Stream API
자바 8 부터 Collection 사용이 급격하게 늘어나게 된 계기가 된 Stream 입니다.
Collection 자료구조(List, Queue)를 사용하면 데이터를 조작할 때 다양한 API를 사용할 수 있습니다.
Stream은 SQL 질의문과 비슷한 성격을 가지고 있습니다.
SQL 질의문의 경우에는 질의를 선언하기만 해도 구현이 가능하다는 점이 있습니다.
SELECT name FROM customer WHERE name = "와일더";반대로, 자바 8 이전의 버전에서는 이러한 필터링을 사용할 때도 구현을 한 뒤에 사용할 수 있었습니다.
이러한 불편함을 해소하기 위해 Stream이 고안됐습니다.
Stream을 사용하게 되면 기능을 구현하지 않고 선언형으로 컬렉션 데이터를 처리할 수 있습니다. 즉, 스트림을 사용하면 여러 줄로 작성하던 반복문과 조건문을 한 줄로 만들 수 있게 됩니다.
public List<Memeber> findAdultAsNAme(List<Memeber> members, int count){
return members.stream() // 멤버 리스트에서 스트림을 얻는다.
.filter(member -> member.isAdult()) // 멤버 리스트에서 성인인 사람만 가져온다
.limit(count) // 멤버 리스트에서 count 만큼의 사람만 가져온다
.map(Member::getName) // 그들의 이름으로 매핑한다
.collect(Collectors.toList()); // 리스트 자료구조로 만들어서 반환해준다이렇게 자바의 반복/조건문을 SQL 질의문처럼 가독성 좋게 작성이 가능해집니다.
스트림의 특징
-
람다식으로 요소 처리 코드를 제공한다.
스트림은 람다식을 이용하기 때문에 코드가 간결해진다는 장점이 있습니다. -
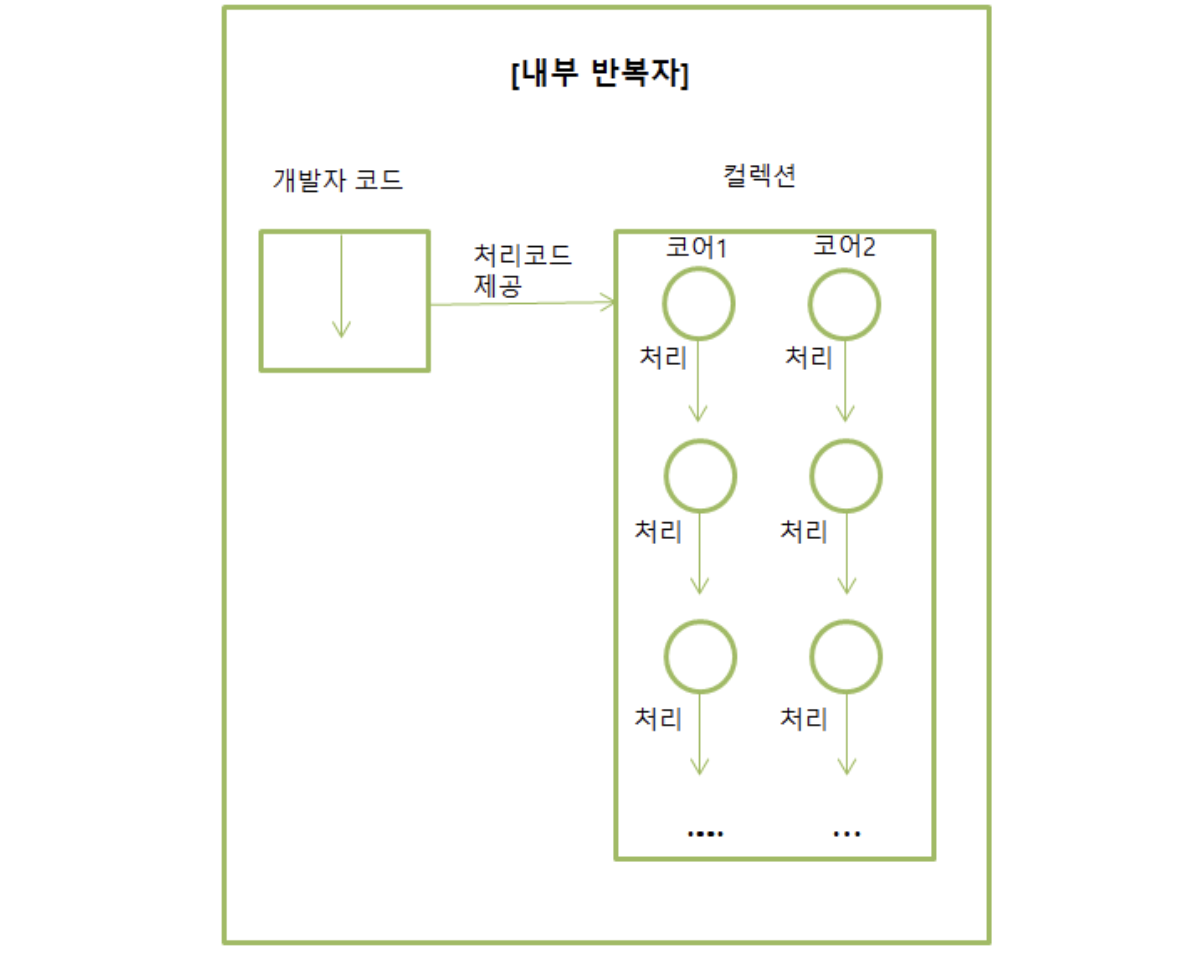
내부 반복자를 사용하므로 병렬 처리가 쉽습니다.
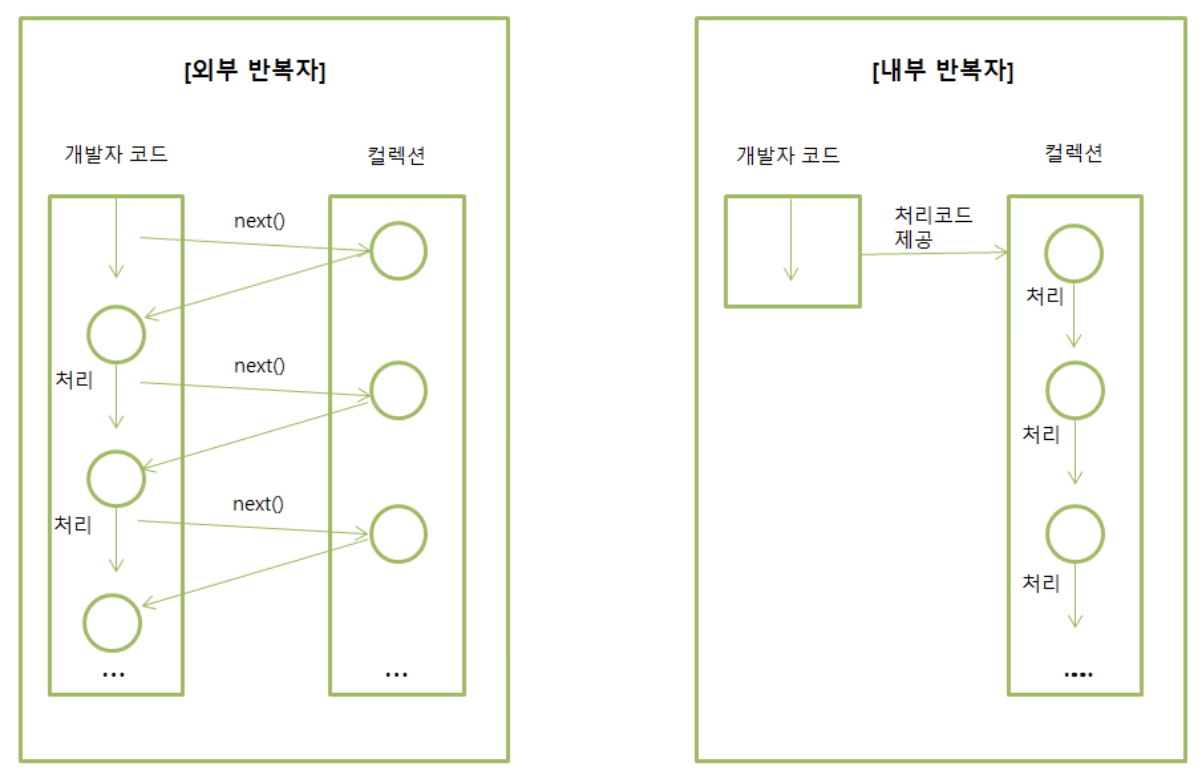
외부 반복자는 개발자가 코드로 직접 컬렉션의 요소를 반복해서 가져오는 패턴입니다.
for(int i = 0; i < length; i++){
}
while(iter.hasNext()){
}내부 반복자는 컬렉션 내부에서 요소들을 반복시키고 개발자는 요소당 처리해야할 코드만 제공하는 것입니다.
내부 반복자의 가장 큰 장점은 개발자가 반복에 신경쓸 필요없이 컬렉션에 맡길 수 있고 개발자는 처리 로직에만 집중할 수 있다는 점입니다.
이 내부 반복자로 인해 스트림은 병렬 처리가 가능하기 때문에 무조건적으로 좋아보입니다.
하지만 이 병렬 처리가 개발자들의 발목을 잡는 경우가 발생할 수 있습니다.
병렬 처리에서 발생할 수 있는 문제
병렬처리는 무조건 좋은게 아니야?
병렬 처리란 여러 개의 프로세서를 통해 하나의 프로그램을 처리하는 것입니다.
즉, 프로세서(CPU 코어)가 많으면 속도가 향상됩니다.
Collection 인터페이스의 parallelStream() 디폴트 메서드를 이용해 한 가지 작업을 서브 작업으로 나누고, 서브 작업들을 분리된 스레드에서 병렬적으로 처리하는 것이 가능합니다.
public class Main {
public static void main(String[] args){
List<String> list = List.of("사자","호랑이","기린","토끼","하마","얼룩말");
Stream<String> stream = list.stream();
stream.forEach(Main :: print);
System.out.println();
Stream<String> parallelStream = list.parallelStream();
parallelStream.forEach(Main :: print);
}
public static void print(String str){
System.out.println(str + " " + Thread.currentThread().getName());
}
}
사자 main
호랑이 main
기린 main
토끼 main
하마 main
얼룩말 main
토끼 main
얼룩말 main
하마 main
호랑이 ForkJoinPool.commonPool-worker-1
사자 main
기린 ForkJoinPool.commonPool-worker-3이렇게 여러 스레드가 작업에 참여했다는 것을 확인할 수 있습니다.
어 그러면 요즘 같은 멀티코어 환경에서 병렬처리는 무조건 좋아 보이는데 뭐가 문제라는 거지라는 의문이 발생할 수 있습니다.
Thread Safe 한가?
가장 큰 문제점은 Thread-Safe 여부입니다.
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
numbers.add(i);
}
List<Integer> evenNumbers = new ArrayList<>();
numbers.parallelStream().filter(number -> number % 2 == 0).forEach(evenNumbers::add);
System.out.println(evenNumbers.size());
5번 실행한 결과
42132
48836
50000
46267
47565원래대로라면 50000이 결과로 나와야 하지만 5번을 실행하는 동안 5개의 결과가 모두 다릅니다.
이런 결과가 나오는 이유는 동시성을 제어하지 못하기 때문입니다.
즉, List에 여러 Thread 들이 접근하게 되면서 한 Thread에서 List를 사용하면서 동시에 다른 Thread에서도 List를 사용하기 때문에 충돌 문제가 발생합니다.
멀티코어 프로세서의 이점을 살리기 위해서 병렬 처리를 진행했지만 틀린 결과가 반환되는 부정적인 상황에 빠지게 됩니다.
쓰레드 충돌을 해결할 수 있는 방법
그렇다면, 병렬 처리를 유지하면서 올바른 결과를 도출하기 위해서는 어떻게 해야 할까요?
바로 동기화를 해주면 됩니다.
첫 번째 방법은 List를 SynchronizedList로 만드는 것입니다.
SynchronizedList는 동시성을 제어할 수 있는 상태의 List입니다. 하나의 Thread가 점유하는 시점에 Lock을 걸어 Thread Safe하게 작동하도록 해줍니다. 하지만, Thread가 점유하고 풀 때 Lock Unlock 작업이 반복되기 때문에 성능이 많이 떨어집니다.
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
numbers.add(i);
}
List<Integer> evenNumbers = Collections.synchronziedList(new ArrayList());
numbers.parallelStream().filter(number -> number % 2 == 0).forEach(evenNumbers::add);
System.out.println(evenNumbers.size());
50000
걸린시간 : 53ms결과는 올바르게 나오고 걸린시간은 약 53ms 정도입니다.
두 번째 방법은 ParallelStream이 끝나는 시점에 collect를 호출하여 List로 수집한 뒤 수집된 List로 처리하는 방법입니다.
이 방식을 사용하게 되면 parallelStream이 종료되는 시점에 return 되는 값들을 List에 수집하여 돌려주게 되는데, Stream 인터페이스의 collect 메서드에 병렬처리와 동시성 여부를 확인하는 로직이 포함되어 있기 때문에 안전하게 동시성 이슈를 해결할 수 있습니다.
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
numbers.add(i);
}
List<Integer> evenNumbers = numbers.parallelStream()
.filter(number -> number % 2 == 0)
.collect(Collectors.toList());
System.out.println(evenNumbers.size());
50000
걸린시간 : 48msSynchronizedList와 collect 수집 로직의 연산속도를 비교하려고 했는데 표본이 작아서인지 시간 차이가 유의미하게 나오지는 않았습니다.
그래서 범위를 1억개로 늘려서 한 번 더 테스트해봤습니다.
SynchronizedList
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
numbers.add(i);
}
List<Integer> evenNumbers = Collections.synchronziedList(new ArrayList());
numbers.parallelStream().filter(number -> number % 2 == 0).forEach(evenNumbers::add);
System.out.println(evenNumbers.size());
5000000
걸린시간 : 906mscollect 메서드 사용
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
numbers.add(i);
}
List<Integer> evenNumbers = numbers.parallelStream()
.filter(number -> number % 2 == 0)
.collect(Collectors.toList());
System.out.println(evenNumbers.size());
5000000
걸린시간 : 588ms확실히 범위가 늘어나니까 collect 메서드를 사용했을 때의 속도가 1.5배 가량 더 빠른 것을 확인할 수 있었습니다.
따라서 병렬 처리를 하게 된다면 collect 메서드로 수집하는 방식으로 동시성 이슈를 해결하는 것이 좋다고 생각합니다.
번외로 그냥 스트림을 썼을 때와 속도 차이가 얼마나 나는지 궁금해서 그냥 Stream을 썼을 때도 속도를 측정해봤습니다.
List<Integer> numbers = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
numbers.add(i);
}
List<Integer> evenNumbers = new ArrayList();
numbers.stream().filter(number -> number % 2 == 0).forEach(evenNumbers::add);
System.out.println(evenNumbers.size());
5000000
걸린시간 : 507ms응??
병렬스트림을 썼을 때보다 속도가 훨씬 빠른 것 같네요 😂😂
즉, 병렬 처리가 이론상으로는 성능이 더 좋을 것 같지만 순차 처리를 했을 때 성능이 오히려 더 좋은 경우도 있으니까 개발자가 유연하게 선택을 하는 것이 좋을 것 같습니다!!
