@RestController와 @Controller의 차이점은 무엇인가요?
@RestController, @Controller
- 모두 스프링 프레임워크에서
웹 요청을 처리하는 클래스에 사용하는 애너테이션- 반환 방식과 목적이 다름

@Controller
- 전통적인 MVC 패턴의 컨트롤러에 사용
- 반환 타입이
String이면 뷰(View) 이름으로 처리됨 - 데이터를 반환하려면
@ResponseBody를메서드마다붙여야 함
: 웹 페이지 렌더링(템플릿, HTML) - Thymeleaf, JSP
@Controller
public class HomeController {
@GetMapping("/hello")
public String hello(Model model) {
model.addAttribute("msg", "안녕하세요!");
return "hello"; // → templates/hello.html 렌더링
}
@GetMapping("/json")
@ResponseBody
public String json() {
return "데이터 응답"; // → HTTP Body에 그대로 응답
}
}@RestController
- REST API 개발에 최적화된 컨트롤러
- 클래스 자체가
@ResponseBody를 포함함 --> 모든 메서드가JSON으로 반환됨 - 주로 백엔드 API 서버 구현시 사용
:: REST API 서비스 (데이터 전달 중심) - Vue, React
@RestController
public class ApiController {
@GetMapping("/api/hello")
public String hello() {
return "안녕하세요!"; // → {"message":"안녕하세요!"} 형태로 JSON 응답
}
@GetMapping("/api/user")
public User getUser() {
return new User("홍길동", 30); // → 객체가 자동으로 JSON 변환되어 반환
}
}PathVariable, @RequestBody, @RequestParam의 차이와 각각 언제 사용하는지 설명해주세요.
@PathVariable, @RequestParam, @RequestBody
- 모두 스프링 컨트롤러에서
HTTP 요청의 데이터를 받아오는 방식- 데이터의 위치와 사용 목적이 다름

@PathVariable - 경로변수 매핑
@GetMapping("/users/{id}")
public User getUser(@PathVariable Long id) {
return userService.findById(id);
}- REST API 에서 리소스를 식별할 때
- 일반적으로 고유 ID 나 슬러그에 사용
:: 명확한 리소스 지정 (GET)
@RequestParam - 쿼리 파라미터 매핑
@GetMapping("/search")
public List<User> search(@RequestParam String keyword, @RequestParam(defaultValue = "1") int page) {
return userService.search(keyword, page);
}- 검색어, 필터, 페이지 번호, 정렬 조건 등 선택적 매개변수
- URL 에 노출되어도 괜찮은 단순 옵션 데이터
:: 선택적 조건 (GET)
@RequestBody – 요청 본문을 객체로 변환
@PostMapping("/users")
public User createUser(@RequestBody UserDTO userDto) {
return userService.save(userDto);
}// 호출 예
POST /users
Content-Type: application/json
{
"name": "홍길동",
"age": 30
}- 요청 본문의 JSON 데이터를 자바 객체로 자동 변환해 전달
- 클라이언트가 보낸 JSON 데이터를 서버에서 받아서 처리할 때
- 대량의 데이터 전달이나 복잡한 구조가 필요할 때
- 보통 POST, PUT, PATCH 요청에 사용
API 응답을 규격화할 때 ResponseEntity를 사용하는 이유는 무엇인가요?
응답의 모든 요소(HTTP 상태 코드, 헤더, 바디)를 세밀하게 제어할 수 있기 때문
--> REST API를 만들 때 클라이언트와의 통신 규약을명확하고 일관성 있게 유지하는 데 매우 중요한 도구
ResponseEntity 란?
ResponseEntity<T>는 스프링 프레임워크에서 제공하는 HTTP 응답 전체를 구성할 수 있는 객체
- 기본적으로 단순한 JSON 응답이면
@RestController + 객체반환만으로 충분하지만, 상태 코드 조정이나 헤더 설정이 필요한 경우엔 반드시 ResponseEntity 사용- 일반적으로 서비스의 응답 표준을 정의한 공통
Response DTO와 함께 사용됨
ResponseEntity 를 쓰는 주요 이유
1. HTTP 상태 코드 설정 가능
return new ResponseEntity<>("등록 성공", HttpStatus.CREATED);→ 클라이언트가 요청이 성공했는지, 실패했는지를 정확한 HTTP 코드로 구분 가능
2. 응답바디 + 상태코드 + 헤더 모두 설정 가능
HttpHeaders headers = new HttpHeaders();
headers.add("X-Custom-Header", "테스트");
return new ResponseEntity<>(userDto, headers, HttpStatus.OK);→ 클라이언트에게 커스텀 헤더를 포함한 정교한 응답 전송 가능
3. 에러 응답 일관성 있게 처리
return ResponseEntity
.status(HttpStatus.BAD_REQUEST)
.body(new ErrorResponse("잘못된 요청입니다."));→ 모든 에러 응답을 같은 포맷(JSON 구조 등)으로 맞출 수 있어, 프론트엔드 처리 편리
4. 빌더 패턴 지원 → 가독성 향상
return ResponseEntity.ok(userDto); // 200 OK
return ResponseEntity.status(HttpStatus.NOT_FOUND).body("사용자를 찾을 수 없습니다");→ 코드가 간결하고 읽기 쉬움
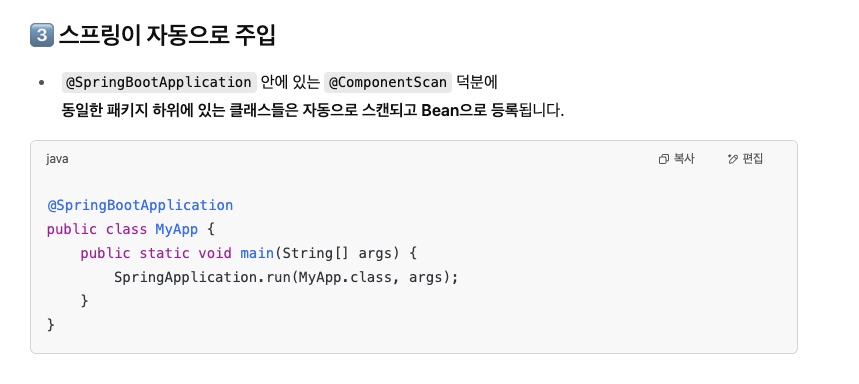
스프링에서 DI란 무엇이며, Controller-Service-Repository 간에는 어떻게 DI를 적용하나요?
DI (Dependency Injection, 의존성 주입)
- 스프링이 가진 가장 강력한 기능 중 하나
객체 간의 의존 관계를 직접 생성하지 않고, 외부(주로 스프링 컨테이너)에서 주입해주는 방식
DI(의존성 주입) 이란?
- 객체 간 결합도를 낮추고, 테스트와 유지보수를 쉽게 만들어 줌
// 직접 생성하는 방식 (X - 강한 결합)
UserService service = new UserService(new UserRepository());
// 의존성 주입 방식 (O - 약한 결합)
@Autowired
UserService service;

실전 구조: Controller → Service → Repository
[HTTP 요청]
↓
[Controller] → 외부 요청 처리, 요청 DTO ↔ 응답 DTO
↓
[Service] → 비즈니스 로직, 트랜잭션 처리
↓
[Repository] → DB 접근, JPA or SQL 실행
| 계층 | 애너테이션 | 역할 |
|---|---|---|
| Controller | @RestController, @Controller | HTTP 요청/응답 처리, 외부 통신 |
| Service | @Service | 비즈니스 로직 수행 |
| Repository | @Repository | 데이터 접근, DB와 직접 통신 (JPA, MyBatis 등) |


1. Repository 클래스
@Repository
public class UserRepository {
public User findById(Long id) {
// DB 조회 로직
}
}2. Service
@Service
public class UserService {
private final UserRepository userRepository;
// 생성자 주입
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User getUser(Long id) {
return userRepository.findById(id);
}
}3. Controller 클래스
@RestController
@RequestMapping("/users")
public class UserController {
private final UserService userService;
// 생성자 주입
public UserController(UserService userService) {
this.userService = userService;
}
@GetMapping("/{id}")
public ResponseEntity<User> getUser(@PathVariable Long id) {
return ResponseEntity.ok(userService.getUser(id));
}
}- 생성자 주입을 가장 권장 (불변성 보장, 테스트 용이성 향상)
@Autowired는 생성자에 생략 가능 (Spring 4.3+)- 모든 클래스는 인터페이스 분리와 함께 사용하는 게 이상적

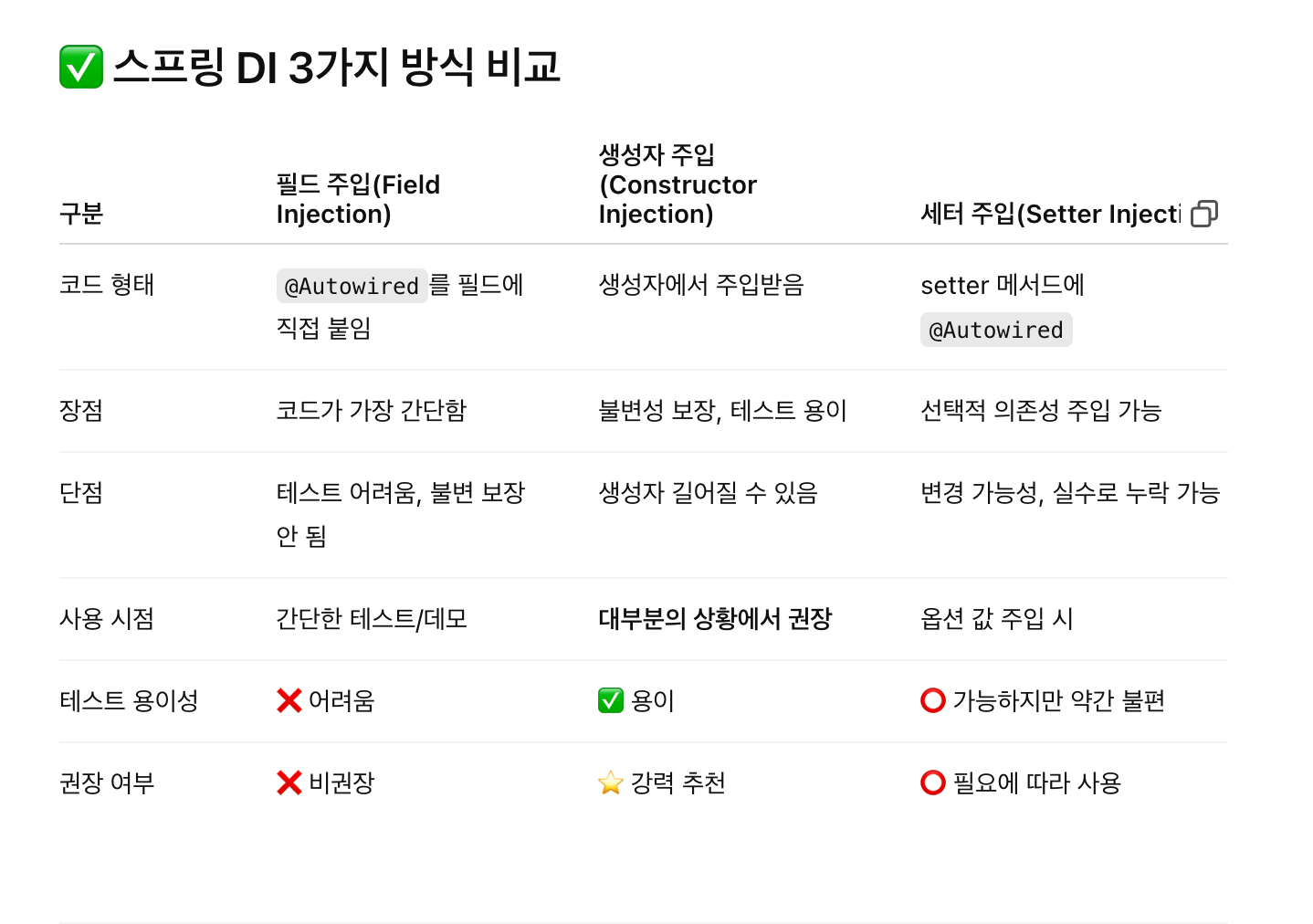
1. 필드 주입 (❌ 비권장)
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
// 직접 접근 불가 → 테스트 시 주입 어려움
}- 테스트에서
ReflectionTestUtils등으로 주입해야 하므로 매우 불편 - final로 선언 불가능 → 불변성 보장 X
- 순환 참조 문제 시 디버깅 어려움
2. 생성자 주입 (✅ 가장 권장)
@Service
public class UserService {
private final UserRepository userRepository;
// Spring 4.3 이후에는 @Autowired 생략 가능
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
}- 의존성이 명확히 드러나고, 컴파일 타임에 체크됨
- 테스트 시 쉽게 Mock 객체 주입 가능
final사용 가능 → 불변성 보장- 코드 가독성 및 유지보수 우수
3. 세터 주입 (⭕ 옵션일 경우 사용)
@Service
public class NotificationService {
private EmailSender emailSender;
@Autowired
public void setEmailSender(EmailSender emailSender) {
this.emailSender = emailSender;
}
}장점
- 선택적인 의존성 주입 가능
- 동작 중에 변경하거나, null 주입 가능 (단, 안정성↓)
단점
- 실수로 의존성을 주입하지 않을 수 있음 (NPE 가능성)
- final 사용 불가
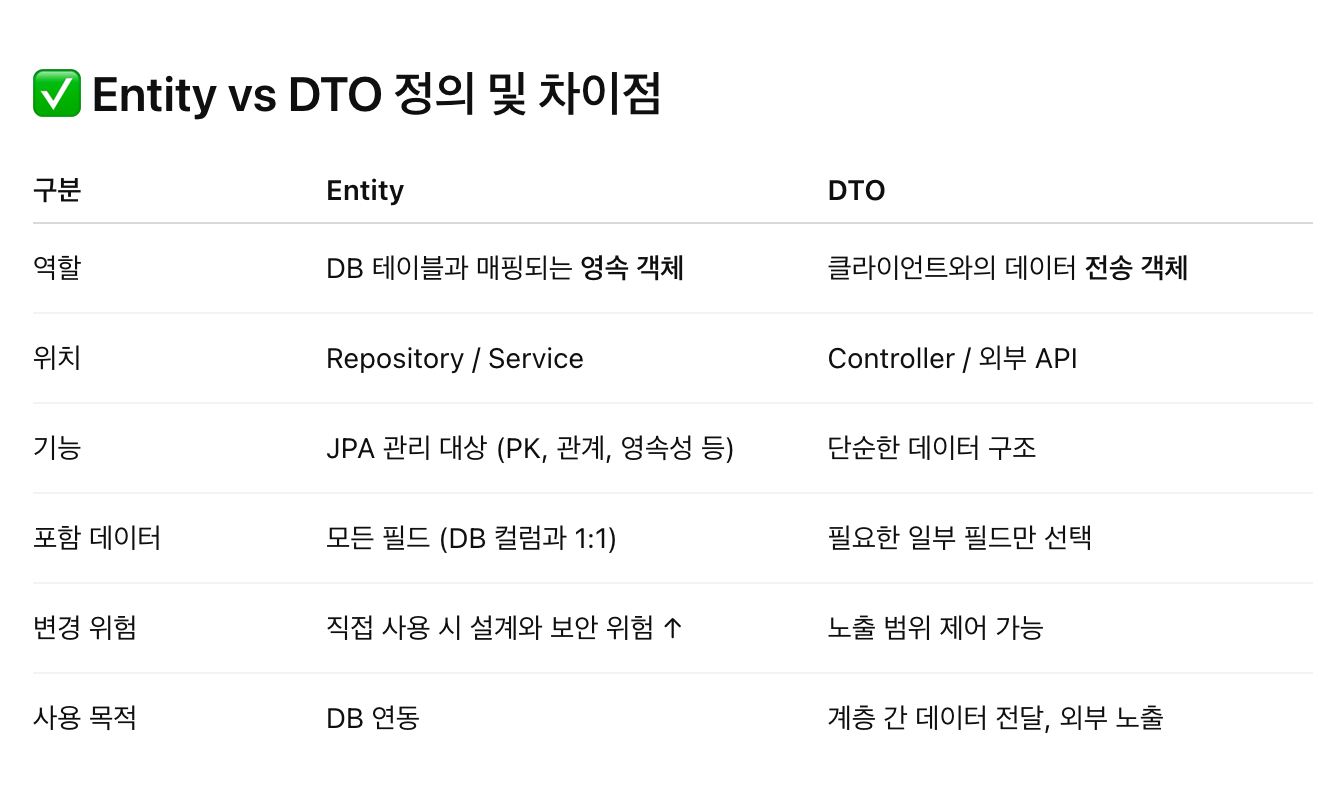
Entity와 DTO를 분리해서 사용하는 이유는 무엇인가요?
- 애플리케이션의 구조를 더 견고하고 유연하게 유지하기 위해
계층 간 책임 분리(Separation of Concerns)와 보안, 유지보수성 측면에서 매우 중요- Entity를 그대로 반환하면
Jackson 순환 참조 문제(StackOverflowError)가 생길 수 있음
--> DTO로 해결 가능!
ModelMapper, MapStruct 등의 라이브러리를 사용하면 Entity ↔ DTO 간 변환을 자동화할 수 있어 생산성이 향상됨
왜 Entity와 DTO를 분리해야 할까?
1. 보안 및 데이터 노출 최소화
Entity 를 그대로 API 로 반환하면 민감 정보(PW, 내부 식별자 등)가 그대로 노출될 수 있음
2. API 설계와 DB 설계를 분리
- API는 변경이 잦고, 다양한 클라이언트가 요구사항을 가질 수 있음
- 반면 Entity는 DB 구조와 밀접하게 연관되므로 변경에 신중해야 함
--> DTO를 사용하면 API 요구사항에 맞게 유연하게 응답 구조 조정 가능!
3. 성능 최적화
- Entity는 연관 객체까지 모두 로딩될 수 있음 (EAGER 등)
- DTO는 필요한 필드만 포함하므로 불필요한 연관 객체 조회 없이 최적화 가능
// 필요 없는 필드도 모두 로딩됨
return userRepository.findAll(); // Entity 직접 반환 ❌
// 필요한 필드만 선택적으로 응답
return userService.getUserList(); // DTO 반환 ⭕4. 계층 간 책임 분리 (SoC: Separation of Concerns)
- Entity: 데이터베이스와의 연동 책임
- DTO: 뷰/컨트롤러 계층과의 데이터 전달 책임
--> 역할을 분리하면 테스트, 유지보수, 리팩토링이 훨씬 수월해짐
@Transactional 어노테이션은 어떤 기능을 하고, 언제 사용하는 것이 적절한가요?
@Transactional
- Spring에서 데이터베이스 트랜잭션을 관리할 수 있도록 해주는 핵심 애너테이션
- 비즈니스 로직이 실행되는 동안 트랜잭션을 시작하고, 예외가 발생하면 롤백하며, 정상적으로 끝나면 커밋되도록 함

언제 사용하는가?
- 하나의 작업이 여러 쿼리로 구성되어 있고, 부분 성공이 발생하면 안 되는 경우
- DB 일관성을 반드시 보장해야 하는 비즈니스 로직에 사용
동작 방식
@Transactional은 프록시 기반 AOP를 통해 동작함- 스프링이 해당 메서드를 감싸서 트랜잭션을 시작하고, 종료 시 자동으로 처리
주의할 점
1. checked 예외는 기본적으로 롤백되지 않음
- unchecked 예외(RuntimeException, Error)만 롤백 대상
checked 예외도 롤백하고 싶다면 다음처럼 설정
@Transactional(rollbackFor = Exception.class)2. 메서드가 public이어야 함
- 프록시 기반이기 때문에
private/protected메서드에는 동작하지 않음
3. 자기 자신의 메서드 호출에는 적용되지 않음
public void outer() {
inner(); // @Transactional이어도 적용되지 않음
}반드시 다른 클래스를 통해 호출돼야 트랜잭션이 적용됩니다.
- 단순 조회 쿼리에는
@Transactional(readOnly = true)를 사용하면 성능이 향상 (스냅샷, flush 등 최소화)@Transactional은 Service 계층에만 붙이는 것이 가장 이상적입니다 (비즈니스 로직 책임이 집중되는 곳)- 트랜잭션 범위를 좁게 설정해서 장시간 락 점유를 피하세요. (예: 외부 API 호출은 트랜잭션 안에서 하지 말 것)
JPA의 영속성 컨텍스트(Persistence Context)의 특징과 역할은 무엇인가요?
영속성 컨텍스트(Persistence Context)
- JPA(Java Persistence API)에서 가장 중요한 개념 중 하나
- 이 개념을 이해해야 엔티티의 생명주기, 1차 캐시, 변경 감지, 지연 로딩 등 JPA의 핵심 기능을 정확히 다룰 수 있음
영속성 컨텍스트란?
엔티티(Entity) 객체들을 관리하는 일종의 메모리(캐시) 공간
- EntityManager가 관리하는 객체 저장소
- DB에서 가져온 엔티티를 영속 상태로 만들어 저장
- 1차 캐시, 변경 감지 등 JPA의 주요 기능은 이 컨텍스트에서 일어남

1차 캐시
User user1 = em.find(User.class, 1L); // DB 조회
User user2 = em.find(User.class, 1L); // 캐시에서 조회됨 (쿼리 없음)→ 같은 트랜잭션 내에서 user1 == user2는 true
불필요한 DB 조회를 방지함으로써 성능 향상
같은 엔티티 ID로 여러 번 조회해도 DB 접근 없이 캐시된 객체 반환
2. 엔티티 동일성 보장
user1.setName("변경됨");
em.flush(); // 자동으로 UPDATE 발생→ 같은 ID의 엔티티는 하나만 존재하므로, 같은 참조로 값 변경 추적 가능
3. 변경 감지(Dirty Checking)
- 엔티티가 영속 상태일 때 값을 변경하면, flush 시점에 자동으로 변경 내용을 감지해서 SQL을 생성합니다.
@Transactional
public void updateName(Long id, String name) {
User user = em.find(User.class, id);
user.setName(name); // UPDATE 쿼리 자동 생성됨
}명시적으로 em.merge() 호출할 필요 없음
4. 트랜잭션 범위 내 유지
- 영속성 컨텍스트는 트랜잭션 범위 내에서만 유지되며, 트랜잭션이 끝나면 컨텍스트도 초기화됩니다.
- 따라서 트랜잭션 외부에서 엔티티 상태를 변경해도 DB에는 반영되지 않음.
5. 지연 로딩 (Lazy Loading)
- 관계 매핑된 객체는 실제로 접근할 때까지 DB 조회를 지연함
- 초기에는 프록시 객체만 존재하고, 필요할 때 실제 SELECT 쿼리가 나감

User user = new User(); // 비영속
em.persist(user); // 영속
em.detach(user); // 준영속
em.remove(user); // 삭제💡 팁 (Tip!)
- 영속성 컨텍스트는 트랜잭션과 짝을 이룸. 즉, 트랜잭션을 시작해야 영속성 컨텍스트도 활성화됨
- 엔티티는 절대 컨트롤러에서 수정하지 말고, 서비스 계층 내에서만 조작하기
- 엔티티를 너무 오래 영속 상태로 유지하면 메모리 낭비 및 비효율적인 flush 문제가 생길 수 있으니, 트랜잭션 범위를 짧고 명확하게 유지
JPA 사용 시 발생할 수 있는 N+1 문제란 무엇이며, 이를 해결하는 방법에는 어떤 것들이 있나요?
- 성능 최적화에서 반드시 고려해야 할 핵심 이슈
- 연관 관계를 조회할 때 Lazy 로딩 전략과 함께 사용하면 무심코 발생
N + 1 문제란?
1개의 쿼리를 실행했는데, 추가적으로 N개의 쿼리가 발생하는 상황을 말함
List<Team> teams = teamRepository.findAll(); // 1번 쿼리 (팀 전체 조회)
for (Team team : teams) {
System.out.println(team.getMembers()); // N번 쿼리 (각 팀의 멤버 조회)
}- 위 코드에서
teams가 5개라면?
→ 총 1 + 5 = 6번의 SQL 쿼리 발생
- 이유는 연관된 members 컬렉션이 지연 로딩(LAZY)으로 되어 있어, 접근할 때마다 별도의 쿼리가 발생하기 때문입니다.
❌ 왜 문제가 되는가?
- 쿼리 수 증가 → 성능 저하
- DB 부하 증가 및 네트워크 트래픽 증가
- 페이지 단위 반복 로직에서 더욱 심각해짐
✅ 해결 방법
1. Fetch Join 사용하기 (JPQL) ✅ 가장 일반적이고 강력한 방법
@Query("SELECT t FROM Team t JOIN FETCH t.members")
List<Team> findAllWithMembers();JOIN FETCH를 사용하면 한 번의 쿼리로 연관된 엔티티까지 한꺼번에 가져옵니다.
SELECT t.*, m.*
FROM team t
JOIN member m ON m.team_id = t.id2. EntityGraph 사용하기 (어노테이션 방식)
@EntityGraph(attributePaths = {"members"})
@Query("SELECT t FROM Team t")
List<Team> findAllWithMembers();@EntityGraph는 지연 로딩 설정을 무시하고 명시된 연관 관계를 즉시 로딩합니다.
3. Batch Size 조정하기 (Hibernate 설정)
여러 건을 한 번에 조회할 수 있게 IN 쿼리로 묶어서 실행
spring.jpa.properties.hibernate.default_batch_fetch_size=100Hibernate는 내부적으로 IN 쿼리로 최적화
→ SELECT * FROM member WHERE team_id IN (?, ?, ?, ...)
단점: 완전한 해결책은 아니고 임시 완화용
4. DTO 직접 조회 (JPQL Projection)
@Query("SELECT new com.example.TeamDto(t.name, m.name) FROM Team t JOIN t.members m")
List<TeamDto> findTeamDtos();필요한 필드만 조회하여 과도한 엔티티 로딩 방지
💡 팁 (Tip!)
- 복잡한 연관 관계에서는
Fetch Join + DTO 프로젝션 혼합 전략이 유효 - 컬렉션(
OneToMany)에 Fetch Join은 페이징 불가!
→ 해결하려면 중첩 조회 + DTO 매핑 전략 필요 - 기본적으로
LAZY를 쓰되, 필요한 곳에서만 명시적으로 JOIN FETCH 또는 EntityGraph를 쓰는 게 베스트 프랙티스임
🚨 주의할 점
EAGER전략으로 바꾸는 것은 권장하지 않습니다.
→ 모든 연관 객체를 항상 즉시 로딩하게 되어, 오히려 성능 더 나빠질 수 있음
