
자료구조 첫 글부터 재귀를 올리는 이유는 뭘까요?
내가 연습을 해야되서 그렇읍니다. 바로 글 써보겠습니다.
재귀란 뭘까
재귀는 알고리즘 스스로가 자신을 호출하는 반복적인 과정입니다.
이런 느낌으로 함수에서 계속 자신을 불러오는 것입니다.
반복과 재귀의 차이
빠르게, 더 빠르게!
일반적인 for문이 O(n)의 시간복잡도를 가지는 것에 비해 재귀는 O(log n)의 시간 복잡도를 가집니다. 일반 반복문에 비해 빠른 속도를 보여줍니다.
공간복잡도
반복문에서 각 반복은 추가적인 메모리를 요구하지 않지만 재귀에서 각 재귀 호출은 추가적인 메모리를 스택에서 요구합니다.
난이도
일부의 경우 반복을 사용한 솔루션은 재귀를 사용한 솔루션 만큼 명확하지 않을 수 있습니다.
그러므로 그런 상황에서 재귀를 사용한 솔루션은 반복을 사용한 솔루션보다 훨씬 쉽게 공식화 할 수 있습니다.
재귀의 기본 원칙
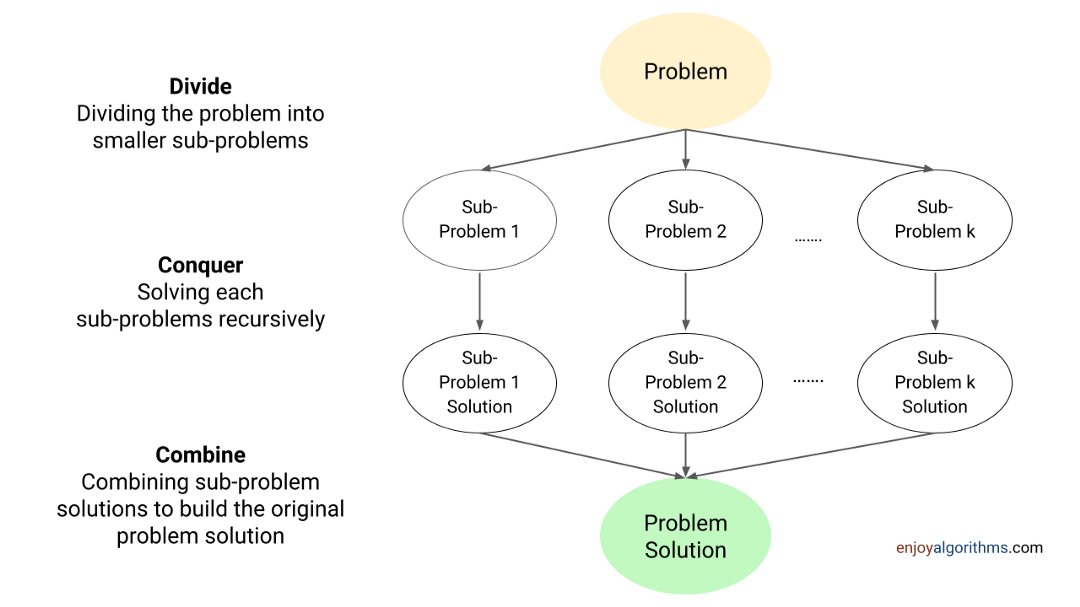
재귀를 사용하는 데 있어 기본 원칙은 분할 정복 기법입니다.
한 문제를 여러 부가 문제로 나눈 후 각 부가 문제를 해결하고 그 해결책을 합쳐서 원래의 문제를 해결한다는 기법입니다.
반복 to 재귀
반복을 재귀로 바꾸는 예제입니다.
선형탐색과 이진탐색을 예시로 한 번 들어보고자 합니다.
선형탐색과 이진탐색에 대한 내용은 여기(링크)서 확인할 수 있습니다.
선형탐색
int findMax(int* arr, int n) {
int max = arr[0];
for (int i = 1; i < n; i++) {
if (arr[i] > max)
max = arr[i];
}
return max;
}선형탐색을 통해 최고값을 찾는 알고리즘입니다. 재귀로 바꿔보면...
int rfindMax(int* arr, int n) {
if (n == 1)
return arr[0];
else {
int max = rfindMax(arr, n - 1);
if (max < arr[n - 1])
return arr[n - 1];
else
return max;
}
}이렇습니다.
이진탐색
int bsearch(int arr[], int size, int key) {
int low, high, mid;
low = 0;
high = size - 1;
while (low <= high) {
mid = (low + high) / 2;
if (key == arr[mid])
return mid;
else if (key > arr[mid])
low = mid + 1;
else
high = mid - 1;
}
}아주 일반적인 이진탐색 알고리즘입니다. 한 번 이거도 재귀로 바꿔보겠습니다.
int rbsearch(int arr[], int low, int high, int key) {
if (low > high) return -1;
else {
int mid = (low + high) / 2;
if (key == arr[mid])
return mid;
else if (key < arr[mid])
return rbsearch(arr, low, mid - 1, key);
else
return rbsearch(arr, mid + 1, high, key);
}
}얼핏 코드가 복잡해 보일 수 있지만 원리는 똑같습니다.
찾는 값을 key라고 할 때 key의 값과 배열의 중간값이 다르면 범위를 재조정해서 다시 자신을 호출하면서 스택을 쌓는 방식입니다.
정리
정리하자면, 재귀는 끝없는 분할과 반복입니다.
더 쉽게 말하자면 계속 자신을 불러오면서 스택 메모리에 쌓고, 결과에 다다를 때는 그 쌓아놓은 것을 한 번에 불러들여 결과를 내보냅니다.
