👏Coroutines Basic
프로세스, 스레드의 개념을 익혀보면서 코루틴이 어디서 동작하는지, 이들과 어떤 차이가 있는지 알아보자.
프로세스란 실행 중인 어플리케이션의 인스턴스이다. 어플리케이션은 여러 프로세스로 구성될 수 있다. 프로세스는 상태를 가지고 있고 리소스를 여는 핸들, 데이터, 네트워크 연결 등은 프로세스 상태의 일부이며 해당 프로세스 내부의 스레드가 엑세스를 할 수 있다.
스레드란 프로세스가 실행할 일련의 명령을 포함한다. 그래서 프로세스는 최소한 하나의 스레드를 포함하며 이 스레드는 어플리케이션의 진입점을 실행하기 위해 생성된다. 스레드 안에서 명령은 한 번에 하나씩 실행되어 스레드가 Block이 되면, Block이 끝날 때까지 같은 스레드에서 다른 명령을 실행할 수 없다.
코루틴은 경량 스레드 라고 하며, 스레드와 비슷한 라이프사이클을 가지고 있다. 코루틴은 스레드 안에서 실행된다. 스레드 하나에 많은 코루틴이 있을 수 있지만 주어진 시간에 하나의 스레드에서 하나의 명령만이 실행될 수 있다. 예시로, 같은 스레드에 10개의 코루틴이 있다면, 해당 시점에는 하나의 코루틴만 실행된다.
스레드와 코루틴의 가장 큰 차이점은, 코루틴은 빠르고 적은 비용으로 생성할 수 있다는 것이다. 수천개의 코루틴을 쉽게 생성할 수 있으며 수천개의 스레드를 생성하는 것보다 빠르고 자원도 적게 사용된다.
코루틴은 특정 스레드안에서 실행되더라도, 스레드와 묶이지 않는다는 점을 이해해야한다. 코루틴의 일부를 특정 스레드에서 실행하고 실행을 중지한 다음 나중에 다른 스레드에서 계속 실행하는 것이 가능하다. 코틀린이 실행 가능한 스레드로 코루틴을 이동시키기 때문이다.

위 설명을 그림으로 다시 정리해보자면, 각 코루틴(A, B, C) 는 특정 스레드에서 시작되지만 어느 시점이 지나 다른 스레드에서 다시 시작되는 것을 확인할 수 있을 것이다.
👏코루틴은 동시성 프로그래밍을 지원한다.
병렬성은 실제로 동시에 여러 작업을 처리되는 것이고, 동시성은 한번에 하나의 일만 처리하지만, 잦은 스위칭이 일어나면서 여러 일을 처리하기 때문에 동시에 여러 작업이 처리되는 것처럼 보인다.
올바른 동시성 코드는 결정론적인 결과를 갖지만 실행 순서에는 약간의 가변성을 허용하는 것이다.
결정론적 : 특정 입력이 들어오면 언제나 똑같은 과정을 거쳐서 항상 똑같은 결과를 내놓는다.
동시성을 이해하는 가장 좋은 방법은 순차적인 코드를 동시성과 비교하는 것이다.
먼저 아래와 같은 비동시성 코드가 있다고 가정해보자.
fun getProfile(id: Int): Profile {
val basicUserInfo = getUserInfo(id)
val contactInfo = getContactInfo(id)
return createProfile(basicUserInfo, contactInfo)
}사용자의 정보 (userInfo) 와 연락처 정보 (contactInfo) 를 순차적으로 실행하고, 프로필을 만들게 된다. 하지만 이러한 코드의 문제점이 두가지가 존재한다.
getUserInfo 와 getContactInfo 가 둘다 웹 서비스를 호출하고, 반환하는데 1초이상 소요된다면 getProfile은 항상 2초 이상 걸릴 것이다.
이 때 getUserInfo 와 getContactInfo 는 서로 의존적이지 않기 때문에 이들을 동시에 호출한다면, getProfile 의 실행시간을 절반으로 줄일 수 있을 것이다.
suspend fun getProfile(id: Int) {
val basicUserInfo = asyncGetUserInfo(id)
val contactInfo = asyncGetContactInfo(id)
createProfile(basicUserInfo.await(), contactInfo.await())
}코루틴을 이용해서, 비동기적으로 변경한 모습이며 위 코드는 두 요청이 거의 동시에 시작될 것이다. 두 함수의 await() 를 호출하여 둘다 완료될 때에만 createProfile 을 실행하도록 한다면, 어떤 호출이 먼저 종료되는지에 관계없이 getProfile 의 결과가 결정론적임을 보장할 수 있다.
스레드 생성
코틀린은 스레드 생성과정을 단순화해서 쉽고 간단하게 스레드를 생성할 수 있다. 코틀린에서는 스레드와 스레드 풀을 쉽게 만들 수 있지만, 직접 에세스하거나 제어하지 않는다는 점을 알아야 한다. 여기서는 CoroutieDispatcher를 만들어야 하는데, 이것은 기본적으로 가용성, 부하, 설정을 기반으로 스레드간에 코루틴을 분산하는 오케스트레이터이다. 디스패처가 만들어지면 이를 사용하는 코루틴을 시작할 수 있다.
async
결과 처리를 위한 목적으로 코루틴을 시작했다면 async() 를 사용해야 한다. async()는 Deferred 를 반환하게 되는데, 이는 취소 불가능한 Non-Blocking Cancellable Future를 의미한다.
runBlocking {
val task = GlobalScope.async {
doSomething()
}
//(1) task.join()
//(2) task.await()
}
fun doSomething() {
throw UnsupportedException("Can't do")
}위는 예외를 던지는 함수인 doSomething()과, async() 를 통해 task를 실행하는 코드이다. join()을 통해 task를 실행하게 되면 에러가 발생하지 않고 성공적으로 실행되지만 await()를 통해 실행하게되면 에러가 발생하면서 종료하게된다. await()의 경우 예외를 감싸지 않고 전파하기 때문에 unwrapping deferred 라고 불린다.
이처럼 join()으로 대기한 후 검증하고 오류를 처리하는 것과 await()를 직접 호출하는 방식의 차이는 예외 전파의 유무라고 할 수 있다.
launch
결과를 반환하지 않는 코루틴을 시작하려면 luanch() 를 사용해야 한다. launch()는 연산이 실패한 경우에만 통보를 받기 원하는 Fire and Forget 시나리오를 위해 설계되었다.
runBlocking {
val task = GlobalScope.async {
doSomething()
}
task.join()
}
fun doSomething() {
throw UnsupportedException("Can't do")
}위 코드를 launch로 바꿔 실행하게 된다면, 예외가 발생하지만 실행은 중단되지 않고 성공적으로 완료하게 된다.
👏Job
Job 은 Fire and Forget 작업이다. 한번 시작된 작업은 예외가 발생하지 않는 한 대기하지 않는다. 기본적으로 job 내부에서 발생하는 예외는 job을 생성한 곳까지 전파되기 때문에, 완료되기를 기다리지 않아도 발생한다.
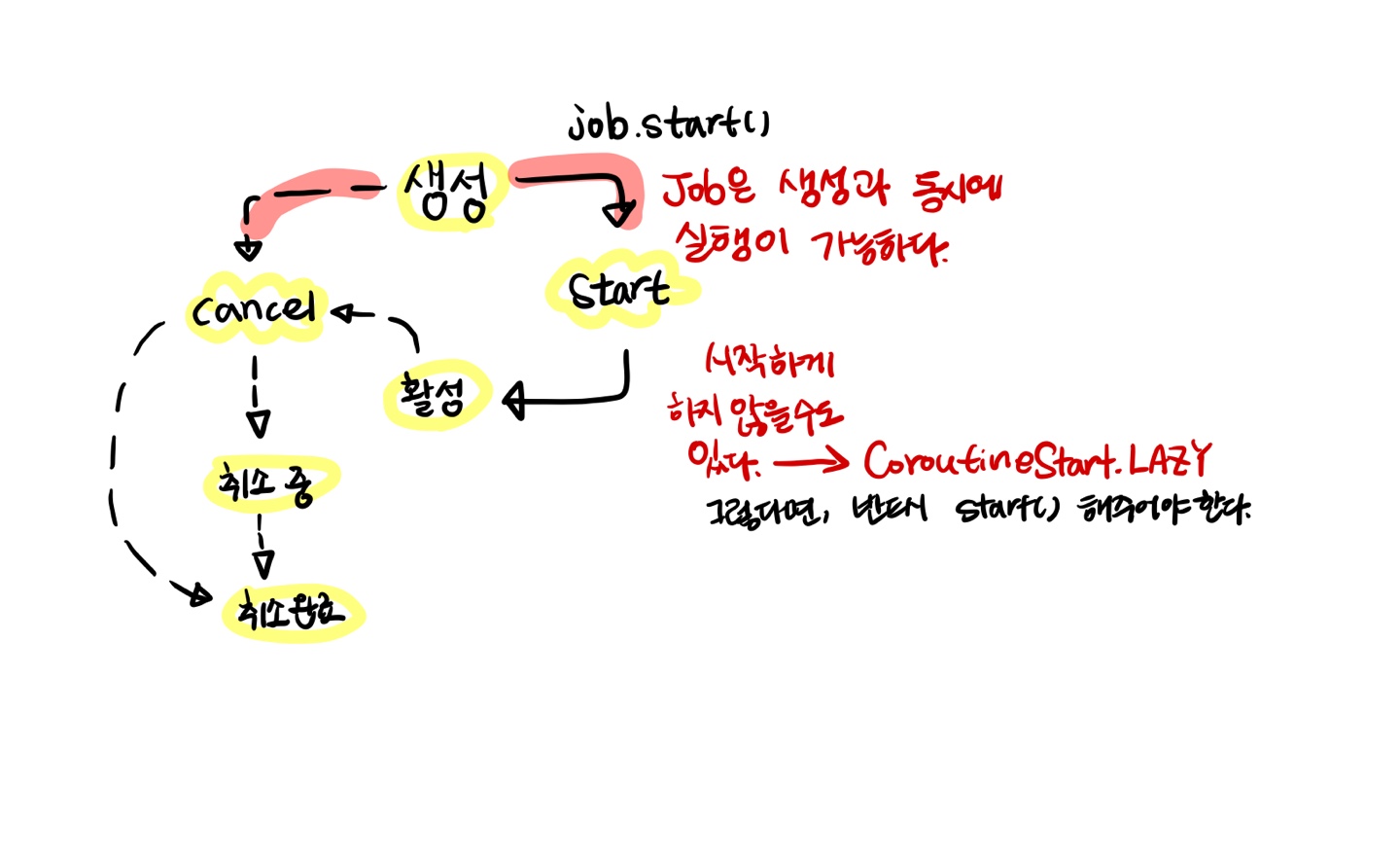
생성
job은 기본적으로 launch()나 job()을 사용해 생성될 때 자동으로 시작되고, 자동으로 시작되지 않게 하려면CoroutineStart.LAZY를 사용해야 한다.활성
활성상태에 있는 job은 다양한 방법으로 시작할 수 있지만 일반적으로 start(), join()을 이용해서 실행하는데, 둘의 차이점은 전자의 경우 job이 완료될 때까지 기다리지 않고 job을 시작하는 반면 후자는 job이 완료될 때까지 일시 중단한다는 점이다. 그래서 start()의 경우는 suspend 함수에서 호출하지 않아도 되고, join()의 경우 실행을 일시중단할 수 있기 때문에 suspend 함수 내부에서 호출해야 한다.
취소 중
취소 요청을 받은 활성 job은 취소중이라는 스테이징 상태로 들어갈 수 있다.취소됨
취소 또는 처리되지않은 예외로 인해 실행이 종료된 잡은 취소됨으로 간주된다.
Job의 상태는 한 방향으로만 이동한다.
runBlocking {
val job = CoroutineScope.launch {
delay(2000)
}
job.join()
//Restart
job.start()
job.join()
}Job은 특정 상태에 도달하면 이전 상태로 되돌아가지 않는다.
위 코드에서 처음 호출한 job.join()이 완료되면 완료됨 상태에 도달했으므로 start()를 호출해도 아무런 변화가 없을 것이다.
코루틴이 무거운 작업을 하고 있을 땐, job.cancel() 이 작동하지 않는다. 이때 주기적으로 yeild() 나 isActive 로 코루틴에게 작업을 취소할 수 있는 여지를 제공한다.
자식이 Exception을 뱉어버리면 전역으로 퍼지게 되어 일을 중단하게 되는데 Exception이 발생하게 될 때 부모에게는 퍼지지 않게 하기위해, SupervisorJob()을 사용하게 된다. 그렇다면, 자식들이 취소되어도 다른 자식들은 이어서 일을 진행할 수 있다.
👏Coroutine Context
코루틴은 항상 컨텍스트 안에서 실행된다. 컨텍스트는 코루틴이 어떻게 실행되고 동작해야 하는지를 정의할 수 있게 해주는 요소들의 그룹이다. 컨텍스트는 또한 결합이 될 수 있고, 분리하여 제거할 수도 있다.
Coroutine Context 참고
https://myungpyo.medium.com/reading-coroutine-official-guide-thoroughly-part-1-7ebb70a51910
withContext를 사용하는 임시 컨텍스트 스위치
이미 일시 중단 함수 상태에 있을 때 withContext()를 사용해 코드 블록에 대한 컨텍스트를 변경할 수 있다. withContext() 는 async와 동일한 역할을 하는 키워드인데, 차이점은 await() 를 호출할 필요가 없으면 마지막 구문에 해당하는 결과가 리턴될 때까지 기다린다. 즉, 프로세스에 Job을 포함시키지 않고도 다른 컨텍스트로 전환할 수 있게 해주는 일시 중단 함수이다.
👏Basic Operator
Iterator
- 인덱스로 요소를 검색할 수 없으므로 요소는 순서대로만 엑세스 할 수 있다.
- 더 많은 요소가 있는지 여부를 나타내는 hasNext() 함수가 있다.
- 요소는 한 방향으로만 검색할 수 있다. 이전 요소를 검색할 방법은 없다.
호출 사이에서 일시 중단되지만, 실행 중에는 일시중단 될 수 없다. 그래서, 일시중단 연산이 없어도 반복할 수 있다. 앞으로 나올 Sequence와 Iterator는 CoroutineContext를 받지 않는다. 기본적으로 코드를 호출한 컨텍스트와 동일한 컨텍스트에서 코드가 실행되기 때문이다. 정보 산출 후에만 일시중지가 가능하기 때문에 이를 위해서 yield() 혹은 yieldAll() 함수를 호출해야 한다.
val iterator = iterator {
yield("First")
yield("Second")
yield("Third")
}
println(iterator.next())
println(iterator.next())
println(iterator.next())
}이 코드는 세 가지 요소를 포함하는 Iterator를 빌드한다. 요소가 처음 요청될 때 첫번째 줄이 실행돼 "First" 값이 산출되고 이후에 실행이 중단된다. 다음 요소가 요청되면 두번째 줄이 실행돼 "Second" 가 산출되고 다시 일시 중단된다. 따라서 Iterator가 포함하는 세 가지 요소를 얻으려면 next() 함수를 세 번 호출하면 된다.
Sequence
- 인덱스로 값을 가져올 수 있다.
- 상태가 저장되지 않으며, 상호작용한 후 자동으로 재설정 된다.
- 한 번의 호출로 값 그룹을 가져올 수 있다.
일시 중단 시퀀스를 만들기 위해 sequence() 빌더를 사용한다. 빌더는 일시 중단 람다를 가져와 Sequence 를 반환한다.
val sequence: Sequence<Any> = sequence {
yield("A")
yield(1)
yield(32L)
}일시중단 시퀀스는 상태가 없고, 사용된 후에 재설정될 수 있다. 이터레이터를 사용하는 것과는 달리 시퀀스는 각각의 호출마다 요소의 처음부터 실행됨을 알 수 있다.
Flow
코루틴에서 suspend function은 한 개의 단일 값만을 방출한다면, flow 는 여러개의 결과 값을 방출한다. Flow를 사용하면 suspend를 prefix로 붙이지 않아도 된다. 데이터를 요청할 때마다 처음부터 새로 발행되며 요청 전에는 선언만 있을 뿐, 아무런 동작을 하지 않는다. Flow() 로 생성이 가능하고, emit 혹은 emitAll으로 데이터를 전달할 수 있다. Flow는 자체적으로 취소기능을 제공하지 않는다. 그래서, 외부에서 취소가 가능한 무언가로 감싸주어야 해서 보통 launch, aysnc, launtIn 을 감싸주어야 한다. flow 는 context를 변경할 때 flowOn() 을 통해 바꾸어야 한다. ex) flowOn(Dispatchers.IO)
private fun getNumbers(): Flow<Int> = flow {
for (i in 1..5) {
delay(200)
emit(i)
println("Emit $i")
}
}
getNumbers().conflate().collect {
println("collect $it")
delay(500)
}emit만 하면 collect하지 않으면, println("emit $it") 이 출력되지 않는다. rxjava에서 doOnxxx() 역할을 onStart, onEmpty, catch, onCompletion, retry 등등을 대체할 수 있다.
번외)
LiveData vs Flow
- LiveData, Flow 둘 다 데이터를 전송하기 위한 용도이다.
LiveData 는 ViewModel에서 데이터 전송 및 통신의 목적으로 사용하고 있어서 메모리의 누수룰 막을 수 있고, 생명주기를 보장할 수 있다. Room의 경우에도 LiveData를 지원해주나, LiveData는 BackPressure 혹은 Thread 의 변경을 지원해주지 않는다.- LiveData와 Flow는 서로 상호작용이 가능하다. LiveData는 최신 데이터를 View로 전달할 수 있고, Flow는 UseCase & Repository & DataSource 레이어들과 긴밀하게 작동하여 데이터를 수집하고, 서로다른 코루틴 범위에서 작동할 수 있다. 그래서 ViewModel - View 간에는 LiveData, Data 레이어에서는 Flow가 가장 이상적인 방법이라고 할 수 있다.
Channel
동시성과 관련된 수많은 오류 중 하나는 서로 다른 스레드 간에 메모리를 공유할 때 발생하게 된다. 채널은 이러한 문제를 해결하기 위해, 스레드가 서로 상태를 공유하는 대신 메세지를 주고 받는 통신을 함으로써 동시성 코드를 작성하는데 도움을 줄 수 있는 도구이다.
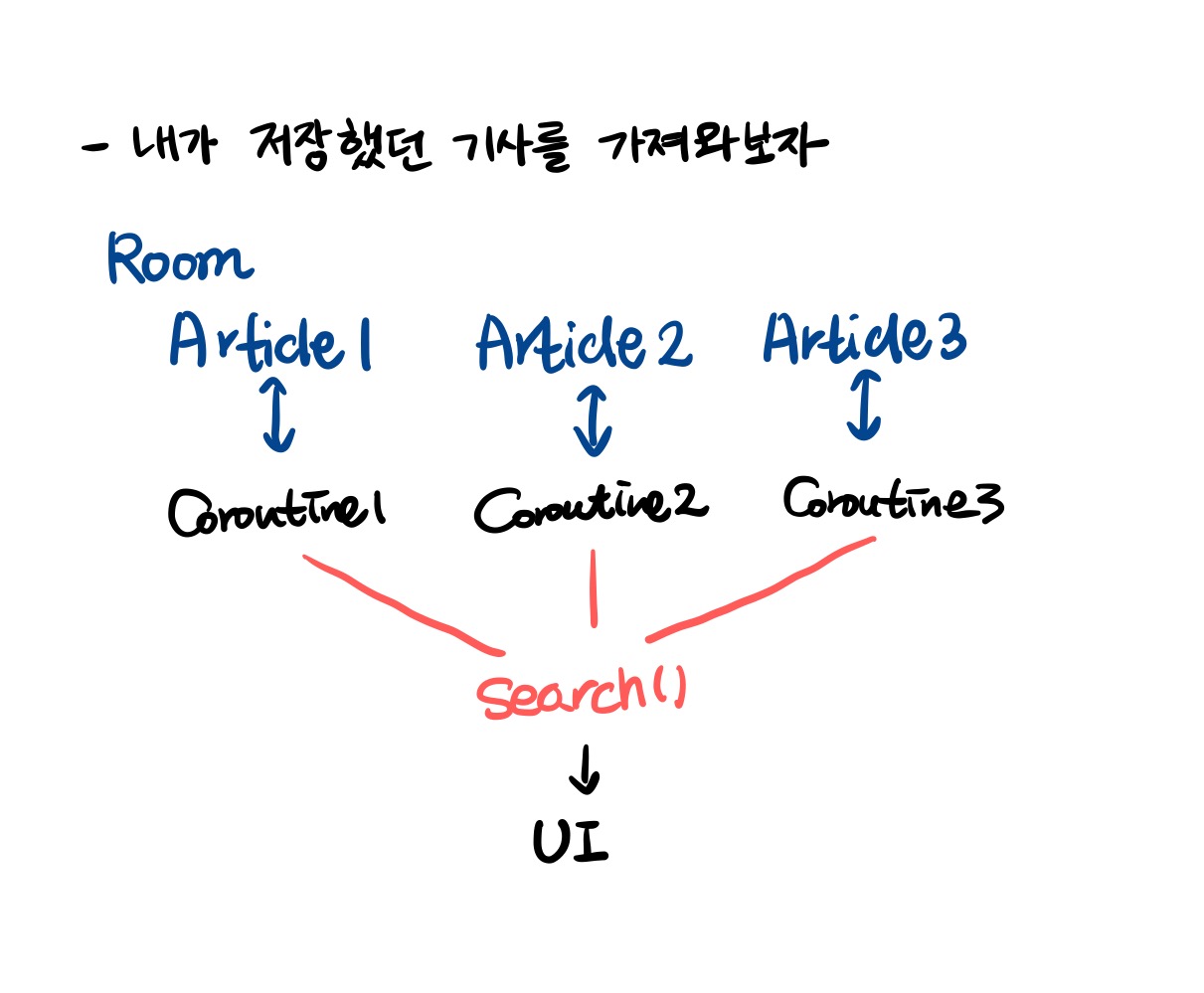
많은 양의 아티클 리스트를 조회하여, UI에 보여주는 과정을 예시로 들어보자. 첫 번째 방법으로는 아티클 리스트를 Deferred<List<ResultDto>> 의 형식으로 반환하는 것이다. 하지만 위와같은 리턴타입은 조회해야할 아티클의 수가 많을 경우 응답을 반환하는 시간이 길어질 수 있는데, 이는 결과표시를 지연시켜서 사용자가 즉각적인 결과값을 볼 수 없을 것이다.
이 점을 개선하기 위해 채널을 사용하게 된다. Deferred 를 대체할 수 있는 방법으로는 ReceiveChannel<ResultDto> 방식을 택하는 것인데, 이는 조회된 아티클이 도착하는 즉시 바로 UI에 결과를 점차적으로 표시할 수 있어, 사용자에게 좋은 경험을 줄 수 있을 것이다.
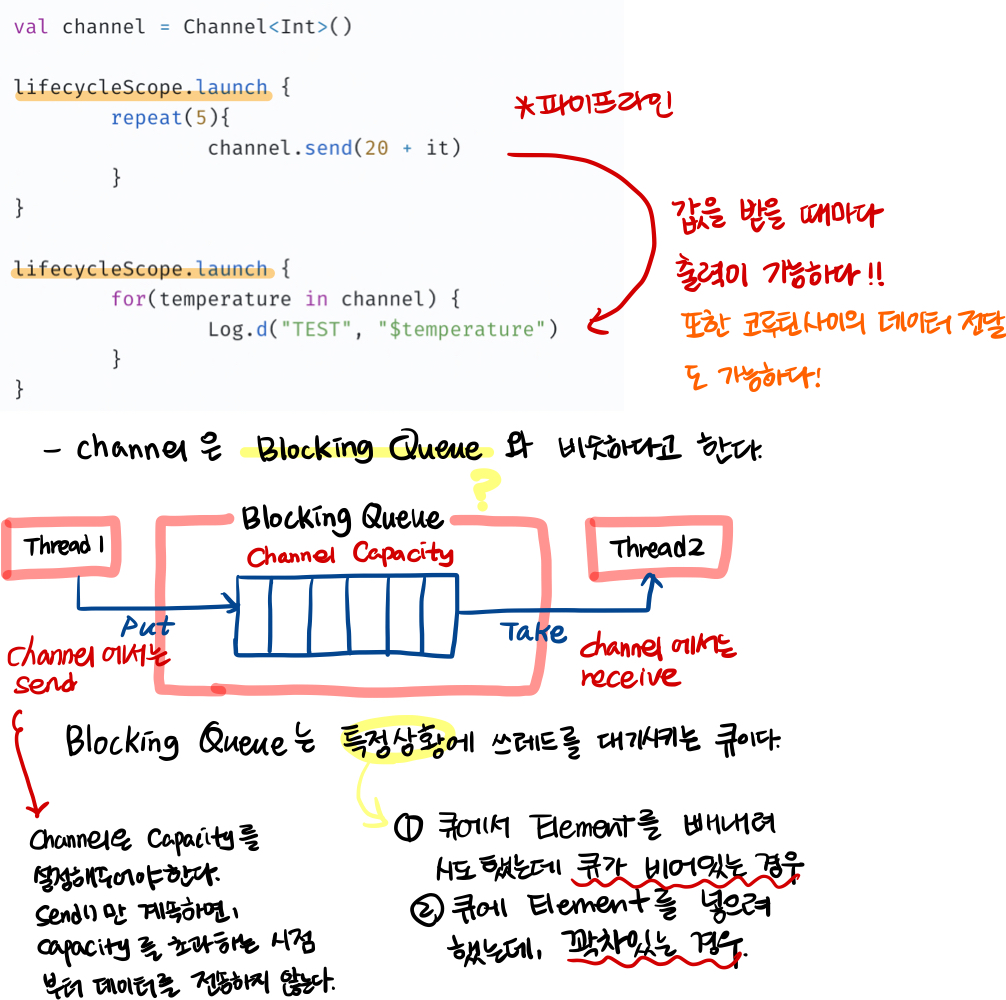
Blocking Queue
채널은 Blocking Queue 와 비슷하다. Deffered는 하나의 값을 반환할 수 있다면, Channel은 stream을 반환한다. 따라서 동시성이 필요한 여러 coroutine에서 공유하면서 사용된다. queue와 다르게 channel은 더 이상 사용하지 않을때 close 시킬 수 있고, close를 호출하더라도 그 이전에 넣어놓은 값들은 받아올 수 있음을 보장한다.
BlockingQueue의 put -> Channel의 send
BlockingQueue의 take -> Channel의 receive
Channel Buffer Type
-
Rendezvous (Unbuffered)
👉 버퍼를 설정해주지 않으면, 기본값으로 들어간다. Rendezvous는 버퍼가 없기 때문에 수신측 Coroutine과 송신측 Coroutine이 모두 가능한 상태로 모일때까지 suspend 된다. -
Conflate
👉 만약에 수신하는 Coroutine이 송신하는 Coroutine을 따라잡지 못했다면, 송신하는 쪽은 새로운 값을 버퍼의 마지막 아이템에 덮어씌운다. 수신 Coroutine이 다음 값을 받을 차례가 되면, 송신 Coroutine이 보낸 마지막 값을 받는다. 수신측 Coroutine은 채널 버퍼에 값이 올때까지 suspend 된다. -
Buffered
👉 고정된 크기인 Array 형식의 버퍼를 생성한다. 송신 Coroutine은 버퍼가 꽉 차있으면 새로운 값을 보내는 걸 중단한다. 수신 Coroutine은 버퍼가 빌때까지 계속해서 꺼내서 수행한다. -
Unlimited (Linked List)
👉 제한 없는 크기인 Linked List 형식의 버퍼를 가진다. OutOfMemeoryException을 일으킬 수 있다. 송신 Coroutine은 suspend 하지않지만, 수신 Coroutine은 버퍼가 비면 suspend 된다.
Actor
하나의 값을 수정할 때, 여러 스레드에서 변경을 시도하게되면 변경된 값이 유실될 수 있어 원자성에 위반되게 된다. 이런 문제를 방지하기 위해 공유 상태에 접근하는 모든 값을 단일스레드로 한정지을 수 있는데, 원자 블록에 더 높은 유연성을 원하는 시나리오가 존재하는 경우에 스래드 한정을 기반으로 동시성의 기본 요소인 채널을 합쳐 Actor를 만들 수 있다.
