
🧘🏻♀️ 내가 간헐적 단식을 유튜브에서 알게 되고 실행한지가 일주일이 좀 넘었는 것 같은데, 몸무게를 재보니 많이 빠지지는 않았다. 겉으로 보기에는 붓기도 좀 빠지고 살도 꽤 많이 빠져보였는데ㅠㅠ 사실 이 기간동안 야식을 3번정도 먹었는데 이게 좀 주원인이 아닌가 싶기도 하다.
객관적으로 보기에 좋은 결과들은 항상 금방 이루어지지 않는 것 같고, 이 과정 또한 즐겨지는 못하더라도 끌고나가야 하는 것 같다.
이제 본론으로 들어가서
💻 부트캠프 공부내용
도커를 배운 이유 중 하나가 데이터베이스를 위해서이다.
내 컴퓨터 안에 백엔드API서버 가상컴퓨터 하나, 데이터베이스 가상컴퓨터 하나 이렇게 두개를 돌리는 것을 목표로 한다.
- 데이터베이스도 Port가 있고, 그래서 데이터베이스 서버라고 부른다.
- NoSQL의 Collection이 담기는 방식은 게시판collection, 상품collection 등등으로 담긴다.
- 몽고DB Collection의 ID는 자동으로 생성된다.
 express 도커컴퓨터와 mongoDB 도커컴퓨터 간에도 포트-포워딩을 해줘야 하는데 그럴 필요 없이 둘을 그룹핑해주는 것이 도커-컴포즈이다.
express 도커컴퓨터와 mongoDB 도커컴퓨터 간에도 포트-포워딩을 해줘야 하는데 그럴 필요 없이 둘을 그룹핑해주는 것이 도커-컴포즈이다.
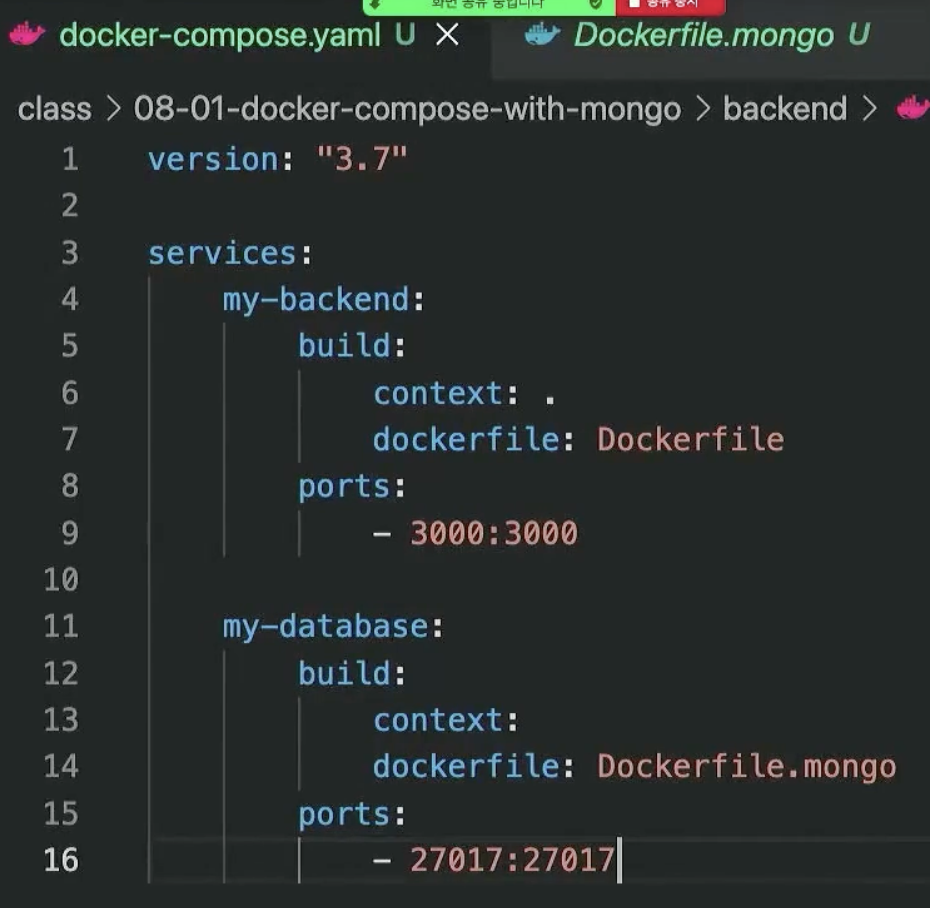 먼저 docker-compose.yaml파일을 만들어줘야 하는데 이는 설정파일이다.
먼저 docker-compose.yaml파일을 만들어줘야 하는데 이는 설정파일이다.
우선 버전을 쓰고, services는 가상컴퓨터를 말한다. 띄어쓰기가 중요한 파일이라 유의해서 작성해야 한다.
컴퓨터 이름을 원하는대로 쓴다. 그리고 빌드 명령어에 콘텍스트는 파일의 위치를 알려주는 부분인데 같은 폴더 위치라서 . 을 쓴다. 그리고 해당 도커파일의 이름을 적어준다. 그리고 아래에 포트-포워딩 포트를 적어준다. 아래의 데이터베이스는 27017이 기본포트라서 저렇게 적어준 모습이다.
- 서비스 배포할 때에는 도커 안 쓴다. 도커는 개발용(개발할 때 쉽게 하려고).
- 도커-컴포즈 내의 도커들은 서로 이름만 알려주면 포트-포워딩 안해줘도 된다.=> 이름을 가지고 찾는 방식을 '네임리졸루션'이라고 한다. but, 지금 포트포워딩 살려놓는 이유는 포스트맨 테스트와 mongoDB-compass를 위해서이다.(둘 다 로컬컴퓨터에서 동작하기 때문)
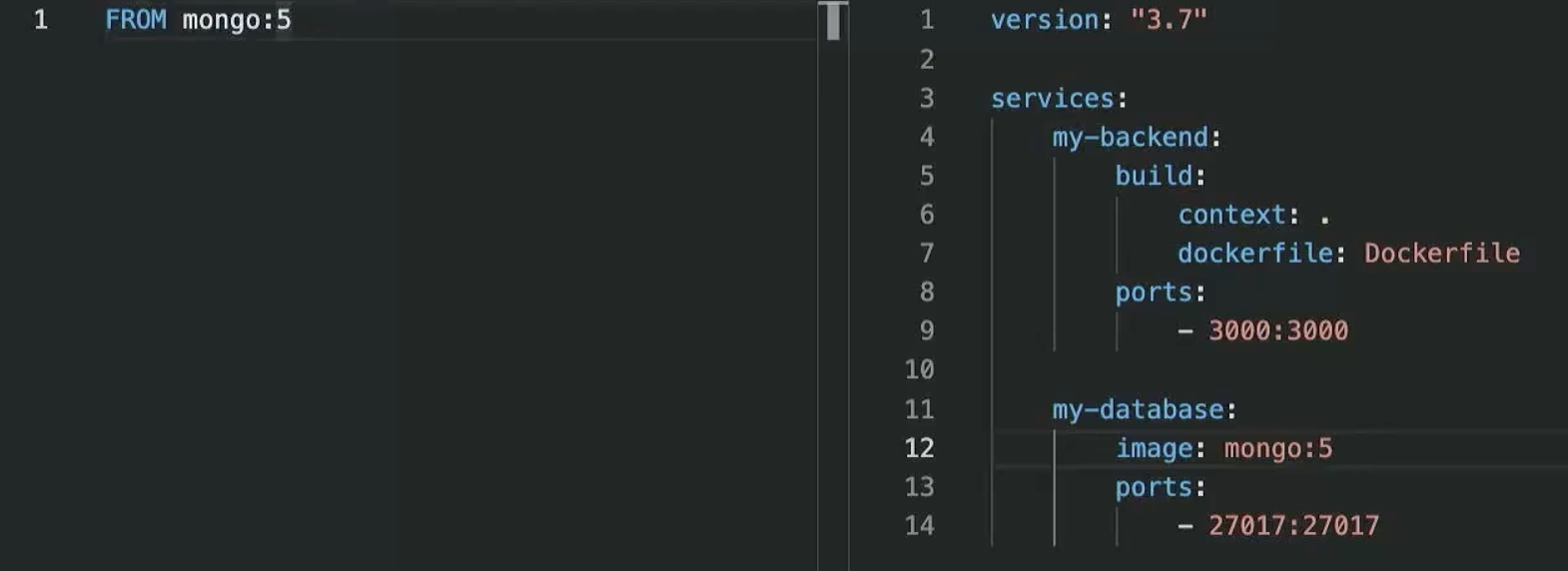 이렇게 Dockerfile이 간단하면, 오른쪽처럼 image : mongo 처럼 간단히 만들어서 저 한 줄 도커파일을 삭제하는 방법도 있다.
이렇게 Dockerfile이 간단하면, 오른쪽처럼 image : mongo 처럼 간단히 만들어서 저 한 줄 도커파일을 삭제하는 방법도 있다.
- 데이터베이스도 엘라스틱서치,레디스 등 종류가 많은데 성능을 위한, 검색속도를 위한, 임시저장을 위한 데이터베이스 등 역할이 다양하기 때문에.
- ODM,ORM을 사용하는 덕분에 모든 것을 key: value 형식의 객체 형태로 하면 쿼리문으로 바꿔준다. 자바스크립트는 객체가 개발할 때 가장 편하기 때문에 ORM,ODM이 객체로만 만들어놓으면 쿼리문으로 실행시켜준다.
 도커 express 가상컴퓨터 입장에서 localhost는 본인 도커이다. 근데 mongoDB는 다른 가상컴퓨터에 설치되어 있으므로 해당 가상컴퓨터이름과 포트숫자를 저렇게 써준다.
도커 express 가상컴퓨터 입장에서 localhost는 본인 도커이다. 근데 mongoDB는 다른 가상컴퓨터에 설치되어 있으므로 해당 가상컴퓨터이름과 포트숫자를 저렇게 써준다.
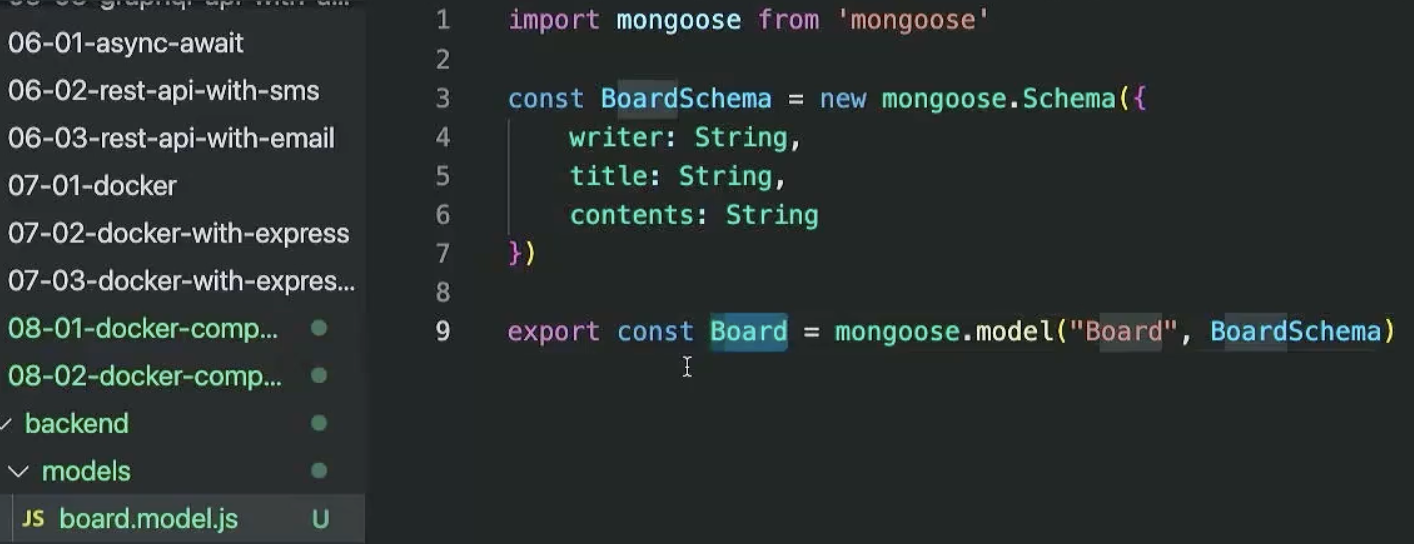 몽구스는 우선 model을 만들어줘야 한다. 모델 폴더에 각 collection 이름에 해당하는 파일을 만들고 몽구스를 import한 다음 스키마구조를 만들어서 타입이 뭐가 들어가는지를 설정해주고 이를 바탕으로 밑에서 collection 이름과 export를 붙여 다른 파일 코드들에서 쓸 수 있게 해준다.
몽구스는 우선 model을 만들어줘야 한다. 모델 폴더에 각 collection 이름에 해당하는 파일을 만들고 몽구스를 import한 다음 스키마구조를 만들어서 타입이 뭐가 들어가는지를 설정해주고 이를 바탕으로 밑에서 collection 이름과 export를 붙여 다른 파일 코드들에서 쓸 수 있게 해준다.
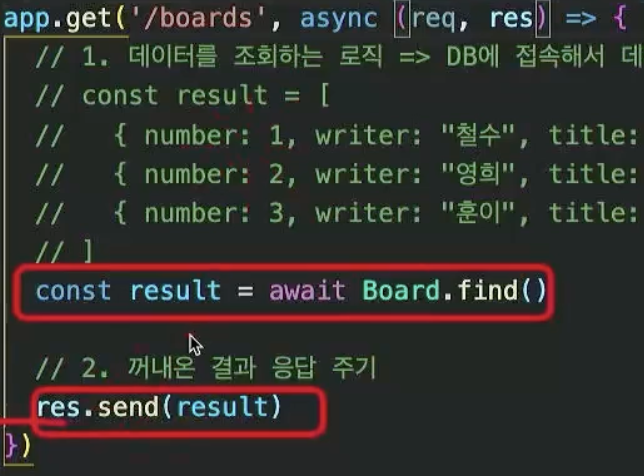 몽구스ODM을 활용한 데이터 조회API.
몽구스ODM을 활용한 데이터 조회API.
collection이름.find()를 써서 데이터를 불러오고 비동기 이기 때문에 async,await를 붙여서 동기적으로 만들어주고 result 변수에 넣어서 res.send(result)로 프론트엔드에 보내준다.
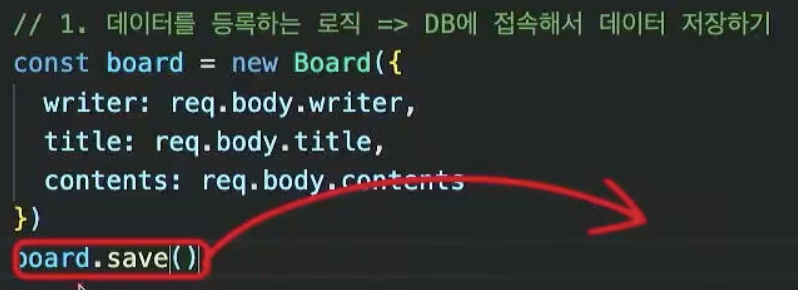 몽구스ODM을 활용한 데이터 등록API.
몽구스ODM을 활용한 데이터 등록API.
req.body에 브라우저 정보들이 들어오기 때문에 저렇게 writer,title,contents르 받아오고 .save()로 DB에 저장한다. 비동기이기 때문에 동기로 만들어주기 위해 함수에 async,await를 붙여준다.
- 내 컴퓨터의 소스코드와 도커 express 가상컴퓨터의 소스코드를 동기화시키는 것을 Volumes라고 한다.(이것 안해주면 내 컴퓨터 소스코드와 도커 express컴퓨터 소스코드 다르기 때문에 nodemon도 실행이 안 된다.)
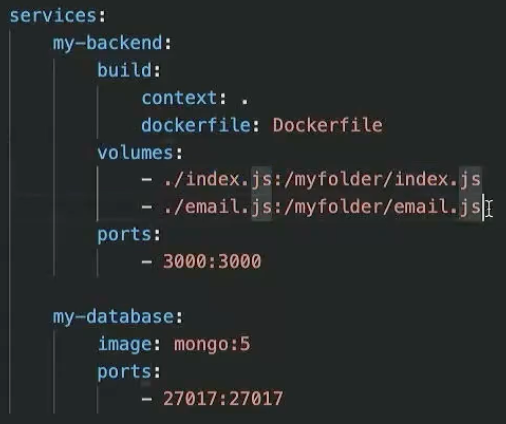 volumes 적용시키는 모습. 동기화시키고 싶은 내컴퓨터 파일과 오른쪽에는 같게 만들고 싶은 도커의 파일 적어주는데, 여러개 생기면 복잡해지니까 나중에는 src파일 안에 소스코드를 다 넣고 파일 이름을 적어주는 식으로 효율적으로 만든다.
volumes 적용시키는 모습. 동기화시키고 싶은 내컴퓨터 파일과 오른쪽에는 같게 만들고 싶은 도커의 파일 적어주는데, 여러개 생기면 복잡해지니까 나중에는 src파일 안에 소스코드를 다 넣고 파일 이름을 적어주는 식으로 효율적으로 만든다.
개인 프로젝트에 대한 이야기 : 당근소알
이제 조금씩 슬슬 프로젝트를 시작하려는 생각이 있다. 전에 '당근집밥'으로 서비스를 만들어보려 했는데 서비스의 애로사항들이 좀 있어서 철회했다.
이번에는 부트캠프 팀프로젝트에서 내가 냈던 아이디어이긴 한데, '당신 근처 소규모 알바'라는 뜻의 '당근소알'을 만들어보려고 한다.
내가 하려는 분야가 백엔드라서 프론트엔드 부분은 구현이 힘들 것 같고, 웹 서비스 안의 기능들과 DB설계도 등으로 나타내보아야 할 것 같다.
이 서비스의 기획의도는 알바를 찾는 사람과 알바를 구하는 사람 측면으로 나눌 수 있다.
알바를 찾는 사람은 우선 정규 알바를 하기 위해서는 정해진 스케쥴의 알바를 구하는 것은 좀 부담스럽고, 거리나 교통의 문제로 알바를 하기 힘든 조건일 수 있다.
알바를 구하는 사람들은 매년 오르는 최저시급에 정기적인 시간동안 알바를 두는 것은 굉장히 부담일 수 있고, 짧은 시간만 필요하거나 주변에서 바로 구해서 써야 할 경우도 있다.
그렇게 해서 고안한 서비스가 '당근소알' 서비스를 만들게 되었다.
우선 알바의 형태는 굉장히 자유롭다. 반려동물 돌보기, 이사짐 나르기, 오픈런 대행 등등.
식당이나 가게에서 하루정도 짧은 시간 필요해서 알바생을 쓸 수도 있다.
요즘 같이 어려운 시대에 소일거리 대상으로 알바를 구하는 사람도 주변에서 짧은 시간을 일해 용돈벌이를 할 수 있고, 알바를 구하는 입장에서도 금전 부담이 덜하게 인력을 쓸 수 있다.
서비스의 기능 벤치마킹은 당근마켓에서 많이 따올 것 같고, 알바생 매치가 되면 알바생이 불시에 알바취소를 하는 것을 방지하기 위해 알바성사 예치금 같은 것을 넣는 기능과 알바생의 평점보기 기능, 알바생과 알바고용자간의 대화기능, 내 주변 알바찾기, 알바생 자기소개글 등의 기능을 넣을 예정이다.
데이터베이스는 관계형 데이터베이스(RDB)를 쓸 것이고 가장 먼저 ERD를 제작해볼 예정이다.
인프런 부트캠프 강의를 들어나가면서 이 프로젝트를 같이 해보려고 한다. 틈틈이 서브공부인 컴공 필수공부들도 해나가보려한다.
프로젝트의 제작과정들은 블로그에 작성해 나가려고 한다.
