자연어처리와 머신러닝(2)
테스트와 검증 보충 설명
테스트와 검증
모델이 새로운 샘플에 얼마나 잘 일반화될지 아는 방법은 새로운 샘플에 실제로 적용해보는 것
- 검증 데이터나 테스트 데이터가 실전에서 기대하는 데이터를 가능한 잘 표현해야함
훈련세트와 테스트세트로 나누어 모델 평가
일반적으로 데이터의 80%를 훈련에, 20%를 테스트에 활용
검증세트를 이용한 하이퍼파라미터 튜닝과 모델 선택
홀드아웃 검증: 훈련세트의 일부를 떼어내어 여러 후보 모델을 평가하는 검증세트로 사용
- 개발세트 (Development Set) or 데브세트 (Dev Set)
- 학습에는 사용 x, (but) 가장 좋은 모델 고르는데 사용
- 검증 세트가 작을 경우, 반복적으로 교차 검증 수행
- K-fold Cross Validation
: 일반화된 성능 결과를 얻기 위해 데이터를 여러번 반복해서 나누고 여러 모델을 학습하여 성능을 평가하는 방법
- K-fold Cross Validation
데이터와 학습에의 영향
- 학습 데이터: 학습 사용 (O), 기여 (O)
- 검증 데이터: 학습 사용 (X), 기여 (O)
- 테스트 데이터: 학습 사용 (X), 기여 (X)
공정한 테스트를 위해 데이터 나누는 방법
- 데이터에 학습 데이터와 테스트 데이터가 나눠져있는 경우
- 학습데이터 / 테스트데이터로 나눠진 경우
- 학습데이터 90% - Training
- 학습데이터 10% - Validation
- Validation data에서 성능이 제일 좋았던 모델에 test data 평가
- 평가 결과를 다른 기존의 모델들과 비교
- 학습데이터 / 검증데이터 / 테스트데이터로 나눠진 경우
- 검증데이터에서 성능이 제일 좋았던 모델에 test data 평가
- 평가 결과를 다른 기존의 모델들과 비교
- 학습데이터 / 테스트데이터로 나눠진 경우
- 다운받은 데이터에 학습 데이터만 있는 경우
- 테스트데이터가 별도인 경우
- 평가주체만 테스트를 가지고 있는 경우,
- 학습데이터 90% - Training
- 학습데이터 10% - Validation
- Validation 성능이 제일 좋았던 모델을 제출
- 학습데이터만 가지고 실험하는 경우
- 학습데이터 80% - Training
- 학습데이터 10% - Validation
- 학습데이터 10% - Test
- 실험의 신뢰도를 향상하기 위해 validation/test 셋의 분포, 실험횟수, 실험결과의 분산을 제시
- 테스트데이터가 별도인 경우
자연어처리 기초(2) - 통계 기반의 자연어처리
언어모델
언어모델이란?
- 언어에서 단어의 시퀀스 확률을 예측하는데 사용되는 모델
- 인간 언어들의 통계적 패턴과 규칙성을 포착하기 위해 개발
단어들의 확률 분포
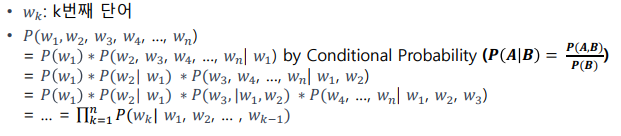
문장에 대한 확률 구하는 법
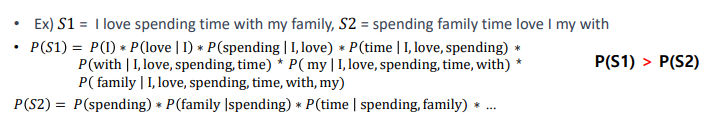
통계적 언어 모델
코퍼스에서 카운트 기반으로 확률을 구함

N-gram
- Uni-gram, Bi-gram, Tri-gram

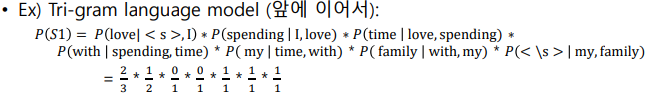
N-gram 언어 모델의 한계
- 정확도 문제: 문자 전체를 다 보는것보다 낮은 정확도를 보일 수 있음
- 희소성 문제: N개의 단어가 항상 코퍼스에서 나타나는 것은 아님
- 상충 문제:
- N이 너무 크면 실제 코퍼스에서 n-gram을 카운트 할 수 있는 확률이 낮아짐
- N이 너무 작으면 근사의 정확도가 현실의 확률분포와 멀어짐
딥러닝 기반의 언어모델
- 비정형 데이터를 사용해서 단어의 확률을 예측하는 딥러닝 모델 학습
- 시퀀스에서 단어를 예측하는 방식에 따라 두 가지 유형으로 분류
- Autoregressive (Causal) Language Model: 다음 단어를 예측하는 언어모델 (GPT, T5, ...)
- Masked Language Model: 특정 단어를 예측하는 언어모델 (BERT, BART, ELECTRA, ...)
- 만들어진 언어모델을 사전학습으로 사용하고 목적 task 데이터셋에 미세조정 (Fine-Tuning)함.
자연어처리 문제
카테고리 분류
감정분석도 일종의 카테고리 분류
- 클래스가 positive/negative 인 형태
Support Vector Machine (SVM)
- 분류에 대표적으로 쓰이는 머신러닝 알고리즘
- 분류 오차를 줄이면서 동시에 여백을 최대로 하는 결정 경계를 찾는 이진 분류기
- 선형이나 비선형분류, 회귀, 이상치 탐색에도 사용할 수 있는 머신러닝 모델
- 여백: 결정 경계와 가장 가까이에 있는 학습데이터까지의 거리
- 서포트벡터: 결정경계로부터 가장 가까이에 있는 학습데이터들
SVM
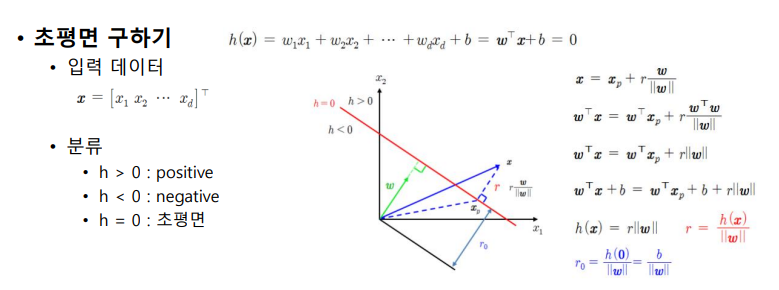
초평면
- 4차원 이상의 공간에서 선형방정식으로 표현되는 결정 경계
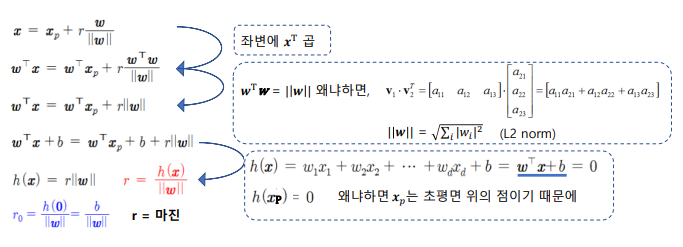
비선형 SVM
- 데이터를 고차원으로 사상(mapping)해서 비선형 특징을 학습할 수 있도록 확장하는 방법
- 고차원으로 변환을 하지 않고 계산할 수 있는 커널함수 사용
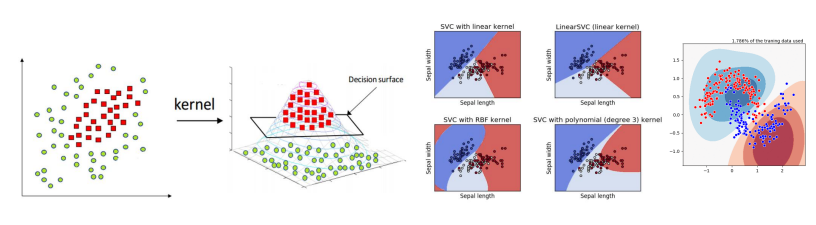
딥러닝 vs SVM
| 딥러닝 | SVM | |
|---|---|---|
| 장점 | - 뛰어난 성능 - 데이터의 복잡한 관계 학습 가능 대규모 데이터를 학습할 수 있음 | - 적은 데이터셋으로도 효과적으로 작동 - 단순한 작업에서 효율적임 학습시간이 빠름 - 오버피팅이 덜 됨 |
| 단점 | - 성능 보장을 위한 많은 비용 필요 - 결과 해석이 어려움 - 오버피팅의 가능성이 있음 | - 커널 선택에 영향을 많이 받을 수 있음 - 노이즈 데이터에 크게 영향 받을 수 있음 - 매우 큰 데이터 처리가 어려움 |
초평면을 잘 찾으려면?
Feature Engineering
- 도메인 지식을 활용하여 데이터에서 특징을 추출하는 작업
- 데이터를 초평면 찾기 좋게 표현하기 위함

자연어처리에 사용되는 자질
TF-IDF
- 용어
- 문서: d, 단어: t, 문서의 총개수: n
- tf(d,t)
- 단어의 빈도수, 특정문서 d에서의 특정 단어 t의 등장횟수
- 단어 t가 d에서 나타난 횟수 / d에서의 총 단어
- df(t)
- 등장 문서 수, 특정 단어 t가 등장한 문서 수
- idf(d,t)
- df의 역수를 취한 값
- 전체 문서수 / t를 포함하는 문서수


벡터화
- TF-IDF 자질을 사용한 벡터화

Summary
언어모델
- 통계 기반의 언어모델
- N-gram 기반의 언어모델
- 딥러닝 기반의 언어모델
SVM
- 대표적인 통계적 분류모델
- 초평면 구하는 법
- 딥러닝 vs SVM
자질 추출
- 자연어처리에서의 대표적인 자질 추출 방법: TF-IDF
머신러닝 과정 실습 (환경준비)
머신러닝 환경 구축
구글 코랩
- 구글 클라우드 서버에서 해당 프로그램이 실행
- 결과를 구글 코랩에 보여줌
- 구글 코랩을 통해 만들고 실행한 파일은 구글 드라이브에 저장
머신러닝 과정 (실습)
머신러닝
데이터에서부터 학습하도록 컴퓨터를 프로그래밍하는 과학 or 예술


Student Dev - Language Tech & Machine Learning