC는 이상치나 노이즈에 상대적으로 로버스트한 평가 지표다. 이는 감정 데이터가 주로 주관적이며 주관적인 특성 때문에 노이즈나 이상치가 있을 수 있기 때문에 중요하다.
비교적 직관적인 해석: CCC는 -1에서 1까지의 범위에서 값을 가지며, 값이 1에 가까울수록 예측과 실제 간의 높은 일치를 나타낸다. 이는 연구자나 실무자가 모델의 성능을 상대적으로 직관적으로 해석할 수 있게 해준다.
따라서 CCC는 arousal와 valence에 대한 감정 예측 모델의 성능을 평가하고 개선하기 위한 효과적인 loss function으로 사용된다.
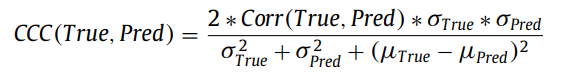
: 평균
: 분산
: 피어슨 상관계수(두 변수간 상관계수)
논문에서 쓰인 CCC는 negative CCC로써 1-가 붙지 않았는데, 다른 논문에서는 다시 1-를 붙이는 일반적인 CCC를 쓰는 것 같기도하다. 이에 대해서는 나중에 다시 정리하자.
피어슨 상관계수란?
통계학에서 , 피어슨 상관 계수(Pearson Correlation Coefficient ,PCC)란 두 변수 X 와 Y 간의 선형 상관 관계를 계량화한 수치다. 피어슨 상관 계수는 코시-슈바르츠 부등식에 의해 +1과 -1 사이의 값을 가지며, +1은 완벽한 양의 선형 상관 관계, 0은 선형 상관 관계 없음, -1은 완벽한 음의 선형 상관 관계를 의미한다. 일반적으로 상관관계는 피어슨 상관관계를 의미하는 상관계수이다.
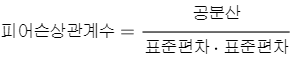
따라서
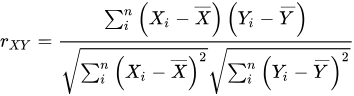
공분산이란?
어떤 특정 샘플의 X라는 특징이 x의 평균 보다 크고, 그 샘플의 Y라는 특징이 y의 평균 보다 크다면, 둘 다 양수가 될 것이다.
그 말은 X가 큰 값을 가질 때 Y도 큰 값을 가진다는 의존성을 보여준다.
이러한 경향이 크게 나타난다면, 자연스럽게 반대 방향도 함께 일어난다.
반대 방향이라는 것은 X가 작은 값을 가질 때는 자연스럽게 Y의 작은 값이 된다.
이 때에도 마찬가지로 편차의 곱은 양수가 된다.
왜냐하면 "음수 x 음수 = 양수" 이기 때문이다.
자, 그러면 이러한 상태가 되면 평균을 취하게 되면 큰 양수 값이 나올 것이다. 그렇단말은 정의에 의해서 X와 Y 사이의 의존성이 높다는 것이다.
X와 Y가 의존성이 높다는 것은 그렇다면 뭘 의미할까?
앞에서도 설명했듯이, X가 증가할 때, Y도 증가하려고 하고, X가 감소할 때, Y도 감소하려고 하는 것이다. 따라 하니깐, 의존성이 높은 거다.
피어슨상관계수와 공분산
간단히 말하면, 공분산은 두 변수 간의 변화량을 직접 비교하고, 피어슨 상관계수는 그 관계의 강도와 방향을 표준화하여 나타낸다.
참고
- Leveraging recent advances in deep learning for audio-Visual emotion 논문 (수식)
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=lucifer246&logNo=220770125445 (CCC 참고)
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=yangseung77&logNo=90177099354 (CCC 참고)
- https://ko.wikipedia.org/wiki/%ED%94%BC%EC%96%B4%EC%8A%A8_%EC%83%81%EA%B4%80_%EA%B3%84%EC%88%98 (피어슨 상관계수 참고)
- https://blog.naver.com/sw4r/221025662499 (공분산 참고)
