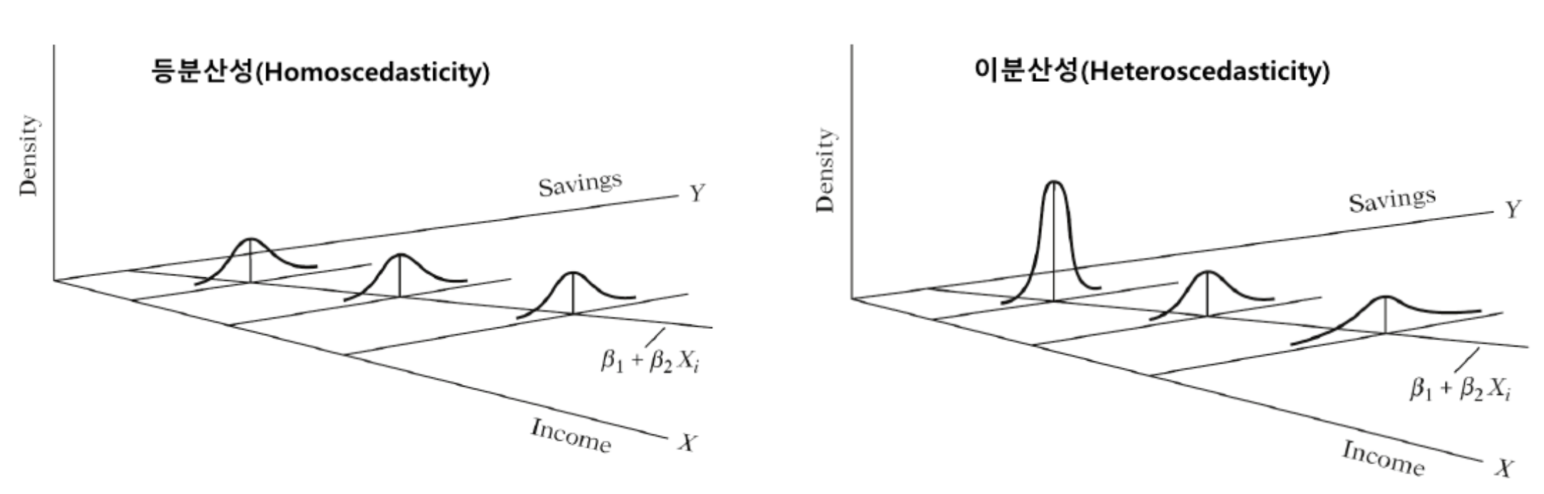
1. Heteroscedasticity와 Homoscedasticity
Heteroscedasticity와 Homoscedasticity 잔차의 분산 또는 퍼짐에 대한 특성을 설명합니다. 특히 잔차의 Homoscedasticity는 회귀 분석의 중요한 가정 중 하나입니다.
Heteroscedasticity
예측 변수의 값이 변함에 따라 잔차의 분포가 변하게 됩니다. Heteroscedasticity의 존재는 회귀 분석의 가정 중 하나인 공분산 동질성을 위반하는 것으로, 일반적인 MSE 회귀 분석에서 문제가 발생할 수 있습니다.
Homoscedasticity
잔차의 분산이 일정하고, 잔차의 분포가 일정한 것을 이야기합니다. Homoscedasticity 가정이 충족되면, 회귀 계수의 추정치가 효율적이고 편향되지 않으며, 계수들의 표준 오차도 신뢰할 수 있어, 통계적 추론이 유효하게 됩니다.
2. Type of Stationarity
Strict Stationarity
Strict Stationarity는 시계열 데이터의 확률 분포가 시간에 상관없이 일정한 경우를 의미합니다. 즉, 확률 분포, 평균 및 자기공분산이 시간에 관계없이 일정하게 유지되는 경우입니다. 이러한 가정 하에 시계열의 모든 통계적 속성은 시간이 지나도 동일하게 유지됩니다. 하지만 실제 데이터에서 완전한 엄격한 정상성은 흔하지 않습니다.
Weak Stationarity (시계열 정상성)
Weak Stationarity는 시계열의 평균과 분산이 시간에 따라 일정하고 자기공분산이 시간차에만 의존하며, 시차(lag)에 관계없이 동일한 패턴을 가진다는 것을 의미합니다. 대부분의 시계열 분석은 Weak Stationarity 가정을 기반으로 합니다.
Trend Stationary (추세 정상성)
Trend Stationary는 시계열 데이터가 시간에 따라 추세를 가지지만 평균이 시간에 따라 일정한 상태를 의미합니다. 즉, 데이터가 장기적으로 변동하지만 장기적인 평균은 시간에 따라 일정하다는 것을 의미합니다. 이 경우, 시계열 데이터에 차분(Differencing) 등의 전처리를 통해 평균을 상수 수준으로 만들어 약한 정상성을 만족시킬 수 있습니다.
3. The importance of stationarity
시계열 데이터를 분석할 때의 정상성은 통계적으로 타당하고 정확한 결과를 얻게 해줍니다. 데이터가 정상성을 만족하지 않을 때는 이를 개선하기 위한 적절한 방법들을 적용하여 데이터를 더욱 유의미하고 신뢰할 수 있는 형태로 만들 수 있습니다.
정상성 가정에 기반한 통계적 추론
정상성을 만족하는 데이터는 평균과 분산이 일정하므로, 이를 기반으로 한 통계적 추론이 유효하고 신뢰할 수 있습니다. 만약 데이터가 정상성을 만족하지 않는다면, 오류가 발생할 가능성이 크며, 추론 결과의 신뢰성이 떨어집니다.
예측의 정확성 향상
정상성을 가진 시계열 데이터의 경우, 이전 패턴이 미래에도 유사하게 반복될 가능성이 높습니다. 따라서 정상성을 가진 데이터를 기반으로 모델을 학습하고 예측하는 것이 더 정확한 결과를 얻을 수 있습니다.
모델의 안정성
정상성을 가지는 데이터는 시간에 따라 변하지 않는 통계적 속성을 가지므로, 모델의 계수들이 안정적으로 추정됩니다. 반면, 정상성이 없는 데이터에서는 모델이 불안정하게 되고, 모델의 결과가 크게 달라질 수 있습니다.
다른 데이터와의 비교
다른 정상성을 가진 시계열 데이터와 비교하여 패턴을 파악하고, 상호간의 유사성을 파악하는 것이 쉽습니다. 만약 데이터들이 정상성을 만족하지 않는다면, 비교가 어려워질 수 있습니다.
4. Stationarity Transformation: The method of transforming a financial time series into stationarity
Stationarity Transformation를 활용해 금융 시계열 데이터를 정상성을 만족하는 형태로 변환할 수 있습니다. 이 방법은 데이터의 평균과 분산이 시간에 따라 일정하도록 만들거나, 자기상관 구조를 보다 안정적인 상태로 조정하여 정상성을 만족시키는 과정을 포함합니다. 이러한 변환은 시계열 분석 및 예측에 필수적인 전처리 과정 중 하나로 사용됩니다. 예를 들어 차분(Differencing)을 통한 데이터 변환은 주로 비정상 시계열 데이터를 정상성을 갖는 시계열로 변환하는데 자주 사용됩니다.
5. Autocorrelation
Autocorrelation(자기상관)은 시계열 데이터에서 자기와 자기 자신의 과거 값 사이의 상관관계를 측정하는 통계적 개념입니다. 즉, 시계열 데이터에서 한 시점의 값이 이전 시점의 값과 얼마나 관련이 있는지를 나타냅니다.
시계열 패턴 파악
자기상관을 통해 시계열 데이터 내에 어떤 주기성과 패턴이 존재하는지 파악할 수 있습니다. 자기상관 함수(ACF)를 통해 시계열 데이터의 자기상관 구조를 시각화하면 데이터가 어떤 주기적인 변동을 가지는지 파악할 수 있습니다. 이를 통해 데이터의 계절성과 주기성을 이해할 수 있습니다.

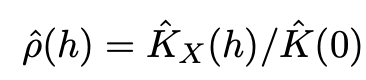
모델링과 예측
자기상관은 시계열 데이터를 모델링하고 미래 값을 예측하는데 도움이 됩니다. 시계열 데이터의 자기상관 구조를 이해하면, 자기회귀 이동평균 모델(ARIMA)과 같은 적절한 모델을 선택하고 미래 값을 예측하는데 사용할 수 있습니다. 자기상관을 고려하지 않고 모델링하면 예측의 정확도가 떨어질 수 있습니다.
정상성 판단
정상성은 시계열 분석에서 중요한 가정 중 하나입니다. 자기상관 함수를 사용하여 자기상관이 시간에 따라 빠르게 감소하는지 확인함으로써 데이터의 정상성 여부를 판단할 수 있습니다. 정상성이 충족되지 않으면 시계열 분석 결과의 신뢰성이 떨어질 수 있습니다.
모델 평가
자기상관은 모델의 적합성을 평가하는데도 사용됩니다. 예측 모델을 평가할 때, 자기상관을 통해 예측 오류의 패턴을 파악하고 모델의 성능을 개선할 수 있습니다.
오류 검출
자기상관은 데이터 내에 숨겨진 패턴이나 구조를 찾는데 도움이 됩니다. 특히 예측 오류에 자기상관이 있으면, 이는 모델에 남아 있는 정보가 있다는 것을 의미하며, 모델이 개선될 수 있음을 알 수 있습니다.
6. Partial Autocorrelation
Partial Autocorrelation (PACF)는 시계열 데이터에서 한 시점의 값과 그와 일정 시간차(lag)만큼 떨어진 과거 값들과의 상관관계를 측정하는 통계적 개념입니다. PACF는 자기상관 함수(ACF)의 영향을 배제한 상태에서 두 변수 간의 상관성을 측정합니다.

PACF는 시계열 데이터 분석과 모델링에서 중요한 도구로 활용됩니다. 적절한 ARIMA 모델을 구성하기 위해 PACF를 이해하고 사용하는 것은 정확하고 신뢰성 있는 시계열 예측을 수행하는데 도움이 됩니다. 또한, PACF를 통해 데이터의 의존성을 파악함으로써 더 나은 데이터 분석과 결정을 할 수 있습니다.
PACF와 AR, MA 모델
PACF는 자기회귀 모델(AR 모델)과 이동평균 모델(MA 모델)의 차수를 결정하는데 사용됩니다. PACF를 통해 시차(lag)가 어느 정도까지 유의미한 영향을 미치는지 파악하면, 적절한 AR, MA 모델의 차수를 결정할 수 있습니다.
PACF와 ARIMA 모델
ARIMA(AutoRegressive Integrated Moving Average) 모델은 AR 모델과 MA 모델을 결합한 모델로, PACF를 통해 ARIMA 모델의 차수(p, d, q)를 결정하는데 사용됩니다. 여기서 p는 AR 모델의 차수, d는 차분(differencing)의 차수, q는 MA 모델의 차수를 의미합니다.
데이터의 의존성 탐지
PACF는 시계열 데이터 내에 어떤 시차(lag)까지 데이터가 상관관계를 가지는지 파악하는데 사용됩니다. 데이터의 시차 간 의존성을 파악하면 데이터의 특성을 더 잘 이해하고 예측 모델을 개선할 수 있습니다.
7. autocorrelation handling
차분(Differencing):
자기상관을 줄이는 가장 일반적인 방법은 차분을 수행하는 것입니다. 차분은 현재 값과 이전 값과의 차이를 구하는 것을 말합니다. 이를 통해 시계열 데이터의 추세나 계절성을 제거하고 정상성을 만족시킬 수 있습니다. 1차 차분을 수행하는 경우는 시계열 데이터가 비정상(non-stationary)인 경우에 많이 사용됩니다.
모델링 (ARIMA 등):
자기상관을 고려하여 적절한 시계열 모델을 사용하는 것도 자기상관을 처리하는 방법 중 하나입니다. ARIMA(AutoRegressive Integrated Moving Average) 모델은 자기상관과 이동평균 구조를 모두 고려하는 모델로, 정상성을 만족시키기 위해 차분을 수행하는 방법을 포함하고 있습니다.
계절성 처리
시계열 데이터에 계절성 패턴이 있는 경우에는 계절성을 고려하여 자기상관을 처리해야 합니다. 계절성을 고려하는 모델이나 계절적인 차분을 통해 자기상관을 다룰 수 있습니다.
자기상관 제거 방법 적용
특정 자기상관 구조를 갖는 데이터에 대해 자기상관을 제거하는 방법도 있습니다. 예를 들어, 부분 자기상관 함수(PACF)를 사용하여 자기상관을 상쇄시키는데 활용할 수 있습니다.
로버스트 방법 활용
자기상관이 있는 데이터의 경우 일반적인 통계 분석 기법들이 유효하지 않을 수 있습니다. 이런 경우 로버스트 통계 분석 기법을 활용하여 더 신뢰성 높은 결과를 얻을 수 있습니다.

잘 읽었습니다. 좋은 정보 감사드립니다.