Notation
this section provides a concise reference describing the notation used throughout this book.
if you are unfamiliar with any of the corresponding mathematical concepts, we describe most of these ideas in chapters 2-4.
Numbers and Arrays
A scalar (integer or real)
A Vector
A matrix
A tensor
Identity matrix with n rows and n columns
Standard basis vector [0, . . . ,0,1,0, . . . ,0] with a 1 at position i
a square, diagonal matrix with diagonal entries given by 'a'
Sets and Graphs
'A' set
The set of real numbers
{0,1}
The set containing 0 and 1
{0,1.....,n}
The set of all integers between 0 and n
The real interval including a and b
The real interval excluding a but including b
Set subtraction, i.e., the set containing the elements of A that are not in B
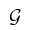
A graph
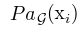
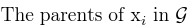
Indexing
Elements i of vector 'a' , with indexing starting at 1
All elements of vector 'a' except for element i
Elements i,j of matrix A
Row i of matrix A
Column i of matrix A
Elements (i,j,k) of a 3-D tensor A
Linear Algebra operations
Transpose of matrix A
Moore-Penrose pseudoinverse of A
Element-wise (Hadamard) product of A and B
Determinant of A
Calculus
Derivative of y with respect to x
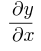
Partial derivative of y with respect to x
Gradient of y with respect to x
Matrix derivatives of y with respect to X
Tensor containing derivatives of y with respect to X
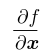
Jacobian matrix
define integral over the entire domain of x
Definite integral with respect to x over the set S
Probability and Information Theory
The random variables a and b are independent
They are conditionally independent given c\
a probability distribution over a discrete variable
A probability distribution over a continuous variable, or over a variable whose type has not been specified
Random variable a has distribution P
Expectation of f(x) with respect to P(x)
Variance of f(x) under P(x)
Covariance of f(x) and g(x) under P(x)
Shannon entropy of the random variable x
Kullback-Leibler divergence of P and Q
Gaussian distribution over x with mean µ and covariance Σ
Function
The function f with domain A and range B
Composition of the functions f and g
A function of x parametrized by theta, (Sometimes we write f(x) and omit the argument theta to lighten notation)
Natural logarithm of x
Logistic sigmoid,
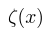
Softplus, log(1_exp(x))
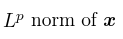
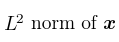
Positive part of x , i.e., max(0,x)
is 1 if the condition is true, 0 otherwise
Datasets and Distributions
The data generating distribution
The empirical distribution defined by the training set
A set of training examples
The i-th example (input) from a dataset
The target associated with x^{i} for supervised learning
The m x n matrix with input example x^{i} in row Xi:
