🌱 0. 서론 - 로그 마이그레이션 아키텍쳐 구축 및 설계의 의의
🔧 ECS 환경에서 로깅을 어떻게 야무지게 할 것인가?
지난 포스팅 (궁금하면 클릭)에서 ECS 환경에서 컨테이너 로깅을 어떻게 야무지게 할것인지에 대해 이야기 했다.
간략하게 요약하면 실시간 로깅은 AWS Session Manager 를 통해, CloudWatch 로그는 Utern 이라는 서드파티 툴을 사용했다.
그.렇.다.면
모든 로그를 CloudWatch Log Group 에 저장하면 되는것 아닌가?
💸 CloudWatch 에 모든 로그를 적재하면 넘나 비싸요
CloudWatch 로그 그룹으로 ECS 클러스터의 로그를 전달 받고 계속 저장하면 비용이 어마어마하게 불어난다.
서비스를 운영하면 기하급수적으로 늘어나는 로그를 CloudWatch 에 계속 저장하고 관리하게 된다면 그 비용은 감당하기 어려워진다.
AWS 서비스중 데이터를 저장하는 서비스라고 떠오르면 무엇이 가장 먼저 생각 나는가?
우리에겐 S3 가 있다! 🪣
외쳐 갓 S3!
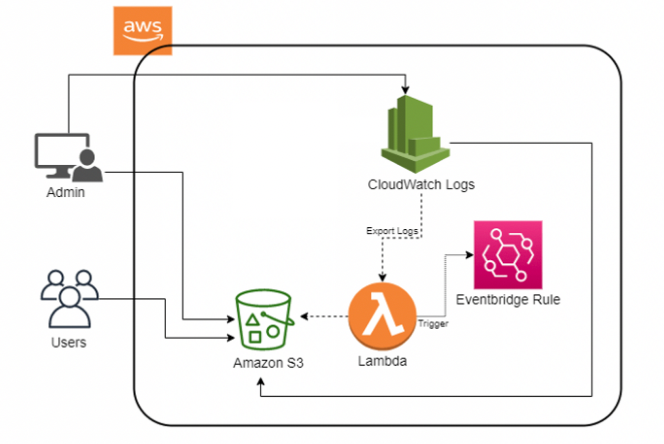
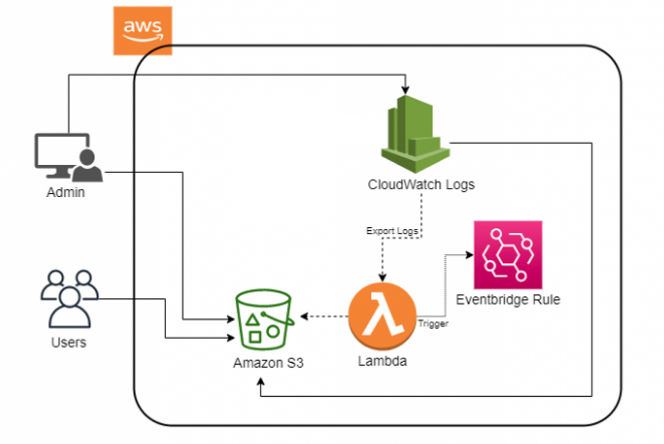
💻 구현할 아키텍쳐
-
일정 기간의 로그만을 CloudWatch 에 저장 하고 기간이 지나면 CloudWatch 에 더 이상 저장하지 않고 삭제한다.
-
기간이 지난 로그는
S3로 이관시켜서 보관한다. -
CloudWatch Log 는
AWS Lambda를 통해S3로 이관되며Eventbridge를 통해 일정시간마다 자동으로 작동하도록 구성한다. -
CloudWatch EventBridge 의 cron 설정을 통해
AWS Lambda가 트리깅되어 작동한다.
아키텍쳐 구현 상세
- 해당 아키텍쳐를 구현하는 순서는 다음과 같다.
- S3 Bucket 생성
- Lambda 에 부여할 IAM Role 생성
- AWS Lambda Function 구축
- CloudWatch Events Rules 생성
🍎 1. S3 Bucket 생성
S3 Bucket Policy
S3 Bucket 의 정책은 다음과 같이 설정해준다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PublicReadForGetBucketObjects",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetObject",
"s3:GetObjectAcl",
"s3:GetObjectVersion",
"s3:ListMultipartUploadParts",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::{생성한 s3 버킷 이름}/*"
},
{
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:ListBucket",
"s3:GetBucketAcl",
"s3:ListBucketMultipartUploads"
],
"Resource": "arn:aws:s3:::{생성한 s3 버킷 이름}"
}
]
}- 위와 같은 정책으로 S3 버킷을 생성한다.
🍉 2. IAM Role 생성
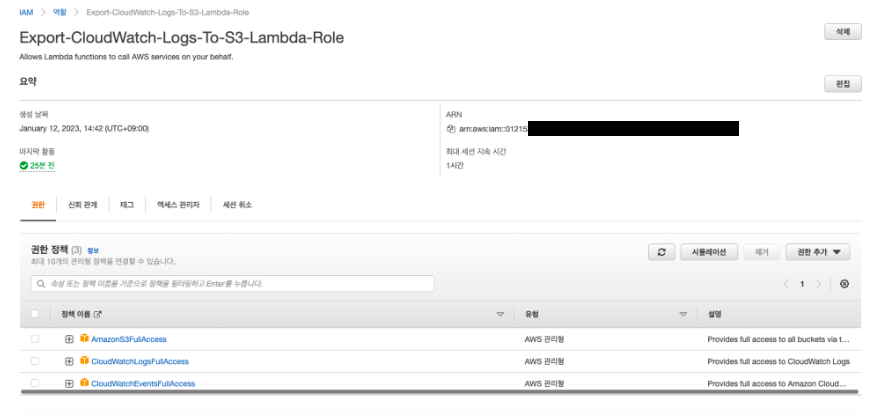
Lambda Function 에게 부여할 Role 추가
-
IAM 의
[역할]탭에서Role을 추가한다. -
생성된
Role은Lambda Function을 생성할 때 부여할 것이므로Lambda Function생성 전에 미리 추가한다. -
S3, CloudWatchLog, CloudWatchEvent에 접근할 수 있는 정책을 해당 역할에 부여한다.
해당 Role 에 부여한 Policy 이름
- AmazonS3FullAccess
- CloudWatchLogsFullAccess
- CloudWatchEventsFullAccess
🥝 3. AWS Lambda Function 구축
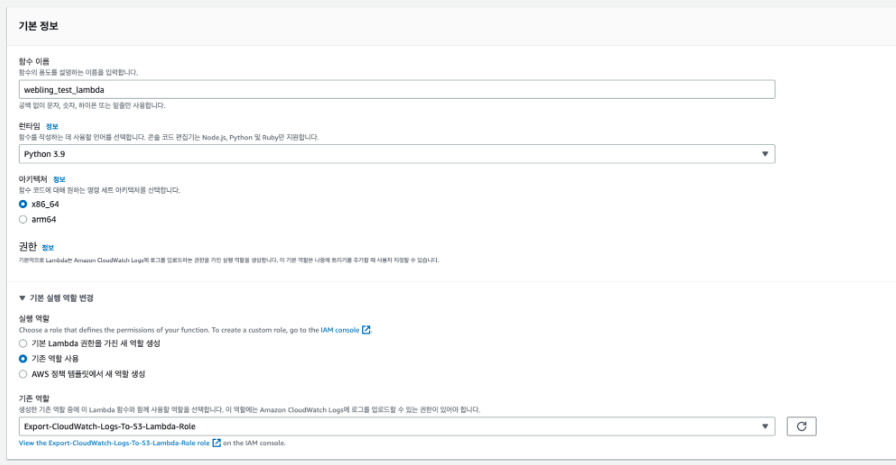
Lambda Function 생성
-
위와 같이
Lambda Function을 생성한다. -
런타임은 함수를 작성하는 데 사용하는 언어를 의미한다.
나는Python으로 선택했는데, 이유는Python의 라이브러리 (boto3등) 를 통해 AWS 서비스에 접근하기 편하기 때문이다. -
실행 역할은기존 역할 사용을 선택해주고 위에서 생성한Role을 선택해준다.
Lambda Function 구현
아래와 같이 Lambda Function 을 Python 으로 구현한다.
import boto3
import os
import datetime
GROUP_NAME = os.environ['GROUP_NAME']
DESTINATION_BUCKET = os.environ['DESTINATION_BUCKET']
PREFIX = os.environ['PREFIX']
NDAYS = os.environ['NDAYS']
nDays = int(NDAYS)
currentTime = datetime.datetime.now()
StartDate = currentTime - datetime.timedelta(days=nDays)
EndDate = currentTime - datetime.timedelta(days=nDays - 1)
fromDate = int(StartDate.timestamp() * 1000)
toDate = int(EndDate.timestamp() * 1000)
BUCKET_PREFIX = os.path.join(PREFIX, StartDate.strftime('%Y{0}%m{0}%d').format(os.path.sep))
def lambda_handler(event, context):
client = boto3.client('logs')
client.create_export_task(
logGroupName=GROUP_NAME,
fromTime=fromDate,
to=toDate,
destination=DESTINATION_BUCKET,
destinationPrefix=BUCKET_PREFIX
)os.environ[xxx]은Lambda환경 변수 설정에서 정의한 환경 변수를 가져온다는 것을 의미한다.
-GROUP_NAME:CloudWatch Log Group이름을 의미한다.DESTINATION_BUCKET: 저장할S3버켓의 이름을 의미한다.PREFIX:S3에 저장할 로그의 폴더 명을 지정한다.NDAYS: 며칠 전의 로그를 가져 올 것인지 지정한다.BUCKET_PREFIX:PREFIX와StartDate정보를 조합하여S3에 로그가 저장되는 경로를 만든다.
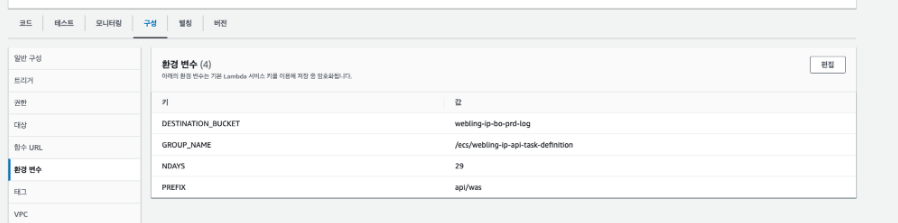
Lambda 환경 변수 설정
- Lambda Function AWS 콘솔 아래의
구성을 클릭하면 환경변수를 저장할 수 있다.- 위의 사진 처럼 key - value 형태로 저장한다.
🍒 4. CloudWatch Events Rules 생성
Lambda 를 실행하는 Trigger 를 발생시키기 위해 CloudWatch Events 를 생성
- AWS 콘솔 Amazon EventBridge -
[규칙]에서 생성한다.
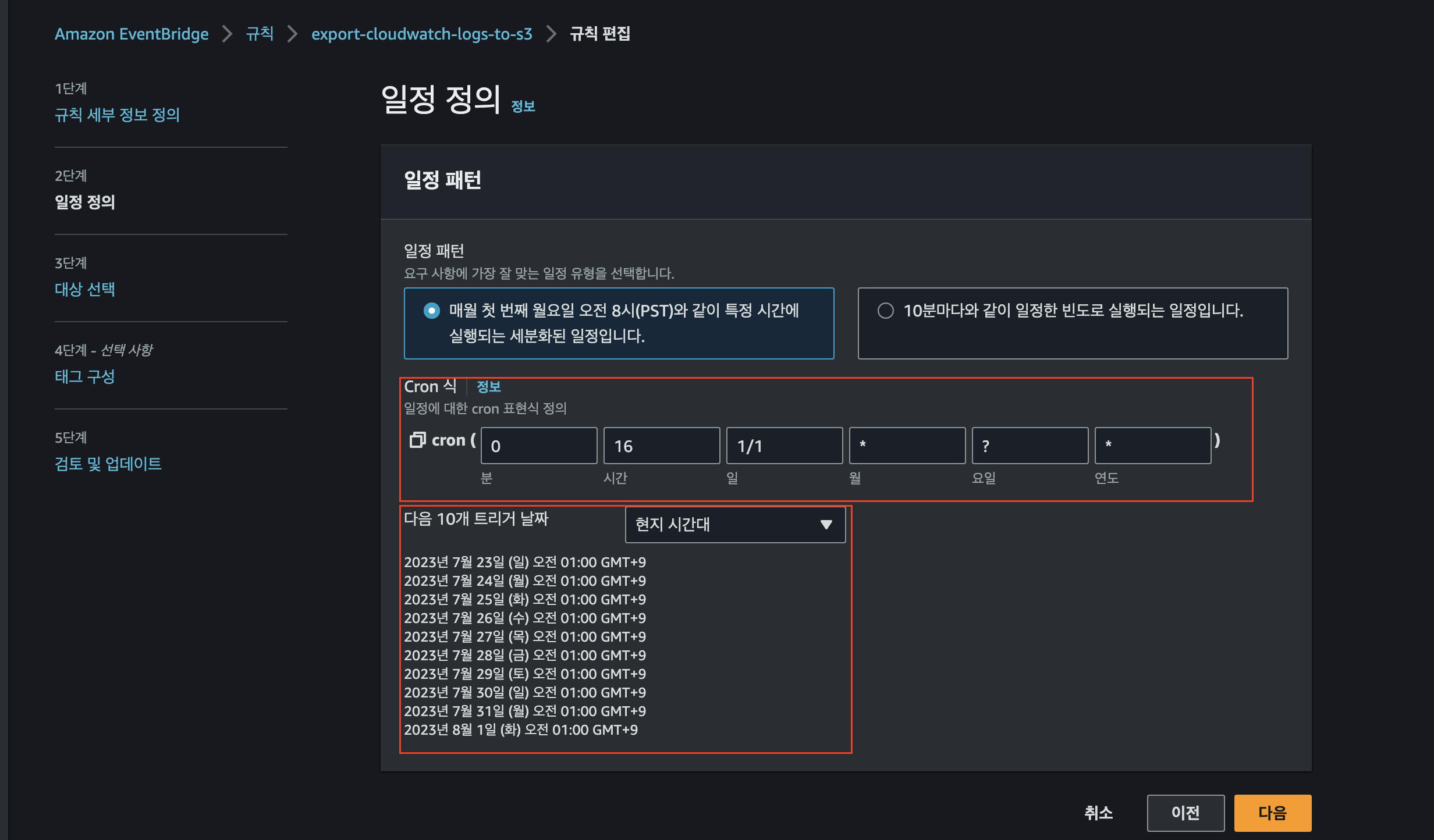
[일정 정의]: 이벤트를 어느 간격으로 수행할 지 정한다.
- Cron 표현식으로 작성하는 것을 권장한다.- 친절하게 AWS 콘솔에서 이벤트가 언제 발생되는지 보여준다. (다음 10개 트리거 날짜)

[대상]: 대상탭은 해당 이벤트가 발생할 때, 호출할 Lambda 함수를 선택하는 탭이다.
- 대상 선택에 Lambda 함수를 선택하고, 위에서 생성한 Lambda 함수를 선택한다.
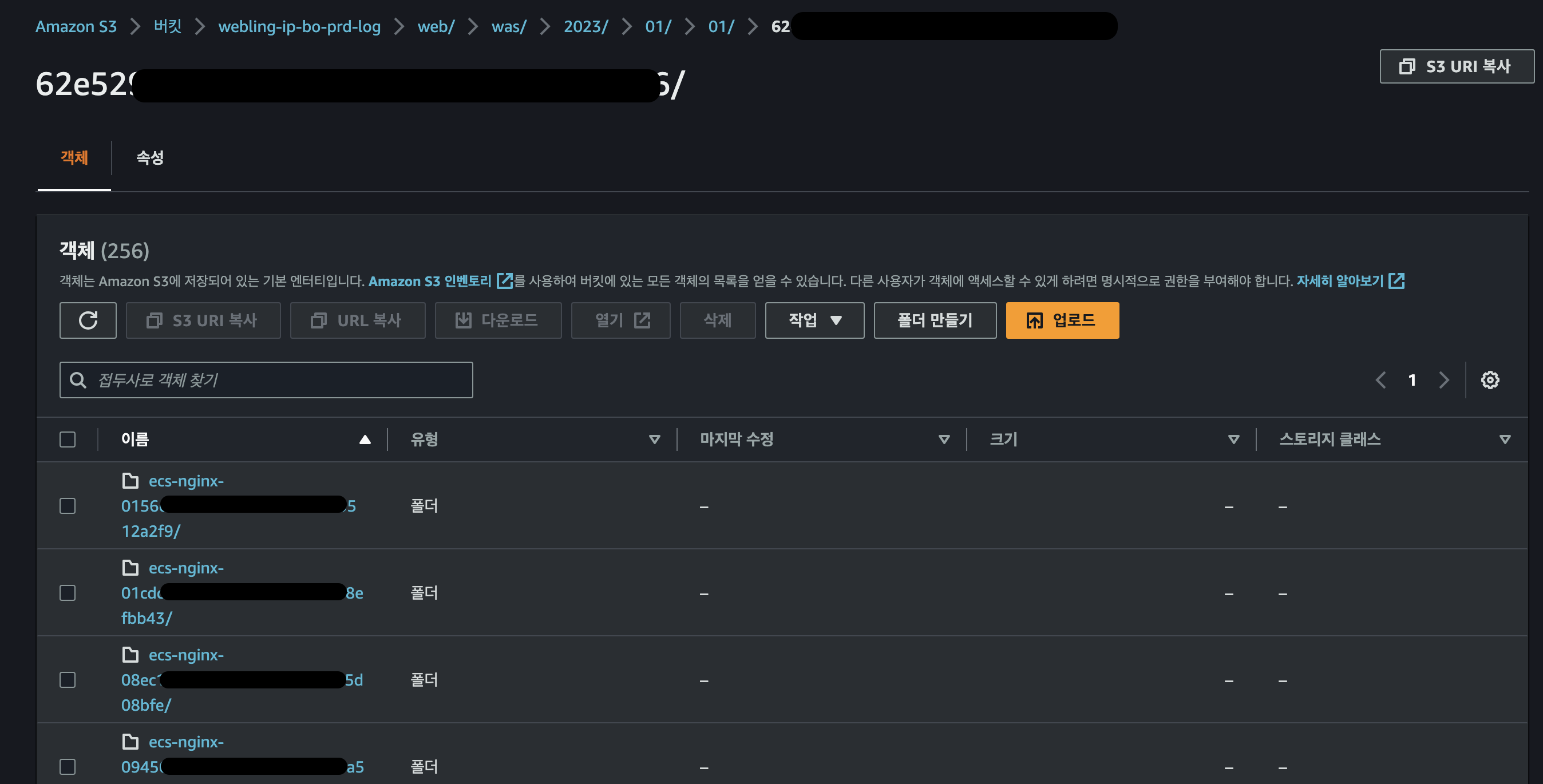
🍭 5. 완성된 Lambda Function 확인 및 S3 에 저장된 로그 확인
EventBridge 를 통해 작동하는 Lambda Function

S3 에 성공적으로 적재되고 있는 로그 폴더
🎉 6. 결론
ECS 환경에서 야무지게 로깅하기 에서 다뤘듯이, Lambda Function 을 이용하여 ECS 환경에서 컨테이너 로그들을 S3에 적재하는 것은 필수다.
그 이유는 첫째, Lambda Function 을 통한 자동화로 인해 로그 적재를 개발자가 신경 쓸 필요가 없어진다.
둘째, S3 에 이관함으로써 비용을 절감할 수 있다.
아무쪼록 이 글이 로그 적재 자동화를 구현하고자 하는 개발자 동료분들에게 도움이 되길 간절이 바래본다. 🙏🏻

6개의 댓글

정말 자세하게 소개해주셔서 잘 이해했습니다. 로그 적재 자동화를 구현하려고 하는데 많은 도움이 될 것 같아요. 좋은 정보 공유에 감사드립니다!

글 잘 읽었습니다. 실시간 로그는 세션 메니저, Cloud Watch 로그는 Utern 그럼 이제 S3에 쌓여 있는 로그는 어떻게 보시나요?

우와 너무 섹시하세요 ❤️ 부인은 참 좋겠어요