개요
Kafka는 connector라는 것을 사용하여, 다른 시스템과 연결이 가능하다.
AWS에서도 connenctor를 배포해서 MSK와 연결할 수 있도록 서비스를 제공하고 있다.
프로젝트에서 MSK에 스트리밍 되는 데이터를 S3에 저장할 필요가 있었기 때문에,
S3 sink connector를 사용해서 MSK와 S3를 연결하는 방법을 정리하려고 한다.
connector 생성하기
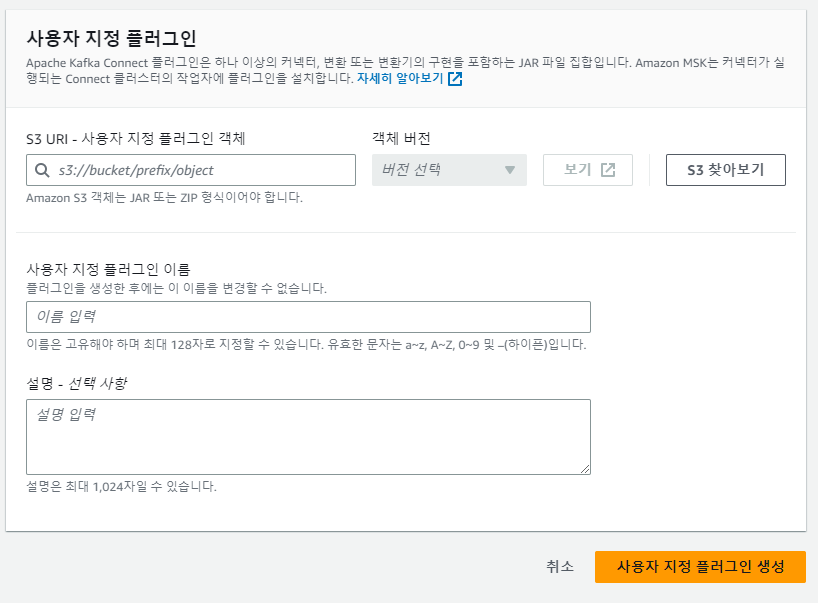
사용자 지정 Plug in 설정
Plug in은 connector 로직이 정의되어 있는 code 및 리소스를 나타낸다.
서드 파티의 형식으로 이미 구성되어 있으므로 다운로드 받아서 사용하면 된다.
- CONFLUENT에서 S3 sink connector 다운로드
- S3에서 Bucket 생성 후, 생성한 Bucket에 다운로드한 Plug in 저장
- AWS console > MSK > 사용자 지정 플러그인 에서 "사용자 지정 플러그인 생성"
- S3 URI - 사용자 지정 플러그인 객체 : Amazon S3 Sink Connector 파일 저장한 Bucket 선택
VPC 엔드포인트 설정
MSK Cluster가 생성된 VPC가 S3에 접근할 수 있도록 엔드포인트를 설정 해줘야 한다.
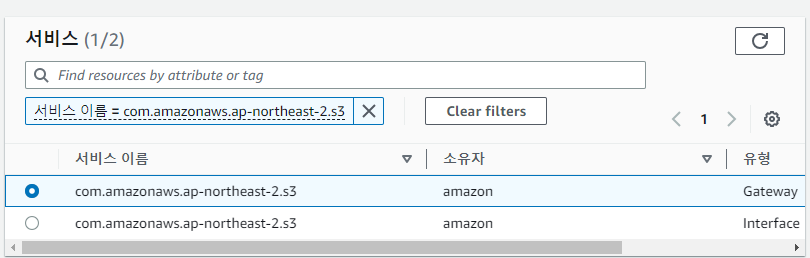
- AWS console > VPC > 엔드포인트 에서 "엔드포인트 생성"
- AWS 서비스에서 S3 검색
- 유형이 Gateway인 S3 서비스 선택
- MSK Cluster가 생성된 VPC 선택
- MSK Cluster가 연결된 Routing table 선택
작업자 구성
작업자(Worker)는 Connector의 로직을 실행하는 프로세스를 나타낸다.
Connector를 생성할 때 작업자를 선택해야하는데, AWS에서 제공하는 기본 작업자를 사용해도 되지만, 커스터마이즈도 가능하다.
기본 작업자
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter사용자 지정 작업자 구성
- AWS console > MSK > 작업자 구성에서 "작업자 구성 생성"
- 작업자 구성 설정
key.converter및value.converter속성은 필수 설정- MSK Connect에서 지원하는
producer.구성 속성
producer.acks
producer.batch.size
producer.buffer.memory
producer.compression.type
producer.enable.idempotence
producer.key.serializer
producer.max.request.size
producer.metadata.max.age.ms
producer.metadata.max.idle.ms
producer.partitioner.class
producer.reconnect.backoff.max.ms
producer.reconnect.backoff.ms
producer.request.timeout.ms
producer.retry.backoff.ms
producer.value.serializer- MSK Connect에서 지원하는
consumer.구성 속성
consumer.allow.auto.create.topics
consumer.auto.offset.reset
consumer.check.crcs
consumer.fetch.max.bytes
consumer.fetch.max.wait.ms
consumer.fetch.min.bytes
consumer.heartbeat.interval.ms
consumer.key.deserializer
consumer.max.partition.fetch.bytes
consumer.max.poll.records
consumer.metadata.max.age.ms
consumer.partition.assignment.strategy
consumer.reconnect.backoff.max.ms
consumer.reconnect.backoff.ms
consumer.request.timeout.ms
consumer.retry.backoff.ms
consumer.session.timeout.ms
consumer.value.deserializer- MSK Connect에서 지원하지 않는 구성 속성
access.control.
admin.
admin.listeners.https.
client.
connect.
inter.worker.
internal.
listeners.https.
metrics.
metrics.context.
rest.
sasl.
security.
socket.
ssl.
topic.tracking.
worker.
bootstrap.servers
config.storage.topic
connections.max.idle.ms
connector.client.config.override.policy
group.id
listeners
metric.reporters
plugin.path
receive.buffer.bytes
response.http.headers.config
scheduled.rebalance.max.delay.ms
send.buffer.bytes
status.storage.topicIAM 설정
정책 설정
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:DeleteObject",
"s3:PutObject",
"s3:GetObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts",
"s3:ListBucketMultipartUploads"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect",
"kafka-cluster:AlterCluster",
"kafka-cluster:DescribeCluster"
],
"Resource": [
"arn:aws:kafka:{region}:{account}:cluster/{mak_name}/*"
]
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:*Topic*",
"kafka-cluster:WriteData",
"kafka-cluster:ReadData"
],
"Resource": [
"arn:aws:kafka:{region}:{account}:topic/{mak_name}/*"
]
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:AlterGroup",
"kafka-cluster:DescribeGroup"
],
"Resource": [
"arn:aws:kafka:{region}:{account}:group/{mak_name}/*"
]
}
]
}신뢰 관계 설정
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "kafkaconnect.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}connector 생성
- AWS console > MSK > 커넥터에서 "커넥터 생성"
- 사용자 지정 플러그 유형 선택
- 위에서 생성한 Plug in 선택
- 생성하지 않았다면 해당 페이지에서 생성 가능

- msk cluster 선택
- msk가 아닌 ec2에서 kafka를 구성한 경우 해당 vpc와 연결도 가능
- 커넥터 구성
커넥터 구성의 경우, 여기에서 확인 가능하다.
구성 설정이 많지만, 커스터마이징을 위해서 꼭 읽어볼 필요가 있다.
아래는 프로젝트에서 사용한 구성이다. 예시로서 참조
connector.class=io.confluent.connect.s3.S3SinkConnector // 배포하려는 connector class (현재는 s3 sink connector)
s3.region={region} // 데이터를 저장할 s3의 region
partition.duration.ms=60000 // 파티션 주기 : batch window (TimeBasedPartitioner을 설정하기 위해 필수)
flush.size=1000 // s3 한 객체에 저장할 레코드 수
schema.compatibility=NONE // 커넥터가 스키마 변경을 관찰할 때 사용할 스키마 호환 규칙
timezone=UTC // timezone (TimeBasedPartitioner을 설정하기 위해 필수)
tasks.max=1 // connector가 수행할 task 수
topics={topic} // msk에 구독할 topic, 복수 설정할 경우 쉼표(,)로 구분하면 됨
locale=ko-KR // 위치 (TimeBasedPartitioner을 설정하기 위해 필수)
format.class=io.confluent.connect.s3.format.json.JsonFormat // s3에 저장할 객체의 형식 (json)
partitioner.class=io.confluent.connect.storage.partitioner.TimeBasedPartitioner // s3에 객체를 저장할 시, 파티션을 나눌 기준
storage.class=io.confluent.connect.s3.storage.S3Storage // 스토리지 계층
rotate.schedule.interval.ms=60000 // 파일 커밋 주기
s3.bucket.name={bucket_name} // 파일 저장할 bucket 이름
path.format=YYYY/MM/dd/HH // partition path // 파일 저장할 path ()
timestamp.extractor=Wallclock // TimeBasedPartitioner로 파티셔닝할 때 레코드의 timestamp를 가져오는 추출기- connector 용량
- 프로비저닝됨
- connector를 실행할 작업자 수
- 작업자 당 MCU 수
- 자동 크기 조정
- 작업자당 MCU 수
- 최소 작업자, 최대 작업자 수
- 크기 조정 임계값

SW 지식 노트 블로그