
Attention을 활용한 Seq2Seq로 기계번역을 구현해보겠습니다.
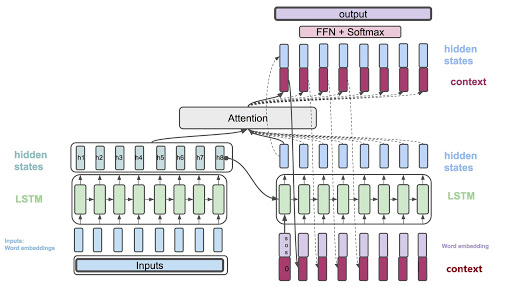
seq2seq 구조
학습, 평가 데이터
- 불어 -> 영어 데이터: https://www.manythings.org/anki/
구현 소스코드
- 라이브러리 import
import unicodedata
import re
import random
from tqdm import tqdm
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F- cpu, gpu 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)- 단어 -> 인덱스 변환
SOS_TOKEN = 0
EOS_TOKEN = 1
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2
def add_word(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
def add_sentence(self, sentence):
for word in sentence.split(' '):
self.add_word(word)
def unicode2Ascii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn'
)
def normalizeString(s):
s = unicode2Ascii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
def read_langs(lang1, lang2, reverse=False):
lines = open('./data/{}-{}.txt'.format(lang1, lang2), encoding='utf-8').read().strip().split('\n')
pairs = [[normalizeString(pair) for pair in line.split('\t')] for line in lines]
if reverse:
pairs = [list(reversed(pair)) for pair in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs- 문장이 너무 많아 일부 문장만 선택
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
def filter_pair(pair):
# print(len(pair[0].split(' ')) < MAX_LENGTH)
# print(len(pair[1].split(' ')) < MAX_LENGTH)
# print(pair[1].startswith(eng_prefixes))
return len(pair[0].split(' ')) < MAX_LENGTH and len(pair[1].split(' ')) < MAX_LENGTH and pair[1].startswith(eng_prefixes)
def filter_pairs(pairs):
return [pair for pair in pairs if filter_pair(pair)]- 데이터 준비
def prepare_data(lang1, lang2, reverse=False):
input_lang, output_lang, pairs = read_langs(lang1, lang2, reverse)
print("Read %s sentence pairs" % len(pairs))
pairs = filter_pairs(pairs)
print("Trimmed to %s sentence pairs" % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.add_sentence(pair[0])
output_lang.add_sentence(pair[1])
print("Counted words:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepare_data('eng', 'fra', True)
print(random.choice(pairs))- encoder 모델 구현
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def init_hidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)- attention decoder 모델 구현
class AttentionDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttentionDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attention = nn.Linear(self.hidden_size * 2, self.max_length)
self.attention_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attention_weights = F.softmax(
self.attention(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attention_applied = torch.bmm(attention_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attention_applied[0]), 1)
output = self.attention_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attention_weights- 학습 데이터로 텐서 생성
def index_from_tensor(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensor_from_sentence(lang, sentence):
indexes = index_from_tensor(lang, sentence)
indexes.append(EOS_TOKEN)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensors_from_pair(pair):
input_tensor = tensor_from_sentence(input_lang, pair[0])
target_tensor = tensor_from_sentence(output_lang, pair[1])
return input_tensor, target_tensor- 학습
TEACHER_FORCING_RATIO = 0.5
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):
encoder_hidden = encoder.init_hidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
output_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0,0]
decoder_hidden = encoder_hidden
decoder_input = torch.tensor([[SOS_TOKEN]], device=device)
is_teacher_forcing = True if random.random() < TEACHER_FORCING_RATIO else False
if is_teacher_forcing:
for di in range(output_length):
decoder_output, decoder_hidden, attention_weights = decoder(decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
# 학습 데이터에서 다음 입력을 선택
decoder_input = target_tensor[di]
else:
for di in range(output_length):
decoder_output, decoder_hidden, attention_weights = decoder(decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
# decoder의 출력 값을 다음 입력을 선택
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
if decoder_input.item() == EOS_TOKEN:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / output_length
def train_iters(encoder, decoder, n_iters, print_every=10000, learning_rate=0.01):
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
training_pairs = [tensors_from_pair(random.choice(pairs)) for iter in range(n_iters)]
print('training_pairs:', tensors_from_pair(random.choice(pairs)))
criterion = nn.NLLLoss()
print_loss_total = 0
for iter in tqdm(range(1, n_iters+1)):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH)
print_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('loss: %.4f' % print_loss_avg)
HIDDEN_SIZE =256
encoder = EncoderRNN(input_lang.n_words, HIDDEN_SIZE).to(device)
decoder = AttentionDecoderRNN(HIDDEN_SIZE, output_lang.n_words).to(device)
train_iters(encoder, decoder, 75000)- 평가
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensor_from_sentence(input_lang, sentence)
input_length = input_tensor.size()[0]
encoder_hidden = encoder.init_hidden()
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei],
encoder_hidden)
encoder_outputs[ei] += encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_TOKEN]], device=device) # SOS
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(max_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_TOKEN:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words
def evaluate_randomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs)
print('French: ', pair[0])
print('English: ', pair[1])
output_words = evaluate(encoder, decoder, pair[0])
output_sentence = ' '.join(output_words)
print('Machine Result: ', output_sentence)
evaluate_randomly(encoder, decoder)- 평가 결과


Yes, Code Wins Arguments!!