CS 기본 지식
1. 프로세스와 스레드 차이 (운영체제)
-
프로세스 : 운영체제로부터 자원을 할당받아 실행
-
스레드 : 프로세스로부터 자원을 할당받아 실행
-
하나의 프로세스 안에 여러 스레드 생성 가능
-
각 스레드는 개별 스택을 가지고, 프로세스의 전역 메모리 공간을 공유하며 프로그램을 실행
- 보통 프로세스는 코드/데이터/스택/힙/ 메모리 영역을 기반으로 실행- 스레드는 프로세스 안에서 개별적인 스택을 가지로 코드/데이터/힙 영역을 공유하며 실행
2. 스크립트 언어와 컴파일러 언어의 차이
-
인터프리터 언어 : 코드가 실행되는 단계인 런타임에 문 단위 한 줄씩 중간 코드인 바이트코드로 변환한 후 실행
- 인터프리트 과정이 반복 수행- 인터프리트 단계와 실행 단계가 분리되어있지 않다
- 한 줄씩 바이트코드로 변환하고 즉시 실행한다.
- 실행 파일을 생성하지 않는다
-
컴파일러 언어 : 코드가 실행되기 전 단계인 컴파일 타임에 소스코드 전체를 한번에 머신 코드로 변환후 실행
- 실행 파일을 생성한다.- 최적화 작업을 진행하고 실행파일을 생성하기때문에 코드 실행 속도가 인터프리터보다 빠르다
- 실행에 아펏 컴파일은 단 한번만 수행된다.
-
자바스크립트는 일반적으로 인터프리터 언어로 구분하지만, 인터프리터와 컴파일러의 장점을 결합해 비교적 처리 속도가 느린 인터프리터의 단점을 해결했다.
-
파이썬도 인터프리터 언어
3. 동기와 비동기의 장단점
- 동기 : 구성이 단순하고 순서대로 실행가능해서 예측이 가능하다.
- 비동기 : 동시에 여러일을 수행할 수 있음.
4. 데이터베이스에서 인덱스를 사용하는 이유와 장단점
- 인덱스는 데이터를 논리적으로 정렬해서 검색과 정렬 속도를 높이기 위해 사용
- 데이터 삽입, 변경이 수시로 일어나면 매번 인덱스를 변경해야하므로 성능 저하를 막기 위한 고려가 필요하다.
- 그래서 리액트에서 key는 인덱스로 지정하면 안되는 경우가 더 많다. (주로 유일한 값을 key에 지정해줌) -> 인덱스는 변화가 발생할 경우가 많기 때문에
5. Redis와 MongoDB 차이
- 둘다 No SQL 방식 사용
- 몽고 DB가 document 형식으로 데이터를 저장하는데 반해, Redis는 key:value 형식으로 데이터를 저장함
- Redis는 인메모리DB로 데이터를 메모리에 저장하고 관리하기 때문에 성능이 좋지만, 데이터를 유한하게 저장하기때문에 키쉬등과 같이 데이터의 저장기한이 있고, 빠른 성능이 필요한 기능에 사용됨.
- 몽고 DB는 mysql처럼 서버-클라이언트 방식으로 설치해서 사용.
- MySQL과 같은 SQL 방식이 아니므로 가변적 데이터 구조를 다루는데 유용하다.
TCP, UDP 차이와 장단점
-
UDP : 비연결형 프로토콜로 흐름제어, 오류제어를 하지 않음
-
TCP : 연결형 프로토콜로 흐름제어, 오류제어를 함
-
UDP는 TCP처럼 종단간 연결설정 및 오류제어를 하지않아 송수신에 적은 데이터를 필요
-
TCP는 UDP보다 데이터 송수신에 신뢰성을 가짐
오버라이딩 vs 오버로딩
- 오버라이딩 : 상위클래스에 존재하는 메서드를 하위 클래스에 맞게 재정의하는 것
*** 메서드 이름 및 파라미터수가 동일 - 오버로딩 : 두 메서드가 같은 이름을 가지고 있으나 파라미터 수나 자료형이 다른 경우
interface vs abstract
- abstract :
- 추상 클래스는 추상 메서드를 1개 이상 가지고 있는 클래스를 의미
- interface :
- 상수와 메서드 선언 집합- 정의된 메서드를 extends, implements 받은 곳에서 모두 구현을 강제함.
- 인터페이스는 인터페이스끼리 상속이 가능해 여러 인터페이스 상속이 가능
디자인패턴이란?
- 디자인 패턴은 공통적인 소프트웨어 코드 작성 문제를 해결하는데 도움이 될 수 있는 코드 패턴.
파이썬 제너레이터
- Generator은 Iterator를 생성해주는 함수로, 함수 안에 yield 키워드를 사용
- Iterator은 next() 메서드를 이용해 데이터를 순차적으로 접근할 수 있는 함수
- Generator은 한번에 모든 데이터를 메모리에 적재할 필요가없어 메모리 효율이 높고, 계산 결과가 필요할때까지 계산을 늦츨 수 있고, 수행 시간이 긴 연산을 필요한 순간까지 늦출 수 있다는 장점 가짐
객체와 클래스의 차이점
private, protected, public, default 키워드 차이
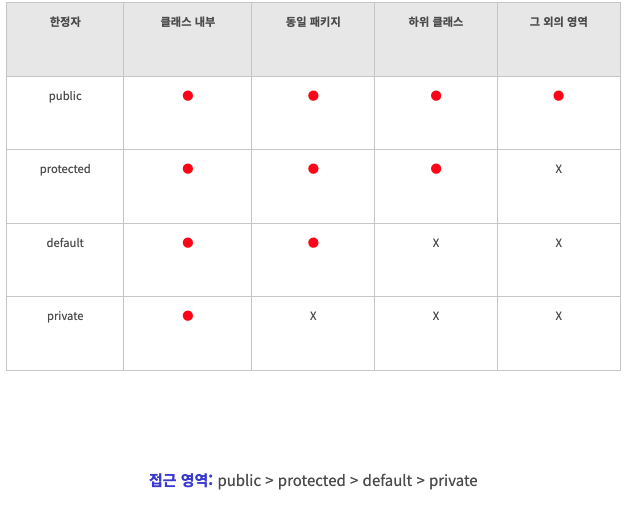
- 접근 지정자
public: 모든 접근 허용. 어떤 클래스가 접근하든 모두 허용
protected : 상속받은 클래스 또는 패키지에서만 접근 가능
default : 기본 제한자로서 아무것도 붙지 않고 자신 클래스 내부와 같은 패키지 내에서만 접근이 가능
private: 외부에서 접근 불가하고 같은 클래스 내에서만 접근 가능
객체 지향 5대 원칙
- 단일 책임 원칙
- 개방-폐쇠 원칙
- 리스코프 치환 원칙
- 인터페이스 분리 원칙
= 의존관계 역전 원칙
MVC 패턴 설명
- 코드가 복잡해지면 파악하기도 힘들어지고 유지보수가 힘들어짐.
- 코드에 대한 유지보수를 어떻게 하면 편하게 할 수 있을까에 대한 고민에 생겨나게된 패턴
Model : 값과 기능을 가지고 있어 비지니스 로직을 수행하게됨
View : html, css 사용자한테 보여지는 부분 (모든 사용자에게 똑같이 보여줘야하는 부분 -> 비지니스 로직 없음
Controller : model과 view를 연결하는 부분
- 모델은 컨트롤러와 뷰에 의존하지 않아야 한다
- 뷰는 모델에만 의존해야하고 컨트롤러에 의존하면 안된다
- 뷰가 모델로 부터 데이터를 받을때는 사용자마다 다르게 보어주어야 하는 데이터에 대해서만 받아야한다.
라이브러리 vs 프레임워크
라이브러리 = 가져다 쓰는거
프레임워크 = 기본 틀로 삼아서 그 위에 뭘 덧붙여 만드는 것
가상 메모리란?
- 컴퓨터에는 가상메모리와 램이 존재. 가상 메모리는 램 공간이 부족할때 윈도우에서 사용하는 파일임. 가상메모리를 사용한다는 것은 페이징 파일과 정보를 이동하여 충분한 램을 확보하여 높은 메모리를 요구하는 프로그램이 올바르게 실행되도록 하는 것.
컨텍스트 스위칭?
- 현재 진행하고 있는 태스크의 상태를 저장하고 다음 진행할 태스크의 상태 값을 읽어 적용하는 과정
Transaction 개념?
- 데이터베이스 상태를 변화시키기 위해 수행하는 작업의 단위
- 질의어(select, insert, update, delete)를 이용하여 데이터베이스를 접근 하는 것.
특징
1. 원자성 : 트랜잭션이 데이터베이스에 모두 반영되던가 아님 전혀 반영되지 않아야한다 (처음에 트랜잭션을 진행하기 위해 참조한 데이터베이스로 진행된다. -> 일관성있는데이터 볼 수 있음
2. 일관성 : 결과가 항상 일관적이어야 한다
3. 독립성 : 둘 이상의 트랜잭션이 동시해 실행되고있을경우 다른 트랜션의 연산에 끼어들 수 없음
4. 지속성 : 트랜잭션이 성공적으로 완료되었을 경우 결과는 영구적으로 반영되어야한다.
- commit : 하나의 트랜젝션이 성공적으로 끝났고 데이터베이스가 일관성있는 상태에 있을때
- rollback : 비정상적으로 트랜잭션 처리가 종료되어 원자성이 깨진경우 다시 시작하거나 부분적으로 취소 시키는것.
관계형 데이터베이스 시스템과 NoSQL의 차이점
mySQL = 관계형 데이터베이스
- 데이터 구조가 엄격, 데이터 형태가 정해져있음.
mongo db = document db
니가 원하는 어떤 종류의 어떤 모양의 데이터든 저장 가능
- strict하지도 않음
cassandra = no sql
- 상당히 빠름 + 상당히 많은 양을 저장해야할때
자료구조 & 알고리즘
해쉬 테이블
- key: value로 저장하는 데이터 구조
- 키를 통해 바로 데이터를 받아올 수 있어 속도가 획기적으로 빨라짐
- 해쉬 : 임의 값을 고정 길이로 변환하는것
- 해쉬 테이블 : 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 해쉬 함수 : 키에 대해 산술 연산을 이용해 데이터 위치를 찾을 수 있는 함수
- 해쉬 값 / 해쉬 주소 : 키를 해싱 함수로 연산해서 해쉬 값을 알아내고 이를 기반으로 해뷔 테이블에서 해당 키에 대한 데이터 위치를 일관성있게 찾을 수 잇음
- 슬롯 : 한 개의 데이터를 저장할 수 있는 공간
- 저장할 데이터에 대해 키를 추출할 수 있는 별도 함수도 존재할 수 있음
힙
- 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리
- 완전 이진 트리 : 노드를 삽임할 때 최하단 왼쪽 노드부터 차례대로 삽입하는 트리
= 최대값과 최소값을 찾으려면 O(log n)이 걸림 <=> 배열의 경우 O(n)
항상 루트노드를 가지고 오기때문에 다른 값을 찾아볼 필요가 없음
= 우선순위 큐와 같이 최대값 또는 최소값을 빠르게 찾아야하는 경우 많이 사용 - 각 노드의 값은 해당 노드의 자식 노드가 가진 값보다 크거나 같다.
힙과 이진 탐색 트리의 차이
공통점 : 힙과 이진 탐색 트리는 모두 이진 트리
차이점
- 이진 탐색 트리 : 왼쪽자식노드부터 하나씩 채워나간다. (왼쪽 자식 노드의 값이 가장 작고, 그 다음 부모 노드, 그 다음 오른쪽 자식 노드 값이 가장 큼)
- 힙 : 각 노드의 값이 자식 노드보다 크거나 같음
- 힙 : 왼쪽 자식 노드 or 오른쪽 자식 노드 어느 쪽이 더 큰지 모름 - 이진 탐색 트리 : 탐색을 위한 구조
- 힙 : 최대/최소값 검색을 위한 구조
버블 정렬
- 인접한 데이터를 비교해서 앞에 있는 데이터보다 작은경우 바꾸어줌
- 반복문이 두개인경우 O(n^2), 최악의 경우 n*(n-1)/2
- 완전 정렬이 되어있는 경우 최선은 O(n)
- 데이터의 길이 : n (n만큼 반복을 2번함)
삽입 정렬
- 두번째 인덱스부터 시작
- 해당 인덱스 앞에 있는 데이터부터 비교해서 key값이 더 작으면 B값을 뒤 인덱스로 복사
- 이를 키 값이 더 큰 데이터를 만날때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key값을 이동
- 반복문이 두 개 O(n^2)
- 최악인 경우 n*(n-1)/2
- 완전 정렬인 경우 O(n)
선택 정렬
- w주어진 데이터 중 최소값을 찾음
- 해당 최소값을 데이터 맨 앞에 위치한 값과 교체
- 맨 앞의 위치를 뺀 나머지 데이터를 동일한 방법으로 반복
- 반복문이 두 개 O(n^2)
- 최악인 경우 n*(n-1)/2
