
배경
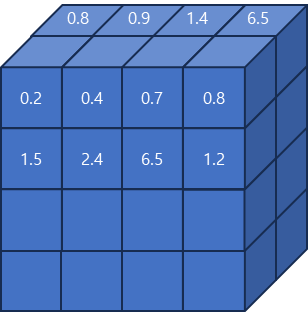
tensor는 메모리에 저장할 때 contiguous 형태로 저장되는데 NCHW는 채널단위로 각 픽셀의 값이 연속적으로 저장되고 NHWC는 픽셀 단위로 채널의 값이 연속적으로 저장된다.
- NCHW 방식의 메모리
[0.2 0.4 0.7 0.8 1.5 2.4 6.5 1.2 ... 0.8 0.9 1.4.6.5 ...]- NHWC 방식의 메모리
[0.2 0.8 0.4 0.9 0.7 1.4 0.8 6.5 ....]
tensor연산은 효율적인 연산을 위해 병렬적으로 수행된다. 따라서 실제 convolution과 같은 연산을 수행할 때 연산에 필요한 값을 벡터화한 후 연산을 수행하게 된다.
장점
채널 단위로 벡터화하여 연산이 수행되기 때문에 NHWC로 메모리에 저장하는 것이 메모리 엑세스 관점에서 효율적으로 되고 FP16일 때는 메모리 대역폭을 FP32보다 더욱 효율적으로 사용할 수 있기 때문에 가속에 큰 장점을 가진다.
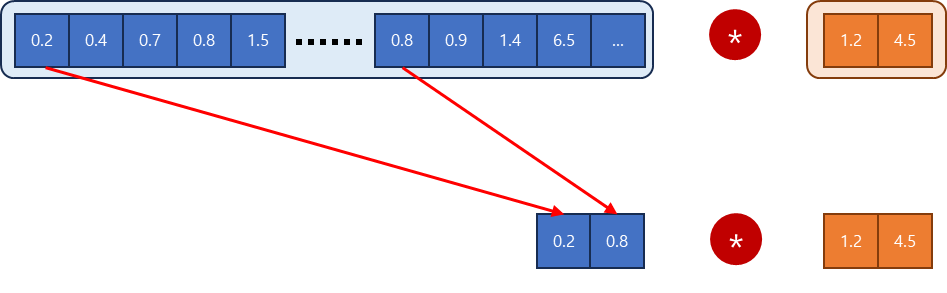
NCHW 경우
연속적으로 데이터가 저장되어 있지 않기 때문에 비효율적으로 값을 읽어와야한다.
NHWC 경우
연속적으로 데이터가 저장되어 있어 효율적으로 값을 읽어와서 연산이 가능하다.
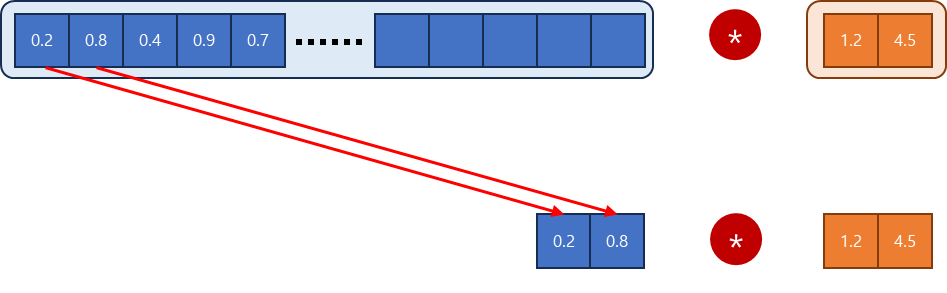
이러한 효율성은 FP16일 때 같은 메모리 대역폭에서 FP32보다 더 많은 값을 병렬적으로 처리할 수 있기 때문에 가속이 더욱 잘 되는 것을 확인할 수 있다.
