
Keywords
- long-term dependency
- 병렬 처리
- attention
- self-attention
- Seq2Seq
- Transformer
Seq2Seq

- 특징
- Encoder과 Decoder로 2개의 RNN으로 구성되어 있다.
- Decoder에서 각 시점마다 다른 정보를 사용해야할 것 같지만, Encoder를 통해 하나의 context vector를 만들고 Decoder에서는 동일한 하나의 context vector를 이용하여 번역을 수행한다.
- 문제점
- je를 예측할 때, suis를 예측할 때 동일한 하나의 context vector를 사용한다는 문제
- I에 해당하는 layer를 업데이트하기 위해서는 decoder과 직접 연결된 것이 없기 때문에 backpropagation 과정에서 gradient vanishing 문제가 발생할 수 있다.
- context vector를 만들 때도 가장 마지막 단어에 강조되고 이전에 사용된 단어들의 정보는 흐려진 상태이다.(long-term dependency)
RNN + Attention

- 특징
- context vector를 Decoder의 suis의 state와 encoder의 각 hidden state와의 내적(Dot-Product attention)을 통해 닮은 정도(attention score)를 구하고 weighted-sum을 하여 context vector를 시점마다 Attention을 활용하여 다시 계산하여 사용한다.
- 문제점
- h1, h2, h3를 구하는 과정에서 여전히 long-term dependency가 존재한다.
- 여전히 gradient vanishing 문제가 발생할 수 있다.
- encoding 시 현재 위치에서 뒤쪽에 있는 단어의 정보를 얻을 수 없다.(bidirectional but still have problem)
Transformer(self-attention)
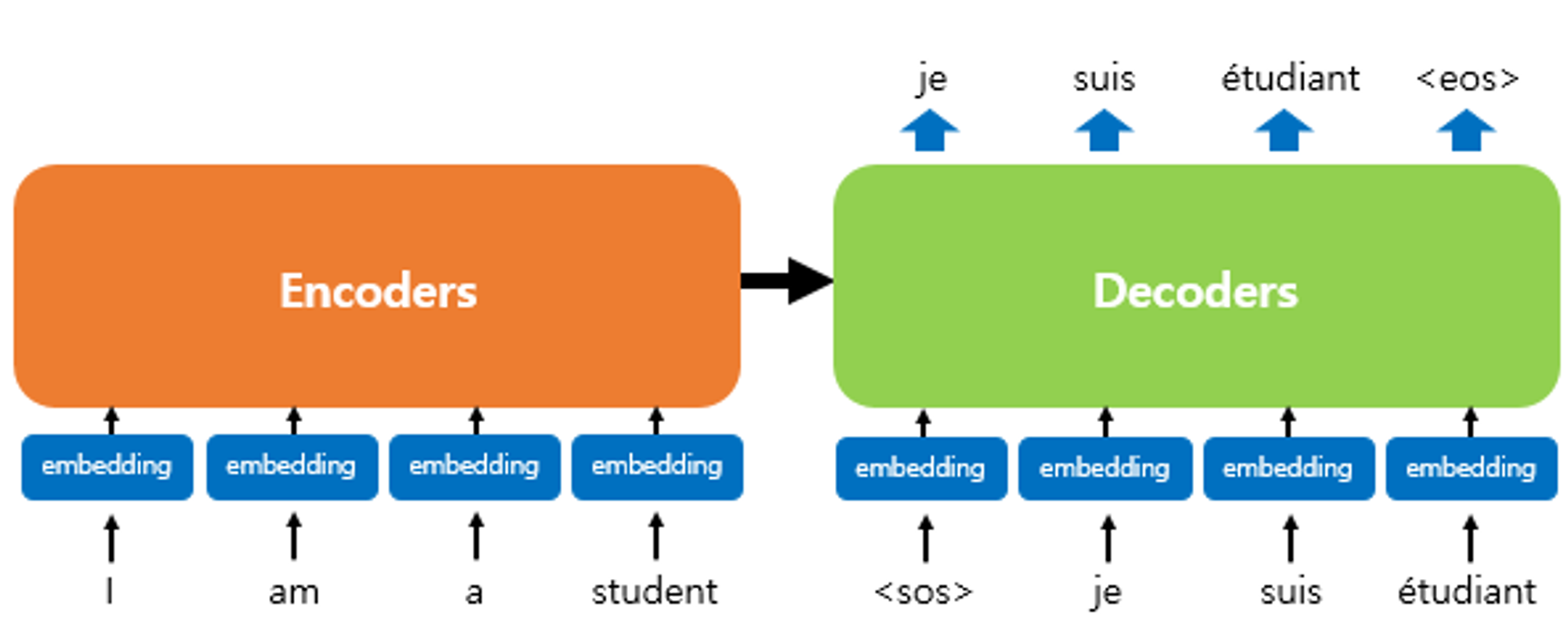
- 특징
- Encoder과 Decoder 모두에 attention을 통한 hidden state와 step을 구한다.
- 기존에는 다음과 같이 context vector만 attention mechanism을 활용하여 구했다. (self-attention) Before : After :
$h_2^{new} = <h_2, h_1>h_1 + <h_2, h_2>h_2 + <h_2, h_3>h_3$ $S_4^{new} = <S_4, S_1>S_1 + <S_4, S_2>S_2 + <S_4, S_3>S_3 + <S_4, S_4>S_4$ - 어느 위치에 있든 어떤 단어를 주목할지를 AI가 학습한다. → weighted sum의 균형을 AI가 학습
- 거리에 영향을 받지 않는다.
- 각 단어들이 모두 각각 연결되어 있기 때문에 gradient vanishing이 없다.
- Decoder에서는 뒤쪽 단어를 보면 안되므로 뒤쪽 단어와의 attention을 하지 않는다.
- Encoder의 hidden state를 기존처럼 sequential하게 구할 필요없이 한번에 병렬로 처리가 가능하다. → Decoder는 그렇지 않음
BERT(Bidirectional Encoder Representations from Transformers)
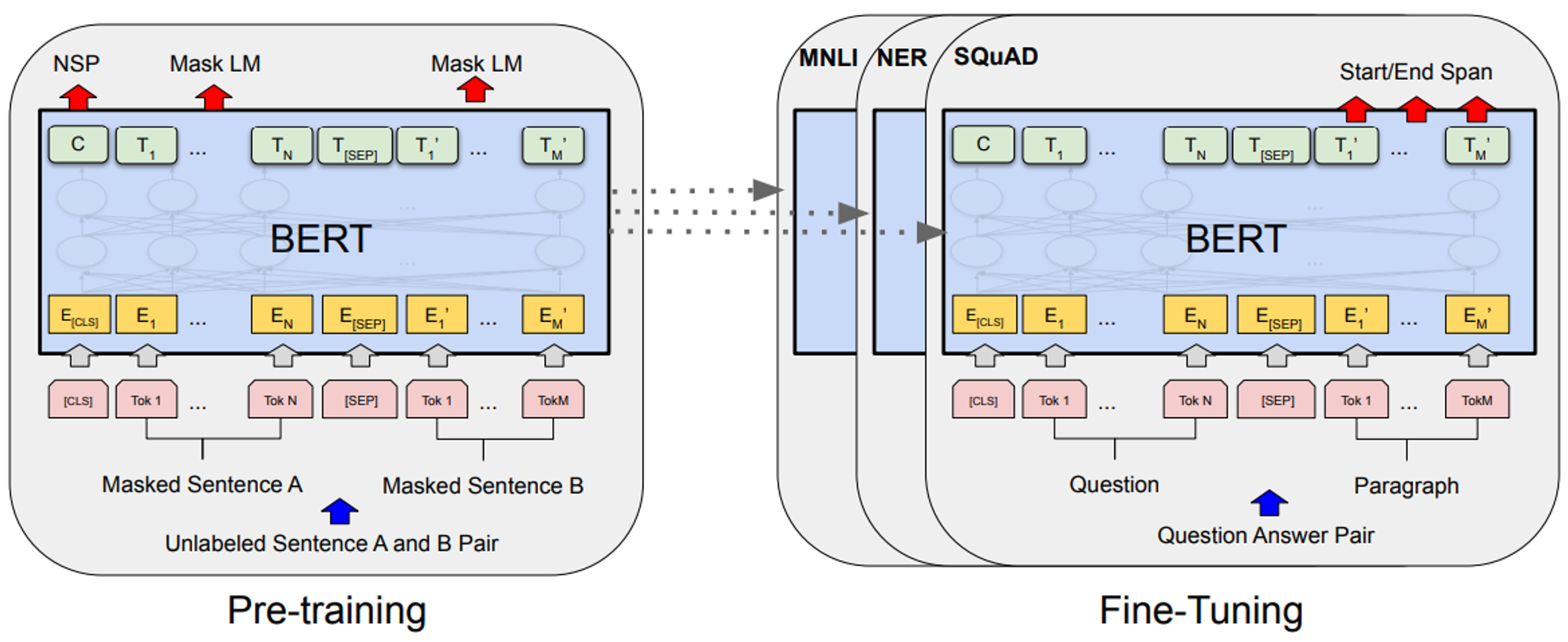
- 특징
- Transformer의 Encoder만 사용하여 모델을 구성한다.
- Pre-training과 Fine-Tuning으로 나눌 수 있다.
- Pre-training
- Masked LM 방식을 통해 학습을 진행한다.
- 입력 문장에서 마스킹을 하고 해당 위치의 단어를 맞추는 형식으로 양방향의 토큰을 모두 사용
- label 없이 입력 문장만으로 학습 가능
- Next Sentence Prediction 방식을 통해 학습을 진행한다.
- 두 문장을 넣고 해당 문장에 이어지는 문장인지 아닌지 학습
- Masked LM 방식을 통해 학습을 진행한다.
- Fine-Tuning
- 각 task에 맞게 출력을 수정하여 fine-tuning을 진행한다.

GPT(Generative Pre-Training)
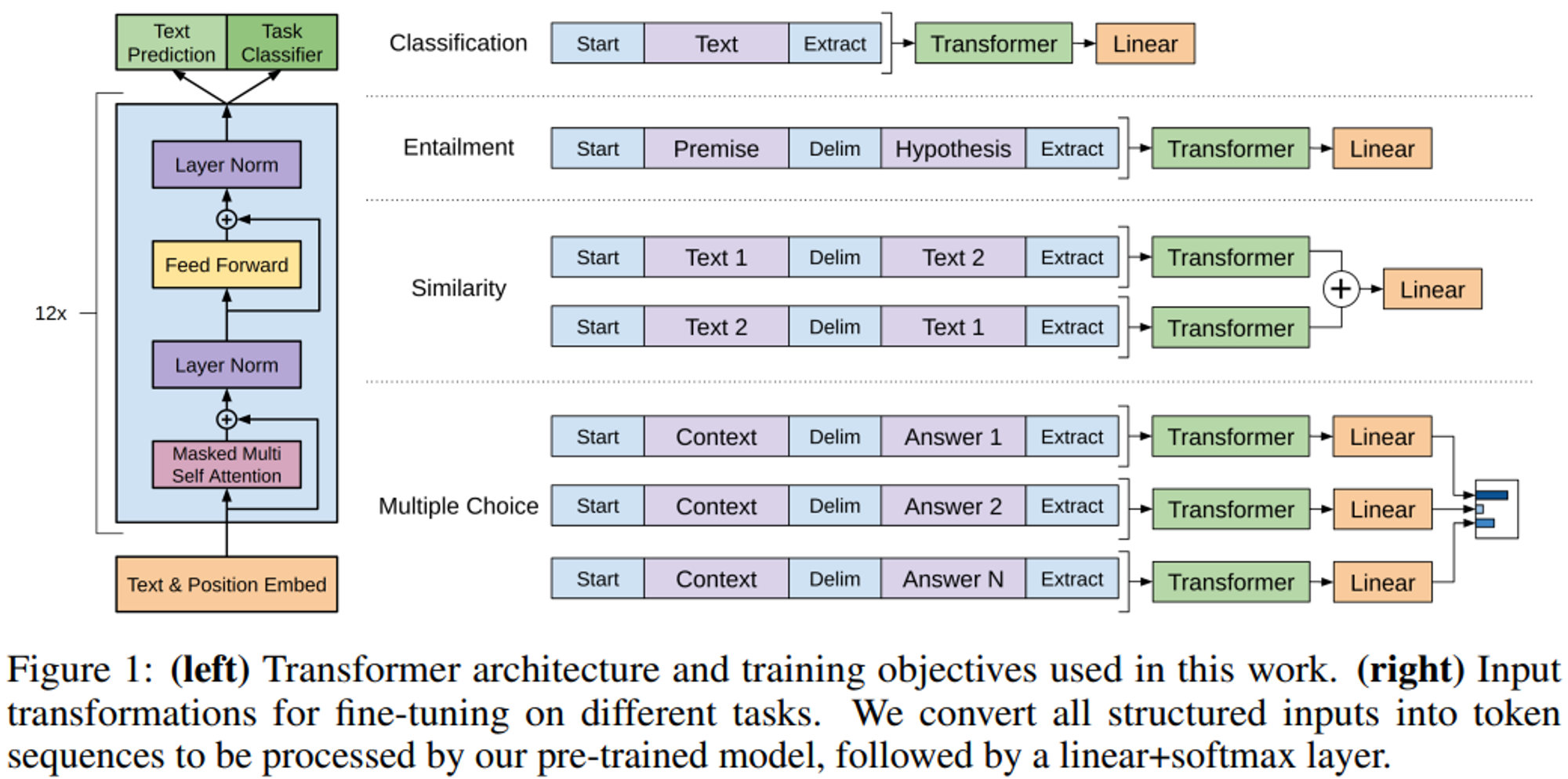
- 특징
- Transformer의 Decoder만 사용하여 모델을 구성한다.
- Pre-train시 Language model은 label data가 필요 없다.
- Fine-tuning 시 모델의 구조를 변경할 필요 없이 끝에 task 출력을 위한 간단한 layer만 붙이면 된다.
- Byte pair embedding으로 word embedding의 모르는 단어가 많을 수 있다는 단점과 character embedding의 단어간 유사도가 낮은 문제를 보완하였다.
Reference
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Improving Language Understanding by Generative Pre-Training
[TTT] 어텐션 & 셀프-어텐션 가장 직관적인 설명! (Attention & Self-Attention)
15-01 어텐션 메커니즘 (Attention Mechanism)
