Today I learned
2022/02/03
회고록
2/01
항해 99, 알고리즘 3주차
교재 : 파이썬 알고리즘 인터뷰 / 이것이 코딩테스트다(동빈좌)
병합/퀵정렬(Sort)
1. 이론
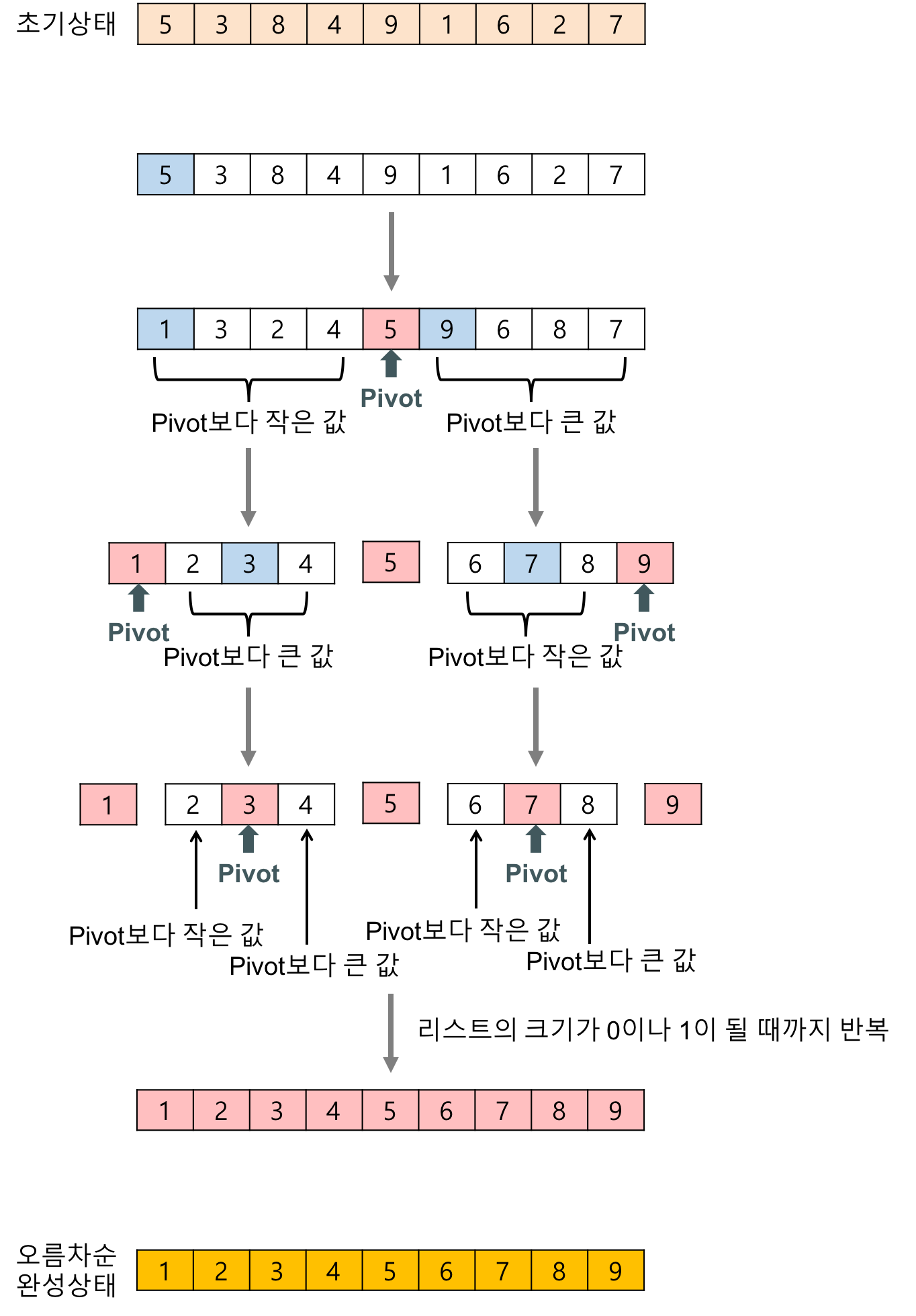
퀵정렬
퀵 정렬(quick sort) 알고리즘의 구체적인 개념
하나의 리스트를 피벗(pivot)을 기준으로 두 개의 비균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
퀵 정렬은 다음의 단계들로 이루어진다.
분할(Divide): 입력 배열을 피벗을 기준으로 비균등하게 2개의 부분 배열(피벗을 중심으로 왼쪽: 피벗보다 작은 요소들, 오른쪽: 피벗보다 큰 요소들)로 분할한다.
정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복 방법을 적용한다.
결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
순환 호출이 한번 진행될 때마다 최소한 하나의 원소(피벗)는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
병합정렬
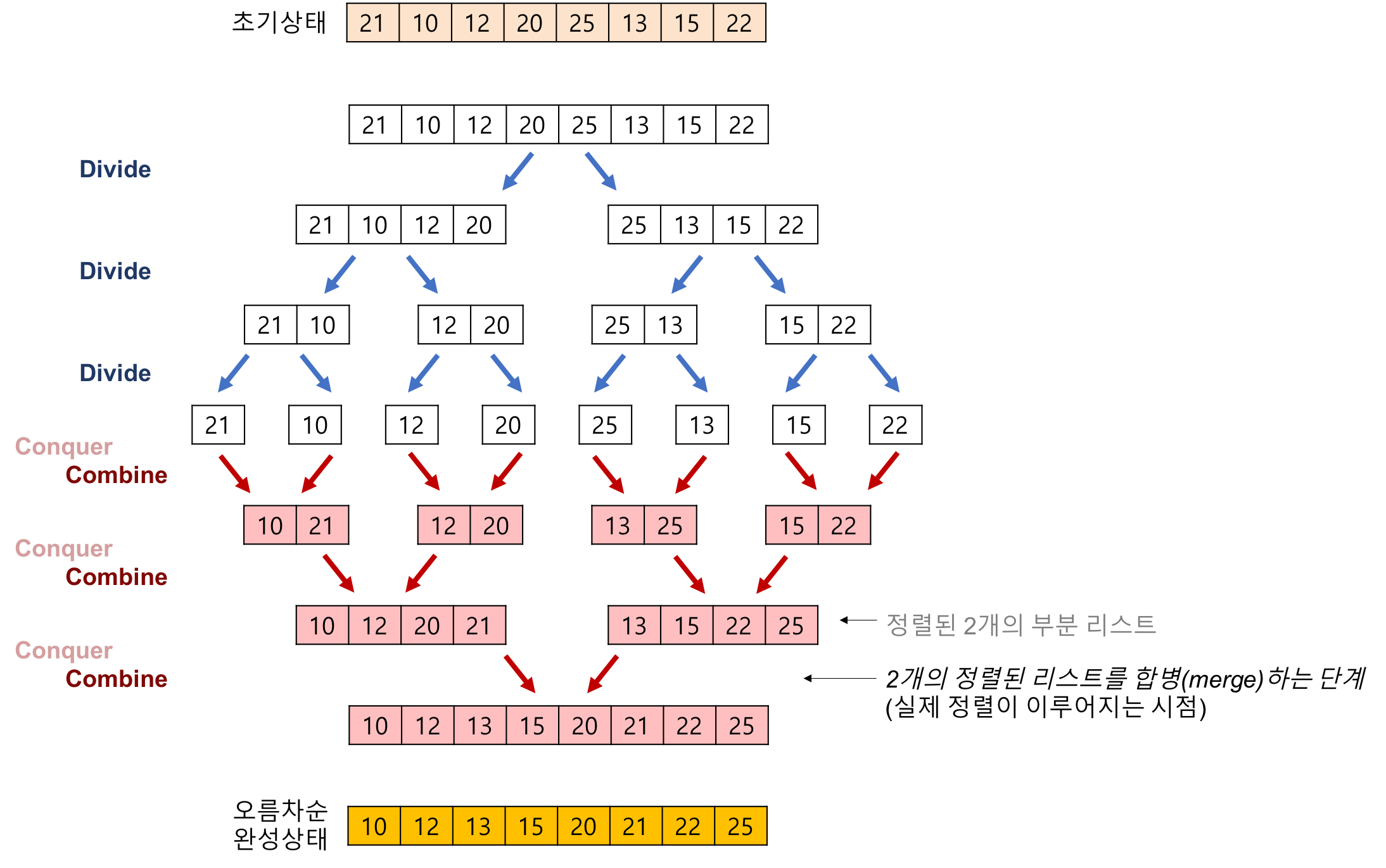
합병 정렬(merge sort) 알고리즘의 구체적인 개념
하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
합병 정렬은 다음의 단계들로 이루어진다.
분할(Divide): 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복 방법을 적용한다.
결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
합병 정렬의 과정
추가적인 리스트가 필요하다.
각 부분 배열을 정렬할 때도 합병 정렬을 순환적으로 호출하여 적용한다.
합병 정렬에서 실제로 정렬이 이루어지는 시점은 2개의 리스트를 합병(merge)하는 단계 이다.
2. 문제
- 파일명 정렬
https://programmers.co.kr/learn/courses/30/lessons/17686
- 더 맵게
https://programmers.co.kr/learn/courses/30/lessons/42626
3. MySol
- 파일명 정렬
def solution(files):
#이분탐색으로 head와 num을 구분한다. - 불가
#divide and conquer - 이유없음
#str.index() 함수 사용 - 범위적용 안됨
#그냥 for문
result = []
for file in files:
headIdx = 0
head = ''
number = ''
tail = ''
for i in range(len(file)):
if not headIdx and file[i].isdigit():
head = file[:i]
headIdx = i
if headIdx and not file[i].isdigit():
number = file[headIdx:i]
tail = file[i:]
result.append([head, number, tail])
break
if headIdx and i==len(file)-1 and number=='':
number = file[headIdx:]
result.append([head, number])
print(f'{result}')
result = sorted(result, key = lambda x:(x[0].lower(), int(x[1])))
print(f'{result}')
return [''.join(file) for file in result]
if __name__ == '__main__':
#files = ["img12.png", "img10.png", "IMG02.png", "img1.png", "img01.GIF", "img2.JPG"]
test = ["a9","e10","a0011","b012","u13","w014"]
result = solution(test)
print(f'{result}')
- Scoville
import heapq
def solution(scoville, k):
if len(scoville)==1 or scoville is None:
return 0
heapq.heapify(scoville)
cnt = 0
while True:
try:
cnt+=1
lowest1 = heapq.heappop(scoville)
lowest2 = heapq.heappop(scoville)
newScoville = lowest1 + (lowest2*2)
heapq.heappush(scoville, newScoville)
if scoville[0] >= k:
break
except IndexError:
cnt = -1
break
return cnt
if __name__ == '__main__':
scoville = [1, 2, 3, 9, 10, 12]
k = 7
result = solution(scoville, k)
print(f'{result}')
4. 배운 점
- 파일명 정렬은 처음에 접근에 있어, 문자열의 숫자로 나뉘는 index를 어떻게 접근할 것인가가 관건이었다.
이분탐색을 해야하나, devide and conquer를 해야하나 고민하던 중, 내가 쓸데 없는 고민을 하고 있다는 사실을 뒤늦게 깨닫고 열심히 반복문을 돌리며 구현을 하였다.
- 파일명 정렬 문제의 핵심
1. head 구간, number 구간, tail 구간을 나누는 index를 구하는 로직 구현하기
2. 파이썬의 차순위 정렬 명령어를 알고 있는지 여부
result = sorted(result, key = lambda x:(x[0].lower(), int(x[1])))
3. 이제 이건 다들 알겠지 싶다.
return [''.join(file) for file in result]
- 더 맵게는 1-2년전에 풀어본 문제이기도 하고, 그리 난이도 높은 문제는 아니었다.
5. 총평
공부 잘 하고 있는지 스스로 점검할 수 있는 시간
