삽입 정렬 알고리즘
-
선택 정렬 알고리즘이 정렬되지 않은 데이터 중에 가장 작은 값을 찾아 정렬하는 방식이라면
삽입 정렬 알고리즘은 그러한 작은 값을 찾는 검색 과정이 필요 없는 정렬 알고리즘
-
순차적으로 정렬하면서 현재의 값을 정렬되어 있는 값들과 비교하여 위치로 삽입하는 방식

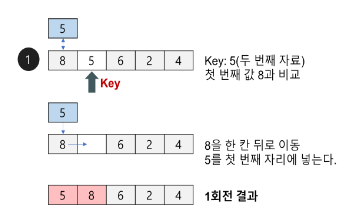
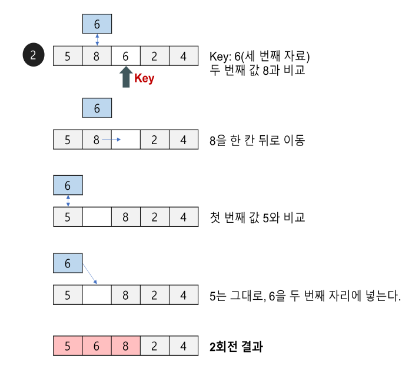
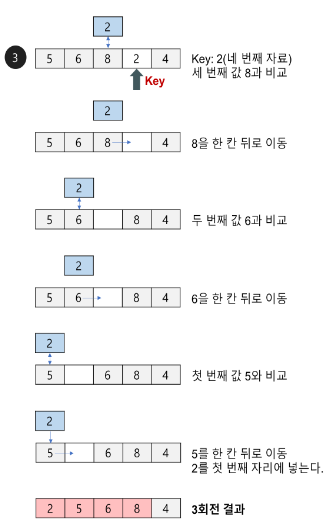
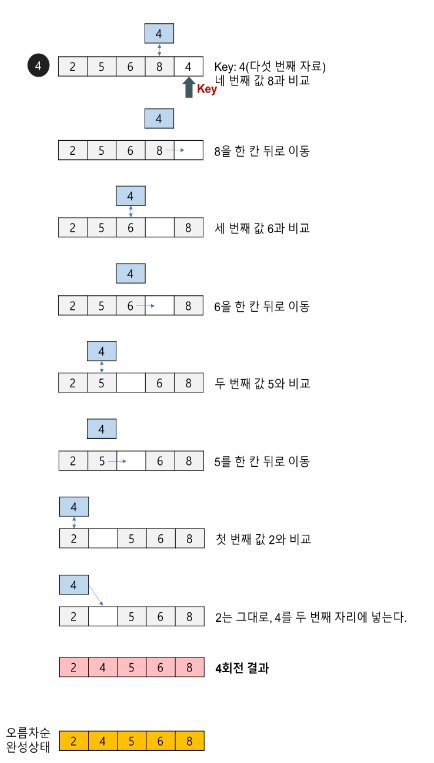
삽입 정렬 알고리즘의 구현
import random
import time
compare_counter = 0
swap_counter = 0
def insertion_sort(my_list):
global compare_counter, swap_counter
my_list.insert(0, -1)
for s_idx in range(2 , len(my_list)):
temp = my_list[s_idx]
ins_idx = s_idx
compare_counter += 1
while my_list[ins_idx-1] > temp:
swap_counter += 1
my_list[ins_idx] = my_list[ins_idx -1]
ins_idx = ins_idx - 1
my_list[ins_idx] = temp
print("----")
print(my_list[1:])
print("----")
del my_list[0]
if __name__ == "__main__":
list = []
input_n = input('정렬할 데이터의 수: ')
for i in range(int(input_n)):
list.append(random.randint(1, int(input_n)))
print("< 정렬 전 >")
print(list)
start_time = time.time()
insertion_sort(list)
running_time = time.time() - start_time
print("< 정렬후 >")
print(list)
print(f"데이터의 크기 : {int(input_n)}")
print(f"비교 횟수 : {compare_counter}")
print(f"교환 횟수 : {swap_counter}")
print(f"실행 시간 : {running_time}")삽입 정렬 알고리즘의 실행과 성능
-
삽입 정렬 알고리즘의 경우 이미 정렬 된 데이터,
즉 최선의 경우에는 선택 정렬 알고리즘에 비해 월등히 좋은 성능을 보여줌 -
데이터의 비교 횟수가 입력 데이터의 양에 비례하기 때문
-
선택 정렬 알고리즘의 경우는 N * (N-1) /2 에 가까운 수가 됨
-
정렬할 데이터의 수가 많으면 많을 수록
선택 정렬 알고리즘에 비해 삽입 정렬 알고리즘의 성능이 좋아진다는 것을 의미 -
최악의 경우는 상황이 다름
선택 정렬 보다 삽입 정렬의 성능이 더 안좋다는 것을 알 수 있음 -
삽입 정렬 알고리즘의 경우에는 최악의 경우 비교 횟수도 N (N-1) /2 가 되고,
데이터의 이동 횟수도 N (N-1) /2 가 됨 -
선택 정렬 알고리즘에서 데이터 이동횟수가 N인것에 비해 성능을 감소시키는 요인이 됨
-
따라서 삽입 정렬 알고리즘의 선능을 O 표기법으로 표시하면 O(N^2)이 됨
-
선택 정렬 알고리즘도 동일하기 때문에 두 알고리즘의 선능은 그다지 차이가 없다고 볼 수 있음
시간의 효율성
- O(N^2)의 실행 시간
- 정렬이 어느 정도 되어 있는 경우, N에 가까운 성능
공간의 효율성
- 데이터의 크기가 큰 경우에는 데이터 교환 횟수가 상대적으로 많기 때문에
그다지 바람직한 정렬 방식은 아님 - 하나 당 데이터의 크기가 큰 경우에도 인덱스를 사용하는 간접 정렬 방식을 사용하면
삽입 정렬의 단점 중에 하나인 공간의 효율성이 떨어지는 단점을 해결할 수 있음
코드의 효율성
- 코드 복잡도는 반복문을 2번 사용하여 O(N^2)의 성능이 되므로
그다지 좋은 알고리즘이라고 보기 어려움

learn !