기준모델(Baseline Model)
예측 모델을 구체적으로 만들기 전에 가장 간단하면서도 직관적이면서 최소한의 성능을 나타내는 기준이 되는 모델
- 분류문제: 타겟의 최빈 클래스
- 회귀문제: 타겟의 평균값
- 시계열회귀문제: 이전 타임스탬프의 값
Mean Absolute Error(MAE, 평균절대오차)
예측 error 의 절대값 평균
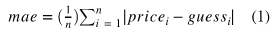
예측모델(Predictive Model) 활용
scatterplot에 가장 잘 맞는(best fit) 직선을 그려주면 그것이 회귀 예측모델이 된다.
회귀직선은 어떻게 만들 수 있을까?
회귀분석에서 중요한 개념은 예측값과 잔차(residual) 이다.
예측값은 만들어진 모델이 추정하는 값이고, 잔차는 예측값과 관측값 차이다.
(오차(error)는 모집단에서의 예측값과 관측값 차이)
회귀선은 잔차 제곱들의 합인 RSS(residual sum of squares)를 최소화 하는 직선이다.
RSS는 SSE(Sum of Square Error)라고도 말하며, 이 값이 회귀모델의 비용함수(Cost function)가 된다.
머신러닝에서는 이렇게 비용함수를 최소화 하는 모델을 찾는 과정을 학습이라고 한다.
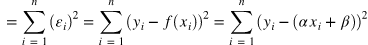
여기서 계수 와 는 RSS를 최소화 하는 값으로 모델 학습을 통해서 얻어지는 값이다.
이렇게 잔차제곱합을 최소화하는 방법을 최소제곱회귀 혹은 Ordinary least squares(OLS)라고 부른다.
OLS는 계수 계산을 위해 다음 공식을 사용함
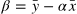
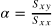
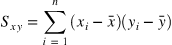
선형회귀 직선은 독립변수(independent variable, x)와 종속변수(dependent variable, y) 간의 관계를 요약해 준다.
- 종속변수 : 반응(Response)변수, 레이블(Label), 타겟(Target) 등
- 독립변수 : 예측(Predictor)변수, 설명(Explanatory), 특성(feature) 등
Simple Linear Regression (단순 선형 회귀)
Scikit-Learn 라이브러리 활용하여 머신러닝 모델 구축
from sklearn.linear_model import LinearRegression
# 예측모델 인스턴스 생성
model = LinearRegression()
# X 특성들의 테이블과, y 타겟 벡터를 만듦
feature = ['a']
target = ['b']
X_train = df[feature]
y_train = df[target]
# 모델을 학습(fit)합니다
model.fit(X_train, y_train)
# 새로운 데이터 한 샘플을 선택해 학습한 모델을 통해 예측
X_test = [[x]]
y_pred = model.predict(X_test)선형회귀모델의 계수(Coefficients)
생성한 모델로부터 어떤 관계를 학습했는지 확인할 수 있다.
# 계수(coefficient)
model.coef_
# 절편(intercept)
model.intercept_지도학습 ( Supervised Learning )
지도 학습 (Supervised Learning)은 훈련 데이터(Training Data)로부터 하나의 함수를 유추해내기 위한 기계 학습(Machine Learning)의 한 방법이다.
지도 학습기(Supervised Learner)가 하는 작업은 훈련 데이터로부터 주어진 데이터에 대해 예측하고자 하는 값을 올바로 추측해내는 것이다.
이 목표를 달성하기 위해서는 학습기가 "알맞은" 방법을 통하여 기존의 훈련 데이터로부터 나타나지 않던 상황까지도 일반화하여 처리할 수 있어야 한다.
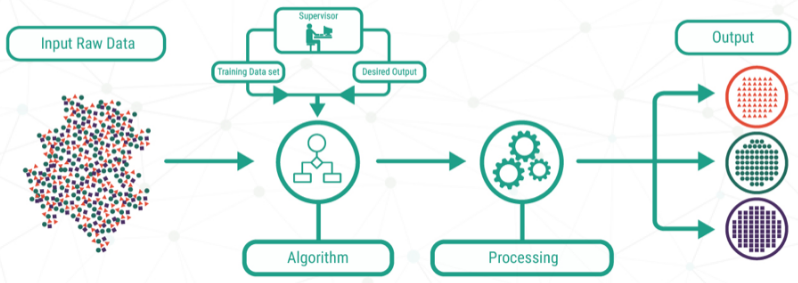
머신러닝은 데이터와 답을 통해 룰을 찾아내는 방법이라고 볼 수 있다.
