
Spring Boot 개발 중 학습이 필요한 내용을 정리하고,
트러블 슈팅 과정을 기록하는 포스팅입니다.
✅ Background
이번 프로젝트에서 클라이언트 단의 특정 json문을 짧은 주기로 Insert 혹은 Update 되도록 하는 기능을 개발해야 했습니다.
마치 Google Docs처럼 타이핑이 쳐질 때마다 혹은 짧은 간격의 시간 마다 그 시간대의 클라이언트 State가 json 형식으로 저장돼야 합니다.
때문에 In-Memory Caching 처리가 가능하고 빠른 I/O 작업 성능 가진 Redis를 활용하기로 했습니다.
하지만 아무리 잦은 I/O 작업에 있어서 성능이 좋은
Redis라고 해도 정말 짧은 주기로 계속해서 I/O 작업이 발생한다면병목 현상으로 인한 부하가 발생하지 않을까? 라는 의문이 들었습니다.
결론적으로는 아무리 고성능의 key-value stroe인 Redis 일지라도 TCP 기반의 클라이언트-서버 모델을 따르며, 때문에 물리적인 네트워크 지연, 3-way handshake 등의 이유로 I/O에 대한 네트워크 병목 현상을 발생할 가능성이 있습니다!
그렇다면 Insert 쿼리 5개를 Redis에 요청보내는 상황을 가정해봅시다.
Redis에 5번의 Insert 쿼리를 날린다고 가정했을 때,
Redis에서는 클라이언트의 요청 -> 서버의 응답 처리를 5번 반복합니다.
즉, 총 5번의 Request / Response 작업이 발생하게 되며, 각각의 Reqeust는 이전의 Response를 기다렸다가 해당 Request 명령을 처리할 수 있습니다.
이러한 방식은 더 많은 Request를 처리하기 힘들며, RTT(Round Trip Time)가 길어지기 때문에 서버 전체 성능에 좋지 않은 영향을 미치게 됩니다.
✅ Redis Pipeline
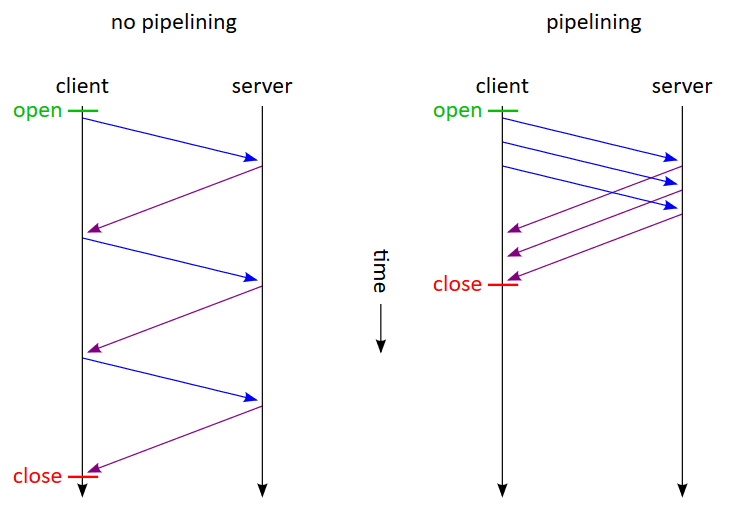
때문에 우리는Redis Pipeline을 활용해야합니다.
Redis Pipeline는 수많은 요청을 보내기 위해 Pipeline을 형성한 후, 모든 Reqest를 Pipeline에 실어서 한 번에 보냅니다.
즉, Redis Pipeline을 통해 각각의 Response를 기다리지 않고,
한번에 여러개의 명령어를 전송할 수 있게 됐고, 비동기적으로 그에 대한 Response를 받아 옵니다.
✅ Spring boot Redis Pipeline
Spring boot 환경에서 Redis Pipeline을 활용하는 제 코드를 확인해봅시다.
아래의 saveToRedis 메소드는 TextMemoState 객체 하나를 이용해서 Redis에 여러개의 insert 작업이 진행되는 Dao 패키지 클래스 안의 메소드입니다.
RedisTemplate의 executePipelined 메소드를 이용해서 Pipeline을 시작할 수 있으며 해당 Pipeline의 connection에 직접 명령어를 넣는 방식입니다.
public TextMemoState saveToRedis(TextMemoState textMemoState) {
// 파이프라인 start
redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
Map<String, Object> map = objectMapper.convertValue(textMemoState, Map.class);
// Request 1. Redis Set에 멤버 add
connection.sAdd(keySerializer.serialize(defaultStateKey), valueSerializer.serialize(defaultStateKey + "_history:" + textMemoState.getId()));
// 각각의 객체들 redis에 hash 타입으로 set
for (String key : map.keySet()) {
// Request 2. hash set
connection.hashCommands().hSet(keySerializer.serialize(defaultStateKey + "_latest"),
valueSerializer.serialize(key), valueSerializer.serialize(map.get(key)));
// Request 3. hash set
connection.hashCommands().hSet(keySerializer.serialize(defaultStateKey + "_history:" + textMemoState.getId()),
valueSerializer.serialize(key), valueSerializer.serialize(map.get(key)));
}
return null;
});
return textMemoState;
}위의 코드를 살펴 보면, 해당 코드에서는 총 3번의 Resqest를 Pipeline에 추가합니다.
Set 자료형에 멤버 insert 1회, Hash 자료형 insert 2회가 일어납니다.
Java의 RedisTemplate가 제공하는 손쉬운 메소드를 통하는 것이 아닌
connection 객체를 통해서 실제로 Redis Console에서 사용하는 명령어 방식을 이용하기 때문에, Redis Console에서 명령어를 테스팅하신 후 작업하는 것을 추천합니다.
해당 코드에서는 단순히 String 자료형을 insert하는 것이 아닌 Hash 자료형을 insert 하기 때문에 코드가 조금더 복잡해졌습니다.
이번 프로젝트를 하면서 성능 부분에서 많은 고민을 하고, 개선을 할 수 방법들을 많이 찾고 있습니다. 해당 과정에서 많이 배우고 성장하는 것 같습니다.
✅ 참고
https://tjdrnr05571.tistory.com/7
https://kn100.me/redis-pipelining/
https://the-earth.tistory.com/entry/redis-pipeline
https://planbs.tistory.com/entry/Redis-Pipelining

Can you put the code on github?
Thanks