[pyspark] You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior befor Spark 3.0.
Trouble Shooting
목록 보기
7/12
에러
Traceback (most recent call last):
File "/tmp/python4583073594585716790/zeppelin_python.py", line 162, in <module>
exec(code, _zcUserQueryNameSpace)
File "<stdin>", line 8, in <module>
File "/home/bradley/spark/python/pyspark/sql/pandas/conversion.py", line 205, in toPandas
pdf = pd.DataFrame.from_records(self.collect(), columns=self.columns)
File "/home/bradley/spark/python/pyspark/sql/dataframe.py", line 817, in collect
sock_info = self._jdf.collectToPython()
File "/home/bradley/spark/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py", line 1321, in __call__
return_value = get_return_value(
File "/home/bradley/spark/python/pyspark/sql/utils.py", line 196, in deco
raise converted from None
pyspark.sql.utils.SparkUpgradeException: You may get a different result due to the upgrading to Spark >= 3.0: Fail to recognize 'W' pattern in the DateTimeFormatter. 1) You can set spark.sql.legacy.timeParserPolicy to LEGACY to restore the behavior before Spark 3.0. 2) You can form a valid datetime pattern with the guide from https://spark.apache.org/docs/latest/sql-ref-datetime-pattern.html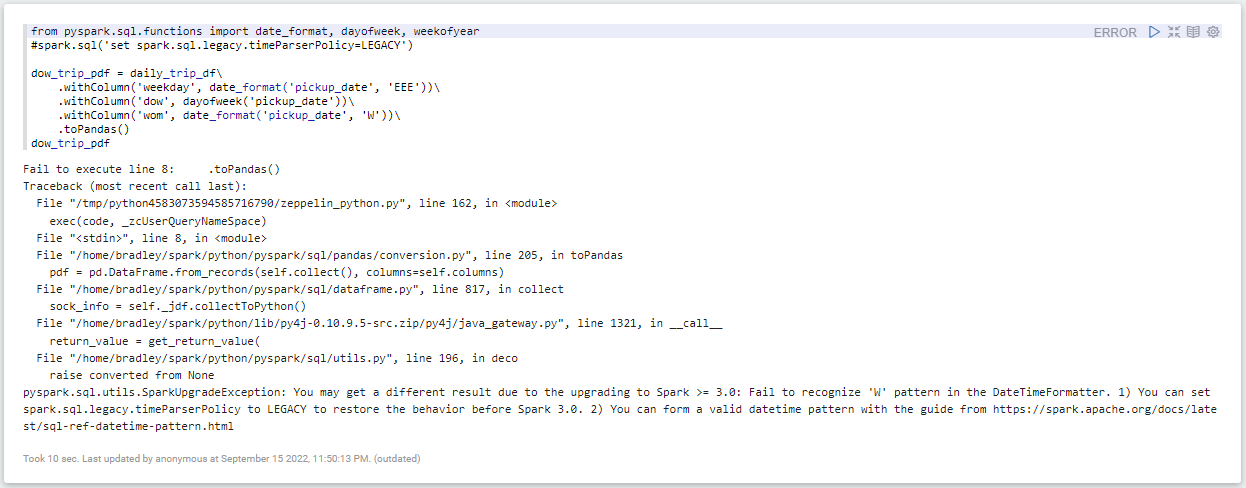
해결방법
아래 옵션과 같이 설정해준다.
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")

데이터 엔지니어링에 관심이 많은 홀로 삽질하는 느림보