성격 유형 검사하기
문제 설명
나만의 카카오 성격 유형 검사지를 만들려고 합니다.
성격 유형 검사는 다음과 같은 4개 지표로 성격 유형을 구분합니다. 성격은 각 지표에서 두 유형 중 하나로 결정됩니다.

4개의 지표가 있으므로 성격 유형은 총 16(=2 x 2 x 2 x 2)가지가 나올 수 있습니다. 예를 들어, "RFMN"이나 "TCMA"와 같은 성격 유형이 있습니다.
검사지에는 총 n개의 질문이 있고, 각 질문에는 아래와 같은 7개의 선택지가 있습니다.
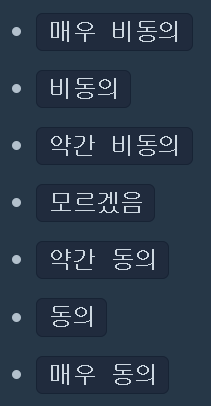
각 질문은 1가지 지표로 성격 유형 점수를 판단합니다.
예를 들어, 어떤 한 질문에서 4번 지표로 아래 표처럼 점수를 매길 수 있습니다.
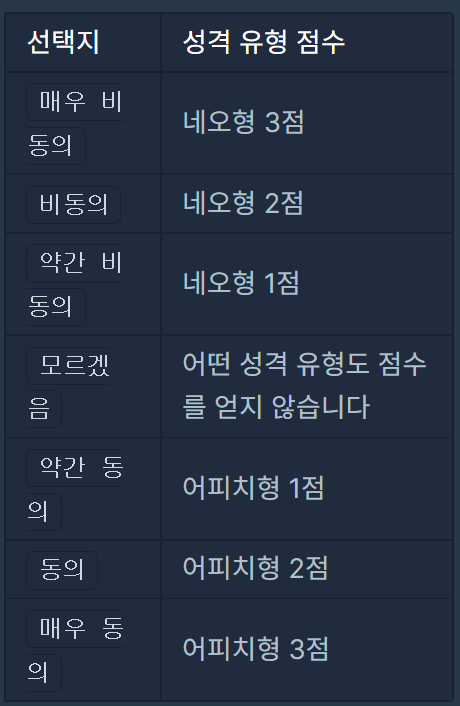
이때 검사자가 질문에서 약간 동의 선택지를 선택할 경우 어피치형(A) 성격 유형 1점을 받게 됩니다. 만약 검사자가 매우 비동의 선택지를 선택할 경우 네오형(N) 성격 유형 3점을 받게 됩니다.
위 예시처럼 네오형이 비동의, 어피치형이 동의인 경우만 주어지지 않고, 질문에 따라 네오형이 동의, 어피치형이 비동의인 경우도 주어질 수 있습니다.
하지만 각 선택지는 고정적인 크기의 점수를 가지고 있습니다.
- 매우 동의나 매우 비동의 선택지를 선택하면 3점을 얻습니다.
- 동의나 비동의 선택지를 선택하면 2점을 얻습니다.
- 약간 동의나 약간 비동의 선택지를 선택하면 1점을 얻습니다.
- 모르겠음 선택지를 선택하면 점수를 얻지 않습니다.
검사 결과는 모든 질문의 성격 유형 점수를 더하여 각 지표에서 더 높은 점수를 받은 성격 유형이 검사자의 성격 유형이라고 판단합니다. 단, 하나의 지표에서 각 성격 유형 점수가 같으면, 두 성격 유형 중 사전 순으로 빠른 성격 유형을 검사자의 성격 유형이라고 판단합니다.
질문마다 판단하는 지표를 담은 1차원 문자열 배열 survey와 검사자가 각 질문마다 선택한 선택지를 담은 1차원 정수 배열 choices가 매개변수로 주어집니다. 이때, 검사자의 성격 유형 검사 결과를 지표 번호 순서대로 return 하도록 solution 함수를 완성해주세요.
제한사항
1 ≤ survey의 길이 ( = n) ≤ 1,000
survey의 원소는 "RT", "TR", "FC", "CF", "MJ", "JM", "AN", "NA" 중 하나입니다.
survey[i]의 첫 번째 캐릭터는 i+1번 질문의 비동의 관련 선택지를 선택하면 받는 성격 유형을 의미합니다.
survey[i]의 두 번째 캐릭터는 i+1번 질문의 동의 관련 선택지를 선택하면 받는 성격 유형을 의미합니다.
choices의 길이 = survey의 길이
choices[i]는 검사자가 선택한 i+1번째 질문의 선택지를 의미합니다.
1 ≤ choices의 원소 ≤ 7

1. dict를 이용한 hash구성 - 알고리즘
def solution(survey, choices):
answer = ""
choices_dict = {"R":0,"T":0,"C":0,"F":0,"J":0,"M":0,"A":0,"N":0}
for i,j in zip(survey,choices):
if j > 4:
choices_dict[i[1]] += j-4
else:
choices_dict[i[0]] += 4-j
if choices_dict["R"] >= choices_dict["T"]:
answer += "R"
else:
answer += "T"
if choices_dict["C"] >= choices_dict["F"]:
answer += "C"
else:
answer += "F"
if choices_dict["J"] >= choices_dict["M"]:
answer += "J"
else:
answer += "M"
if choices_dict["A"] >= choices_dict["N"]:
answer += "A"
else:
answer += "N"
return answer-
이 문제의 핵심은 hasp map구현을 통한 key값에 따른 value값 추출인 듯 하다.
-
zip내장함수를 통해 survey와 choices의 요소를 한번에 불러와 설문지에 따른 점수가점을 key에 맞춰 더해준다.
-
dict를 모두 구성한 후에 key값에 따라 어떠한 성격유형인지 추출해주고, 같은 점수일 경우 알파벳 순서에 따라 먼저 나오는 알파벳이 나와야하므로 그에 따라 크기를 판별해준다.
-
key값에 따라 나오는 요소들이 단순 반복이라 조금 더 간편하고 효율적인 알고리즘이 있는지 찾아보고 추후에 다시 포스팅해야겠다.
