Kafka의 고가용성과 리플리케이션
Kafka는 높은 가용성을 보장하기 위해서 리플리케이션 기능을 제공함.
Kafka는 토픽 자체가 아니라 각각의 파티션을 리플리케이션을 함
리플리케이션 팩터와 리더, 팔로워의 역할
- Kafka에는 리플리케이션 팩터를 설정해줄 수 있음 (기본값 1)
- 리플리케이션 팩터는 리플리케이션 개수를 나타냄
- 리플리케이션 팩터는 운영중에도 변경할 수 있으며, 각 토픽별로도 설정할 수 있음
- 아래의 설정을 사용하여 토픽을 생성할 때 적용되도록 할 수 있음
- Kafka 설정 파일을 수정하기 위해서 열기
vi /usr/local/kafka/config/server.properties- 리플리케이션 팩터를 수정
default.replication.factor = 2- 해당 설정 행이 없다면 기본값으로 설정되어 있는 것이므로 행을 추가해주면 됨
- 클러스터 내 모든 브로커에 동일하게 설정해야 하며, config를 변경한 후에는 브로커를 1대씩 재시작 하면 변경 내용이 적용 됨
- 카프카 로그로 확인 가능
cat /usr/local/kafka/logs/server.log
리플리케이션 예시
Kafka는 파티션에 대해 리플리케이션을 하지만, 이해를 위해 토픽으로 표시
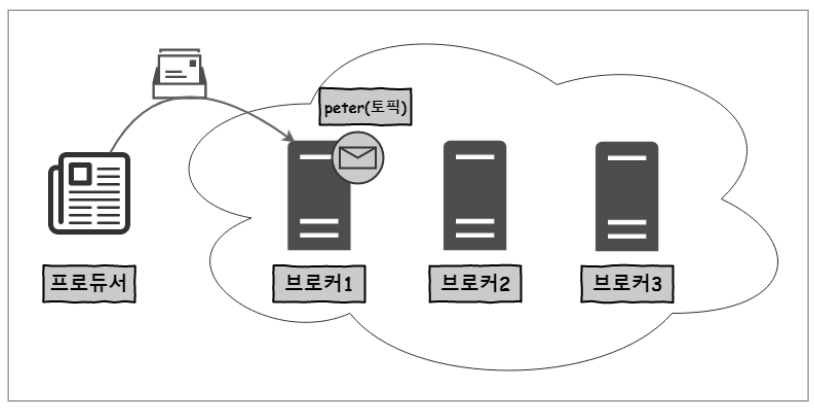 브로커는 3대로 구성이 되어있으며, Producer는 peter라는 토픽에 메시지를 보내는 상황. peter는 리플리케이션이 구성되어 있지 않은 케이스
브로커는 3대로 구성이 되어있으며, Producer는 peter라는 토픽에 메시지를 보내는 상황. peter는 리플리케이션이 구성되어 있지 않은 케이스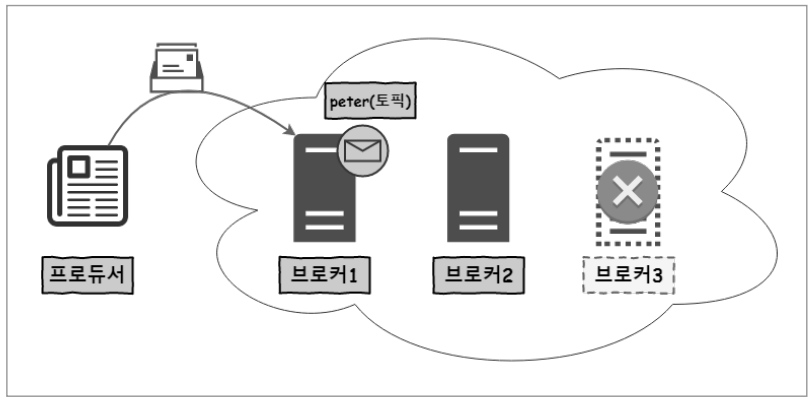 만약 브로커3에 장애가 생긴다면 peter 토픽은 브로커3에 리플리케이션이 구성되어 있지 않으므로 아무런 영향이 없음
만약 브로커3에 장애가 생긴다면 peter 토픽은 브로커3에 리플리케이션이 구성되어 있지 않으므로 아무런 영향이 없음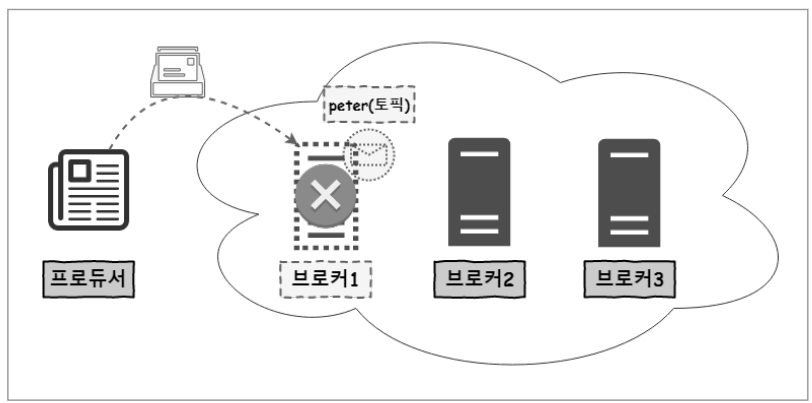 브로커1에 장애가 발생한다면, peter 토픽은 사용할 수 없으며, peter 토픽으로 전송되는 메시지는 전부 유실되기 때문에 크리티컬한 이슈가 발생함
브로커1에 장애가 발생한다면, peter 토픽은 사용할 수 없으며, peter 토픽으로 전송되는 메시지는 전부 유실되기 때문에 크리티컬한 이슈가 발생함 리플리케이션을 구성함으로서 브로커1에 장애가 발생하더라도 대응이 가능하다
리플리케이션을 구성함으로서 브로커1에 장애가 발생하더라도 대응이 가능하다
- 여기서 브로커1에 저장된 원본을 리더라 하고 브로커2에 저장된 복제본을 팔로어라고 한다.
- 읽기와 쓰기는 리더에서만 가능
- 팔로워는 리플리케이션만 하고 읽기 쓰기는 불가능
- 리더와 팔로워는 저장된 데이터의 순서도 일치하며, 동일한 오프셋과 메시지를 가짐
리더와 팔로워 확인하기
/usr/local/kafka/bin/kafka-topic.sh \
--zookeeper {zookeeper server} --topic peter --describe출력
Topic:peter PartitionCount:1 ReplicationFactor:2 Configs:
Topic: peter Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Leader: 1은 0번 파티션 리더가 브로커1에 있다는 의미
Replicas: 1,2는 리플리케이션이 있는 브로커
리더가 있는 브로커에 장애가 발생한 경우
리더가 있는 브로커1에 장애가 발생하게 되면, 팔로워가 있는 브로커2가 새로운 리더가 되어 Producer와 통신하게 된다.

리플리케이션의 단점
- 리플리케이션은 파티션의 데이터를 복제하는 것이므로 디스크 사이즈가 리플리케이션 수 만큼 배가 된다
- 리플리케이션을 보장하기 위해 브로커의 리소스 사용량이 증가해 버린다
- 비활성화된 토픽이 리플리케이션을 잘 하고 있는지, 헬스체크 등의 작업이 발생
따라서 모든 토픽에 리플리케이션 팩터를 3으로 운영하기보다는 중요도에 따라 다르게 적용하여 운영하는 것이 효율적임
리더와 팔로워의 관리
- 리더와 팔로워는 각자의 역할을 맡아 리플리케이션을 수행
- 리더 : 모든 데이터의 읽기와 쓰기에 대한 요청에 응답하면서 데이터를 저장
- 팔로워 : 주기적으로 리더에게서부터 자신에게 없는 데이터를 가져옴
- 팔로워에 문제가 생겨서 리더에게 데이터를 못 가져오게 되면 데이터 정합 문제가 발생
- 리더에 문제가 생겨서 팔로워가 새로운 리더가 되면 이러한 데이터 정합 문제가 이슈가 됨
ISR (In Sync Replica)
- Kafka에는 팔로원와 리더의 데이터 정합에서 문제가 발생하지 않게 하기 위해서 ISR이라는 개념이 있음
- 현재 리플리케이션되고 있는 리플리케이션 그룹
- ISR에는 ISR에 속해 있는 구성원만이 리더의 자격을 가질 수 있다는 규칙이 있음
ISR의 동작
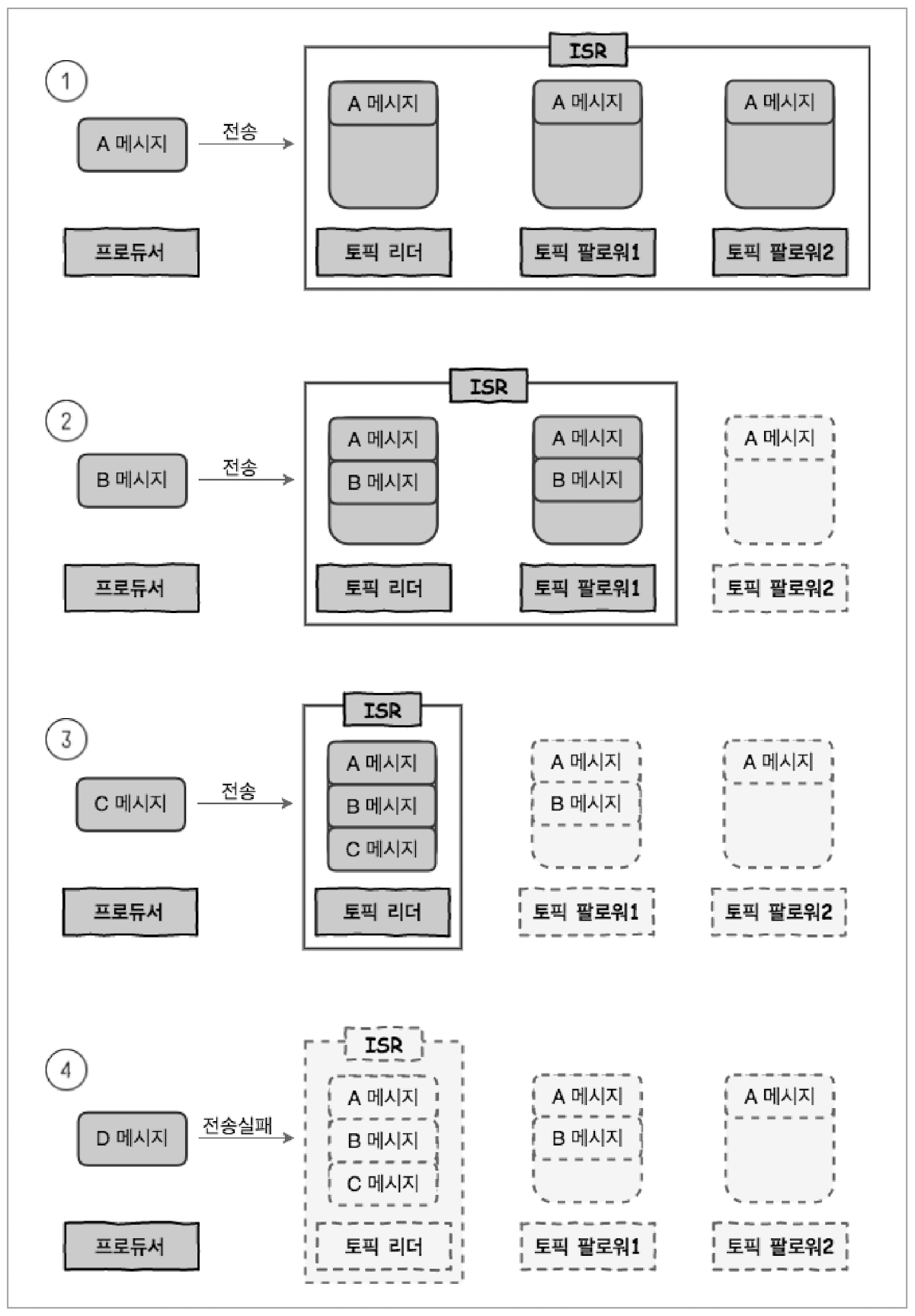
- Producer는 메시지를 토픽의 리더에게 전송
- 리더는 Producer의 요청을 받고 데이터를 저장
- 팔로워1은 정상 동작하여 리더에게서부터 데이터를 가져오고, 팔로워2는 문제가 발생하여 못 가져온 경우, 리더는 이를 감지
- 리더는 팔로워들이 주기적으로 데이터를 가져가는지 확인 (replica.lag.time.max.ms)
- 리더는 팔로워2를 ISR 그룹에서 추방

모든 브로커가 다운된다면
장애 복구 옵션
장애 발생 시나리오
- Kafka 클러스터는 3대의 브로커로 구성되어 있음
- 토픽은 리플리케이션 팩터 3으로 생성
- Producer가 데이터를 보내는 중 브로커가 하나씩 다운
- 최종적으로 kafka 클러스터내 모든 브로커가 다운
복구 case 1 : 마지막 리더가 살아나는 경우
- 마지막 리더에는 모든 브로커가 다운되기 전 데이터가 전부 저장되어 있으므로, 바로 서비스 제공 가능
- 마지막 리더가 반드시 먼저 시작되어야 하는 필수 조건이 있음
- 팔로워1,2는 바로 복구되었지만, 리더의 복구가 오래걸리는 경우, 서비스 중단이 길어지게 됨
복구 case 2 : ISR에서 추방되었던 팔로워가 살아나서 자동으로 리더가 되는 경우
- ISR에서 추방되었던 팔로워2가 먼저 복구되게 되면 팔로워2가 새로운 리더가 되고 Producer로부터 전송한 메시지를 저장함
- 나머지 브로커가 복구되게 되면 자동으로 팔로워가 되고 리더와 데이터 정합을 실행
- 이 과정에서 올드 리더가 가지고 있던 데이터는 유실 됨
- 메시지가 유실되지만 빠른 복구로 빠른 서비시 재시작을 할 수 있음
복구 옵션 설정
- 두 case는 장단점이 있기 때문에 Kafka에서는 이를 옵션으로 설정할 수 있도록 제공
- 설정 파일에서
unclean.leader.election.enable을 설정
vi /usr/local/kafka/config/server.properties- 해당 항목은 true, false로 설정 가능
- false는 메시지 손실의 관점엥서 마지막 리더를 기다리는 방법 (case1)
- true는 서비스적 관점에서 메시지 손실이 발생하더라도 빠른 서비스를 제공 (case2)
토픽과 파티션 리플리케이션 구성
- 쉬운 이해를 위해 토픽이 리플리케이션 되는 것처럼 정리했지만, Kafka는 파티션이 리플리케이션 됨
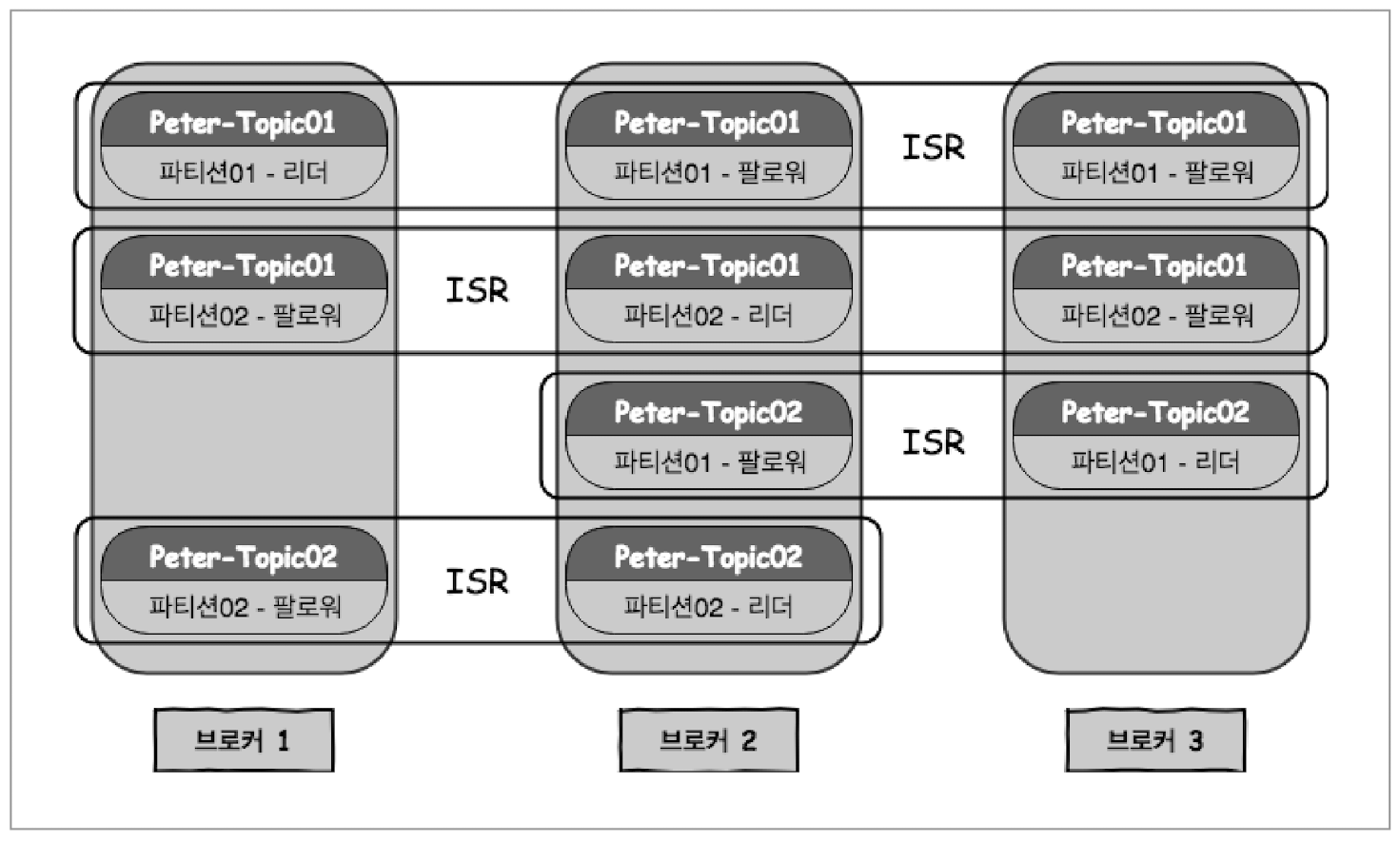
- 아래와 같이 토픽 2개, 파티션 수 2, 리플리케이션 팩터는 각각 2,3으로 설정
| 토픽명 | peter-topic01 | peter-topic02 |
|---|---|---|
| 파티션 수 | 2 | 2 |
| 리플리케이션 팩터 | 3 | 2 |
| Kafka 클러스터 | 3 | 3 |
리플리케이션 구성
peter-topic01
- 파티션 수는 2, 리플리케이션 팩터 3
- 리플리케이션 팩터가 3이기 때문에 리더1과 팔로워2로 구성됨
- 파티션01과 파티션02의 리더는 다른 브로커에 존재
peter-topic02
- 파티션 수 2,리플리케이션 팩터 2
- 리더 1과 팔로워 1로 구성됨
- 각 파티션의 리더는 다른 브로커에 구성 되며, 되도록 데이터가 모든 브로커에 분산되서 저장되도록 구성 됨
[reference]
카프카, 데이터 플랫폼의 최강자 - 실시간 비동기 스트리밍 솔루션 Kafka의 기본부터 확장 응용까지

SW 지식 노트 블로그