- MS, Google, Apple, Amazon비교
- LLM (바트, GPT)

1. Keras.datasets
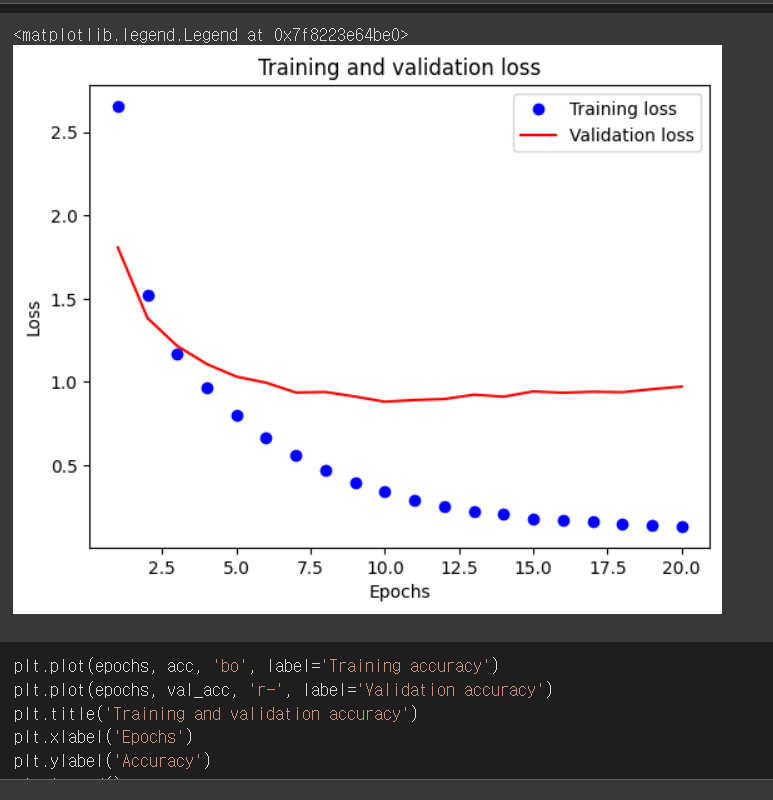
1) Training loss
2) Validation loss
https://www.baeldung.com/cs/training-validation-loss-deep-learning
학습 (training), 검증 손실 (validation loss)은 머신러닝 모델을 학습시키고 평가하는 데 사용되는 개념.
학습 (training) :
학습은 머신러닝 모델이 데이터를 이용하여 예측이나 분류를 수행하는 방법을 배우는 과정. 이 과정에서 모델은 학습 데이터셋(training dataset)을 사용하여 가중치와 편향 같은 모델 매개변수를 조정. 학습의 목표는 모델이 일반화된 예측을 수행할 수 있도록 가장 적합한 매개변수 값을 찾는 것.
검증 손실 (validation loss) :
검증 손실은 모델의 성능을 측정하는 지표. 학습 중에는 검증 데이터셋(validation dataset)을 사용하여 모델의 예측 결과와 실제 레이블 사이의 오차를 계산. 검증 손실은 모델의 일반화 성능을 추정하고, 과적합(overfitting) 여부를 판단하는 데 도움.
공통점:
둘 다 머신러닝 모델을 학습시키고 평가하는 데 사용되는 개념.
둘 다 모델의 성능을 향상시키기 위해 사용.
차이점:
학습은 모델이 데이터에서 패턴을 학습하고 매개변수를 최적화하는 과정. 반면 검증 손실은 모델의 성능을 평가하는 데 사용되는 지표.
학습은 학습 데이터셋을 사용하여 진행되며, 검증 손실은 검증 데이터셋을 사용하여 계산. 이를 통해 모델이 새로운 데이터에 대한 예측 능력을 평가.
학습은 모델의 매개변수를 최적화하는 데 직접적으로 영향을 미치지만, 검증 손실은 모델의 일반화 성능을 추정하고 과적합 여부를 판단하는 데 사용되는 간접적인 척도.
- 값이 일정해지는 순간부터.
2. 데이터 전처리
https://modulabs.co.kr/blog/data-preproccesing/
데이터 전처리(Data Preprocessing)는 원시 데이터(Raw Data)를 분석이나 학습에 적합한 형태로 변환하는 과정. 데이터 전처리는 머신러닝(Machine Learning) 및 데이터 분석(Data Analysis)에서 중요한 단계로, 효과적인 결과를 도출하기 위해 사용.
1) 결측치 처리(Handling Missing Data):
데이터에서 결측값(Missing Values)을 대체, 제거, 보간 등의 방법으로 처리합니다.
2) 이상치 탐지(Outlier Detection):
데이터에서 통계적으로 이상한 값을 찾아내고 처리하는 과정입니다.
3) 데이터 정제(Data Cleaning):
노이즈(Noise)를 제거하고 데이터의 일관성(Consistency)을 높이는 작업입니다.
4) 데이터 통합(Data Integration):
여러 출처에서 얻은 데이터를 하나의 저장소에 합치는 과정입니다.
5) 피처 스케일링(Feature Scaling):
변수(Features)의 범위를 조정하여 모델의 성능을 높입니다. 정규화(Normalization)와 표준화(Standardization)가 대표적인 방법입니다.
6) 데이터 분할(Data Splitting):
데이터를 학습용(Training Set), 검증용(Validation Set), 테스트용(Test Set)으로 나누는 과정입니다.
7) 피처 추출(Feature Extraction):
데이터에서 중요한 변수(Features)를 추출하고 생성하는 작업입니다.
8) 범주형 데이터 처리(Categorical Data Handling):
숫자로 표현되지 않은 범주형 데이터(Categorical Data)를 숫자로 변환하는 작업입니다.
9) 원-핫 인코딩(One-hot Encoding)과 레이블 인코딩(Label Encoding)이 대표적.
이러한 과정을 거치면 데이터는 분석이나 머신러닝 알고리즘에 적합한 형태로 전처리.
3. 표준편차 (std)
표준 편차 (標準 偏差, 영어: standard deviation ,SD)는 자료의 산포도 를 나타내는 수치로, 분산 의 양의 제곱근으로 정의된다. 표준편차가 작을수록 평균값에서 변량들의 거리가 가깝다. 통계학과 확률 에서 주로 확률의 분포, 확률변수 혹은 측정된 인구나 중복집합에 적용.
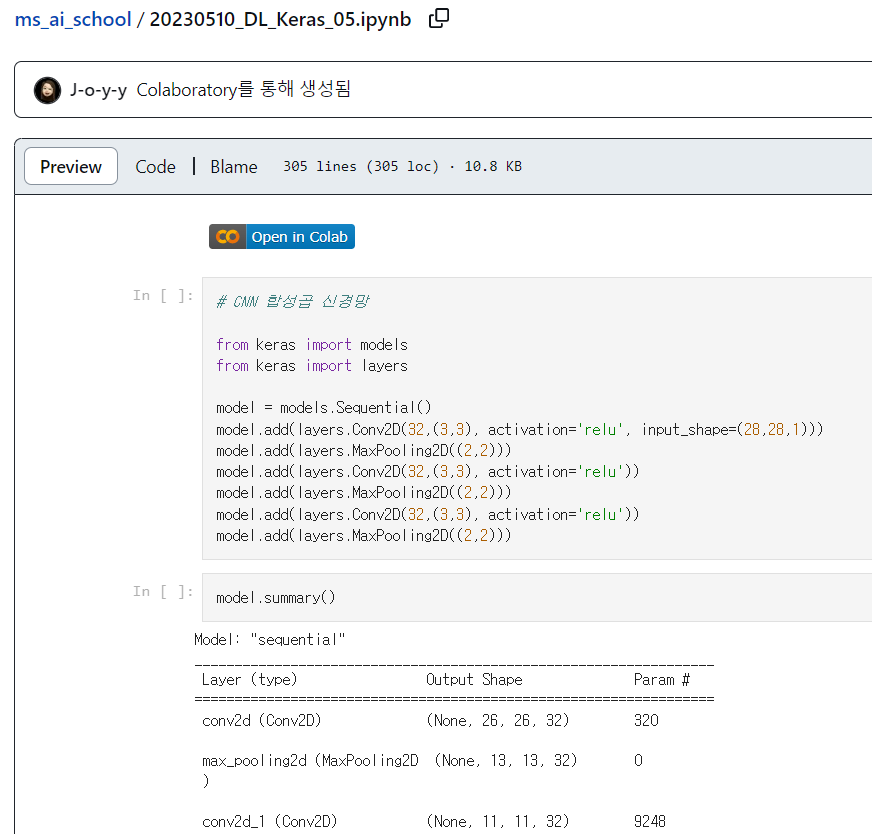
4. 신경망
5. DL
