2019 KAKAO BLIND RECRUITMENT
오픈채팅방 - Level 2
https://programmers.co.kr/learn/courses/30/lessons/42888
내 풀이 - 통과
def solution(record):
answer = []
dic = {}
for r in record:
message = r.split()
if message[0] == "Enter" or message[0] == "Change":
dic[message[1]] = message[2]
for r in record:
message = r.split()
if message[0] == "Enter":
answer.append(dic[message[1]] + "님이 들어왔습니다.")
elif message[0] == "Leave":
answer.append(dic[message[1]] + "님이 나갔습니다.")
return answer처음에 어떤 이름으로 들어왔고 중간에 몇번 change 됐든지 상관없이
마지막에 Enter, Change 된 값이 그 사람의 최종 대화명이 되므로
그냥 쭉 보면서 id: name 형태로 이름 update
=> 자동으로 마지막에 변경된 값이 저장됨
다시 보면서 Enter, Leave 에 따른 result 를 answer 에 추가
후보키 - Level 2
https://programmers.co.kr/learn/courses/30/lessons/42890
내 풀이 - 실패
import collections
from itertools import combinations
def solution(relation):
answer = 0
l = len(relation[0])
col = [0] * l
dic = {i: [] for i in range(l)}
### 같은 속성의 값끼리 묶어줌
for r in relation:
for i in range(len(r)):
dic[i].append(r[i])
### 유일성을 만족하는 속성 찾기
for i in range(l):
cnt = collections.Counter(dic[i])
if len(cnt) == len(relation):
col[i] = 1
answer += 1
### 그 외의 후보키들 찾기
for i in range(l):
if col[i] == 0:
d = dic[i]
for j in range(i+1, l):
if col[j] == 0:
key = set()
k = 0
for a, b in zip(d, dic[j]):
d[k] = a+b
if d[k] not in key:
key.add(d[k])
k += 1
if len(key) == len(relation):
answer += 1
break
return answer-
같은 속성의 값끼리
dic에 묶어서 저장 -
유일성을 만족하는 단일 후보키 찾기
-
다중 후보키 찾기
현재 속성부터 이후의 속성까지 합친 값을 확인
=> 문제: 연속되는 키들만 확인 가능해서 다 통과 못함
combinations 함수를 이용해서 모든 조합을 찾아도 될 거 같음...
다른 사람의 풀이
from collections import deque
from itertools import combinations
def solution(relation):
n = len(relation)
m = len(relation[0])
answer = 0
# 가능한 모든 조합 구하기
com = []
for i in range(1,m+1):
com.extend(list(combinations(range(m), i)))
# 유일성 만족하는 키 찾기
keys = deque()
for i in com:
temp = ['' for _ in range(n)]
for idx1, j in enumerate(i):
for idx2,k in enumerate(relation):
temp[idx2] += k[j]
if len(set(temp)) == n:
keys.append(i)
# 최소성 만족하는 키 찾기
while keys:
temp = keys.popleft()
answer += 1
new = deque()
for i in keys:
if len(set(i)-set(temp)) != len(i)-len(temp):
new.append(i)
keys = new
return answer-
combinations 함수로 가능한 조합들 모두 구함
-
유일성을 만족하는 키 찾기 => deque 이용
temp
['100', '200', '300', '400', '500', '600']
['ryan', 'apeach', 'tube', 'con', 'muzi', 'apeach']
['music', 'math', 'computer', 'computer', 'music', 'music']
['2', '2', '3', '4', '3', '2']
['100ryan', '200apeach', '300tube', '400con', '500muzi', '600apeach']
['100music', '200math', '300computer', '400computer', '500music', '600music']
['1002', '2002', '3003', '4004', '5003', '6002']
...이런식으로 temp 를 보면서
중복을 없앤 temp 의 길이가 n 과 같을 때 == 유일할 때
이므로 keys 에 저장
keys
deque([(0,), (0, 1), (0, 2), (0, 3), (1, 2), (0, 1, 2), (0, 1, 3), (0, 2, 3), (1, 2, 3), (0, 1, 2, 3)])keys의 값들을 pop 해가면서 최소성을 만족하는 키 찾기
2018 KAKAO BLIND RECRUITMENT
[1차] 뉴스 클러스터링 - Level 2
https://programmers.co.kr/learn/courses/30/lessons/17677
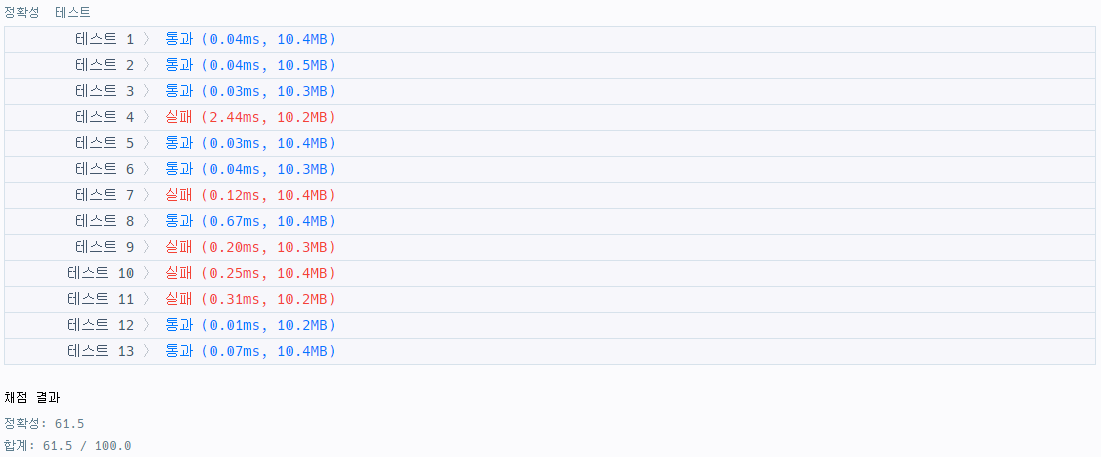
내 풀이 - 실패
import collections
def solution(str1, str2):
answer = 0
### 대문자로 통일
str1 = str1.upper()
str2 = str2.upper()
### str1, str2 => 두글자씩 끊어서 다중집합 만들기
s1 = []
for i in range(len(str1)-1):
if str1[i:i+2].isalpha():
s1.append(str1[i:i+2])
s2 = []
for i in range(len(str2)-1):
if str2[i:i+2].isalpha():
s2.append(str2[i:i+2])
### 둘 다 공집합일 경우 1 이니까 1*65536 return
if len(s1) == 0 and len(s2) == 0:
return 65536
# s1 이 더 짧도록 함
if len(s1) > len(s2):
s1, s2 = s2, s1
### 교집합 구하기
intersection = []
for s in s1:
if s in s2:
intersection.append(s)
### 합집합 구하기
union = s2
count = collections.Counter(s2)
for s in s1:
if s in union:
if count[s] == 0:
union.append(s)
else:
count[s] -= 1
else:
union.append(s)
if len(intersection) == 0 or len(union) == 0:
return 0
return int((len(intersection) / len(union)) * 65536)-
str1, str2 를 대문자로 통일
-
str1, str2 각각 두글자씩 끊어서 다중집합 만들기
=> 두 글자 모두 문자일 경우에만 저장 -
둘 다 공집합일 경우 처리
-
더 짧은 길이를
s1으로 잡음 -
s1의 값 중에s2에 포함된 값들만intersection에 저장 -
s2로 초기화 & 중복을 허용하는 다중집합 처리 위해 Counter 이용
겹치는 부분을 제거하기 위해count[s] -= 1 -
둘 중 하나가 0 이면 return 0 / 나머지는 계산한 값 return
참고
for i in intersection: s1.remove(i) s2.remove(i) union = s1 + s2 + intersection차집합 + 교집합 을 이용하면 런타임 에러가 된다...
remove() 가 느려서인듯
내 풀이 2 - 통과
import collections
def solution(str1, str2):
answer = 0
### 대문자로 통일
str1 = str1.upper()
str2 = str2.upper()
### str1, str2 => 두글자씩 끊어서 다중집합 만들기
s1 = []
for i in range(len(str1)-1):
if str1[i:i+2].isalpha():
s1.append(str1[i:i+2])
s2 = []
for i in range(len(str2)-1):
if str2[i:i+2].isalpha():
s2.append(str2[i:i+2])
### 둘 다 공집합일 경우 1 이니까 1*65536 return
if len(s1) == 0 and len(s2) == 0:
return 65536
# s1 이 더 짧도록 함
if len(s1) > len(s2):
s1, s2 = s2, s1
Counter1 = collections.Counter(s1)
Counter2 = collections.Counter(s2)
inter = list((Counter1 & Counter2).elements())
union = list((Counter1 | Counter2).elements())
if len(union) == 0 and len(inter) == 0:
return 65536
else:
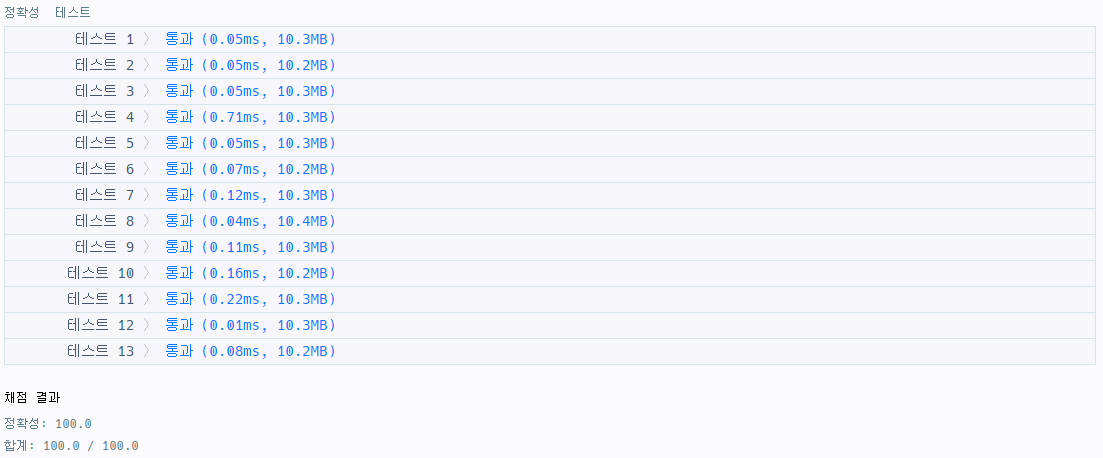
return int(len(inter) / len(union) * 65536)다른 사람의 코드를 참고한 풀이..^^
비슷한데 교집합, 합집합을 구하는 부분이 다르다
s1, s2 의 Counter 를 구해서
교집합은 & 로, 합집합은 | 로 구함
Counter 도 set() 처럼
&,|로 집합연산이 가능하다
그럼 간단하게 해결~
[1차] 캐시 - Level 2
https://programmers.co.kr/learn/courses/30/lessons/17680
내 풀이 - 통과
import heapq
def solution(cacheSize, cities):
answer = 0
cache = []
citylists = []
### 캐시 사이즈가 0 이면 모두 miss
if cacheSize == 0:
return 5 * len(cities)
### cities 를 모두 소문자로 통일
for i in range(len(cities)):
cities[i] = cities[i].lower()
### cacheSize 만큼 먼저 채워주기
i = 0
count = 0
while count < cacheSize:
c = cities.pop(0)
tmp = []
### 중복이 있을 경우는 최신값으로 우선순위 변경
if c in citylists:
while cache:
a = heapq.heappop(cache)
if a[1] != c:
tmp.append(a)
tmp.append((i, c))
heapq.heapify(tmp)
cache = tmp
answer += 1
### 중복 아닐 경우만 count + 1
else:
count += 1
heapq.heappush(cache, (i, c))
citylists.append(c)
answer += 5
i += 1
### 남은 도시들 확인
for c in cities:
if c not in citylists:
a = heapq.heappop(cache)
heapq.heappush(cache, (i, c))
citylists.remove(a[1])
citylists.append(c)
answer += 5
else:
answer += 1
tmp = []
while cache:
a = heapq.heappop(cache)
if a[1] != c:
tmp.append(a)
tmp.append((i, c))
heapq.heapify(tmp)
cache = tmp
i += 1
return answer-
캐시 사이즈가 0 일 경우 모두 miss 니까 전체 길이 * 5 return
-
도시 이름은 모두 소문자로 통일
-
주어진 캐시 사이즈 만큼 먼저 캐시 채우기
중복인 도시가 있으면 우선순위 변경 -
남은 도시들의 캐시 hit / miss 판별
이미 존재하면answer + 1& 우선순위 변경
존재하지 않으면answer + 5& 가장 옛날에 사용한 것을 pop
직접 값들을 다시 heappush 하는 것보다 heapify 가 더 빠름
cache = heapq.heapify(tmp)=> X
heapq.heapify(tmp) cache = tmp=> O
저 단순한 차이가 시간을 많이 잡아먹었다는 점...