
문제 설명
Amber's conglomerate corporation just acquired some new companies. Each of the companies follows this hierarchy:

회사에서 합병을 하게 되어 회사에 직원들이 다음과 같은 구조로 이루어져 있다고 한다.
Given the table schemas below, write a query to print the company_code, founder name, total number of lead managers, total number of senior managers, total number of managers, and total number of employees. Order your output by ascending company_code.
테이블은 다음의 5개의 테이블이 있고
테이블
company table
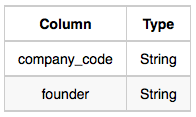

Lead_Manager table


Senior_Manager table
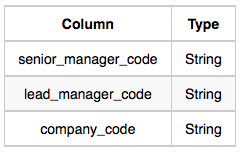
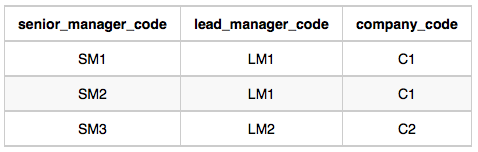
Manager table
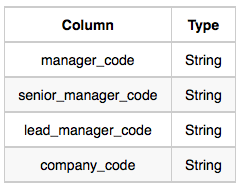
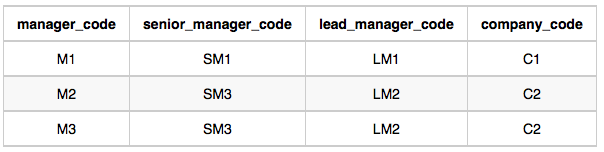
Employee table
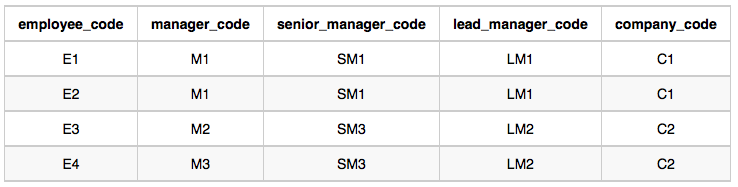
다음의 테이블을 보고
- company_code
- founder name
- total number of lead managers
- total number of senior managers
- total number of managers
- total number of employees
을 쿼리로 나타내고, 나타낸 데이터를 company_code 로 정렬해야 한다.
Note:
- The tables may contain duplicate records.
- The company_code is string, so the sorting should not be numeric. For example, if the company_codes are C_1, C_2, and C_10, then the ascending company_codes will be C_1, C_10, and C_2.
테이블은 중복된 데이터를 포함할 수 있고,
company_code 는 숫자형이 아닌 문자열이기 때문에 정렬을 다음과 같이 해야한다.
C_1, C_2, C_10 - (X)
C_1, C_10, C_2 - (O)
Sample Output
C1 Monika 1 2 1 2
C2 Samantha 1 1 2 2
위와같은 테이블 데이터로 쿼리를 짜면
company_code
c1, c2founder
Monika, Samanthalead_manager_code
C1 회사에 LM1 한명이 있으므로 : 1
C2 회사에 LM2 한명이 있으므로 : 1senior_manager_code
LM1 밑에 SM1, SM2 두명이 있으므로 : 2 (C1)
LM2 밑에 SM3 한명이 있으므로 : 1 (C2)manager_code
SM1 밑에 M1 한명이 있으므로 : 1 (C1)
SM3 밑에 M2, M3 두명이 있으므로 : 2 (C2)employee table
M1 밑에 E1, E2 두명이 있으므로 : 2 (C1)
M2 밑에 E3, M3 밑에 E4 두명이 있으므로 : 2 (C2)문제 풀이
잘못된 풀이
employee 테이블에 정보가 다 나와있기 때문에 이와 company 테이블만을 이용해서 문제를 풀어보도록 하겠다.
SELECT
C.company_code,
C.founder,
COUNT(DISTINCT E.lead_manager_code),
COUNT(DISTINCT E.senior_manager_code),
COUNT(DISTINCT E.manager_code),
COUNT(DISTINCT E.employee_code)
FROM Company C
JOIN Employee E ON C.company_code = E.company_code
GROUP BY
C.company_code,
C.founder
ORDER BY C.company_code
GROUP BY 에 C.company_code, C.founder 를 사용하는 이유?
이 문제에서는 "각 company_code" 마다 직급별 인원 수를 출력해야 하기 때문에
company_code 컬럼으로 GROUP_BY 를 해주어야 한다.
또한, company_code 와 1:1의 관계 를 가지는 founder 는 연산(이 문제에서는 인원 수 구하기)에 사용될 컬럼이 아니고, company_code 와 같이 그룹을 묶는 기준이 되므로 GROUP BY 에 함께 사용해야 한다.
(참고, GROUP BY를 쓸 때 SELECT 절에는 그룹을 묶는 기준이 되는 컬럼과, 다른 컬럼의 집계값만 사용할 수 있다.)
또한, 각각의 직원 코드에서 중복된 직원의 개수는 제외해주어야 하므로
COUNT 안에 Distinct 를 사용하였다.
하지만, 위와 같은 풀이로 하게 되면 오류가 생기게 된다.
위의 주어진 예시를 다시한번 보자
이 두가지 테이블을 가지고 다시 한번 갯수를 카운트 해보자.
company_code
c1, c2founder
Monika, Samanthalead_manager_code
C1 회사에 LM1 한명이 있으므로 : 1
C2 회사에 LM2 한명이 있으므로 : 1senior_manager_code
LM1 밑에 SM1 한명이 있으므로 : 1 (C1)
LM2 밑에 SM3 한명이 있으므로 : 1 (C2)manager_code
SM1 밑에 M1 한명이 있으므로 : 1 (C1)
SM3 밑에 M2, M3 두명이 있으므로 : 2 (C2)employee table
M1 밑에 E1, E2 두명이 있으므로 : 2 (C1)
M2 밑에 E3, M3 밑에 E4 두명이 있으므로 : 2 (C2)C1 Monika 1 1 1 2
C2 Samantha 1 1 2 2
이라는 결과가 나온다.
왜 이런 결과가 나오는 것일까??
바로 employee 테이블에서는 company 부터 employee 까지 모두 연결되는 데이터만 나타내기 때문에 senior_manager_code 에서 SM2는 밑에 직원이 없기 때문에 데이터에 나오지 않아 오류가 발생한다.
(하지만, 이 문제의 테스트 케이스에는 위 같은 검증 데이터가 들어가 있지않아
잘못된 풀이로 답안을 작성해도 정답 처리가 된다.)
올바른 풀이
SELECT
C.company_code,
C.founder,
COUNT(DISTINCT LM.lead_manager_code),
COUNT(DISTINCT SM.senior_manager_code),
COUNT(DISTINCT M.manager_code),
COUNT(DISTINCT E.employee_code)
FROM Company C
LEFT JOIN Lead_Manager LM ON C.company_code = LM.company_code
LEFT JOIN Senior_Manager SM ON LM.lead_manager_code = SM.lead_manager_code
LEFT JOIN Manager M ON SM.senior_manager_code = M.senior_manager_code
LEFT JOIN Employee E ON M.manager_code = E.manager_code
GROUP BY
C.company_code,
C.founder
ORDER BY C.company_code
모든 테이블을 join 하기 위해 join을 연쇄적으로 사용하였고,
INNER JOIN 은 join 하는 테이블에 공통적으로 데이터가 있는 값만
가져오므로 위의 SENIOR MANAGER 의 케이스는 가져오지 못하므로
LEFT JOIN 을 사용하였다.
