Opinion Extraction from Reviews
리뷰에서의 의견은 Aspect term과 opinion term으로 나눌 수 있다. 식당A에 대한 리뷰에서 '음식'은 aspect term이 될 수 있고 '맛있다'는 opinion term이 된다. 아래 예시는 Target-oriented Opinion Words Extraction(TOWE) task에서 사용한 데이터셋이다. paper link 중국의 연구자들이 직접 많은 리소스를 들여 구축했다고 한다.

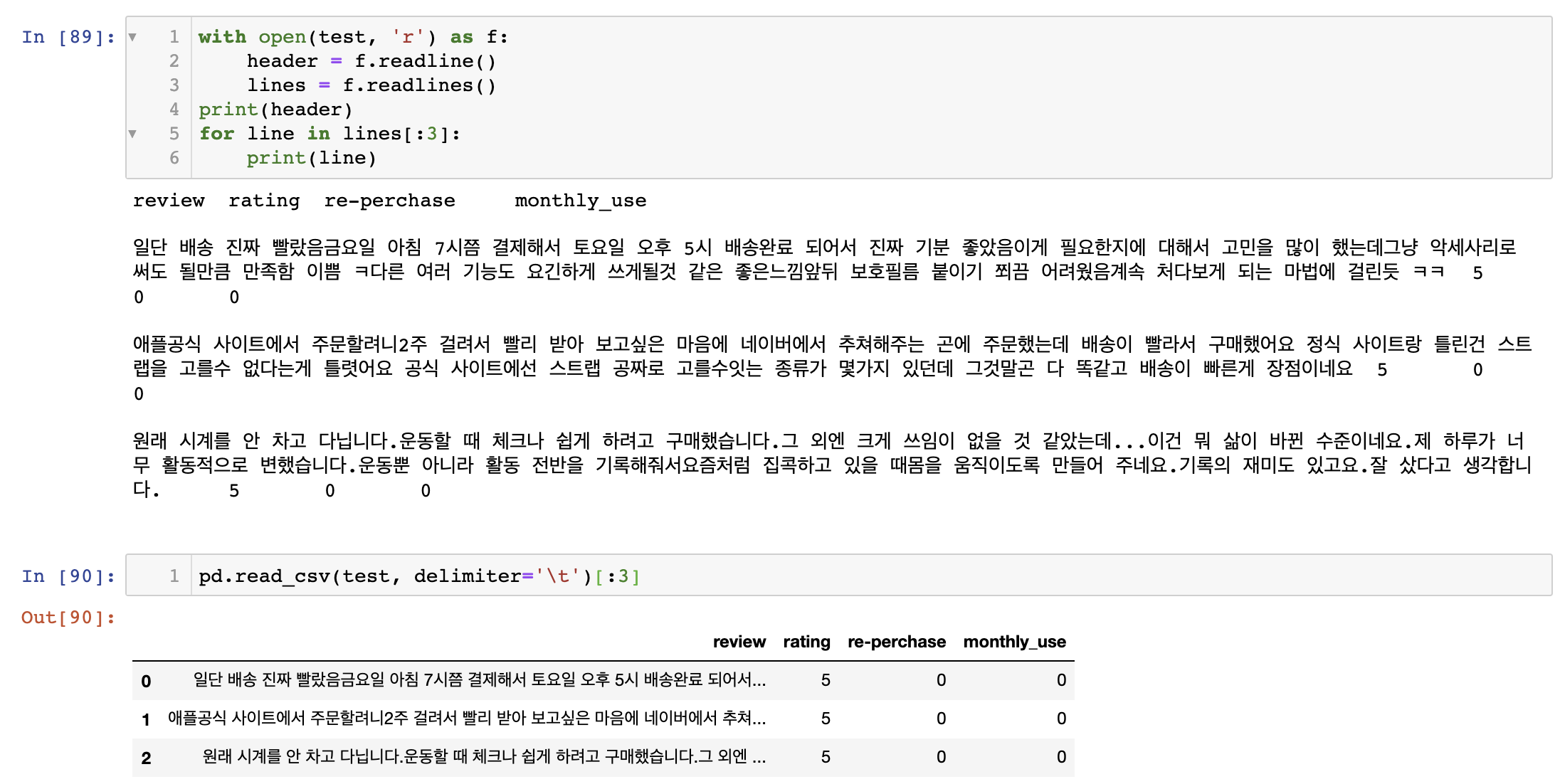
네이버 쇼핑에서의 실제 사례 아래와 같다. (무드등 색-다양하다), (소음이-시계 초침소리가 들릴만큼 없다), (분무-빵빵하게 잘 나온다) 등이 하이라이트되어 있으나 생각보다 정확한 부분만을 가리키고 있지는 않다.
한국어 데이터셋의 구축
Aspect와 Opinion을 파악하는 태스크는 리뷰에서의 opinion extraction, summarization이라 할 수 있다. 여러 문서들에서의 Summarization, Opinion Extraction은 핵심 문장들을 abstractive 또는 extractive하게 뽑아내는 것이지만, 하나의 리뷰 안에서는 Aspect-Opinion pair를 뽑아내는 것이다.
위의 TOWE 데이터셋과 마찬가지의 데이터셋이 필요하다. 하지만 현재는 리뷰와 종합적인 sentiment만 포함된 데이터셋이 대부분이다. 이 모델을 만들어보려고 한다면 나름의 데이터셋을 구축해야 한다.
어려운 이유는
1. 노동력이 많이 든다. 문장 속 모든 단어들에 태그를 다는 방식이기 때문에 단순 긍/부정 감성만 라벨링 하는 것보다 훨씬 리소스가 많이 필요하다.
2. Aspect로 봐야하는지? 모호하다. 보통 pre-defined 된 카테고리(가격, 음식, 분위기 등)와 달리 aspect는 해당 리뷰에서 주요 키워드로 봐야할지 아닐지 인간의 개입이 필요할지도 모른다.
3. Aspect word는 뽑아낸다 하더라도 그에 맞는 opinion word를 찾기 쉽지 않다. 아래와 같은 리뷰가 있을 때 "많은 양" ("양이 많았습니다"), "분위기는 조용했습니다" ("조용한 분위기가 좋았습니다") 처럼 단순 S-V관계가 아닌 수식어까지 살펴보아야 하기 때문에 쉽게 패턴으로 찾아내기 어려울 듯하다.
많은 양이 나왔구요. 분위기는 조용했습니다.
쇼핑 리뷰로 직접 구축해볼까
직접 데이터를 구축해보려고 한다. 얼마나 수요가 있을지 또는 내가 신뢰성을 갖는 데이터를 만들 수 있을지 모르겠지만 간단한 석사논문용 연구를 위해 한번 만들어볼 생각이다.
데이터 크롤링
실제 쇼핑 리뷰들을 우선 10만 건 이상 긁어모았다. 특히 다양한 특성들이 존재할 수 있는 상품군을 선정해서 그 카테고리 위주로 진행했다. (립스틱, 스마트워치, (조명 있는 무드)가습기) 특정 회사의 쇼핑 플랫폼 데이터이기 때문에 scraping 프로그램 코드는 여기에 공개하지는 않겠다.
전처리
크롤링을 진행하면서 다음 몇 가지 전처리를 진행했다.
1. 대량 공백 제거
2. '한달사용기'와 '재구매' 리뷰를 별도 칼럼에 마킹해주고 리뷰 본문이 '한달사용기', '재구매'로 시작하지 않도록 처리
3. 같은 스토어에서 한번에 여러 상품을 구매했을 때 똑같은 내용의 리뷰가 중복되어 등록되는 경우가 있는 것 같음. 연속해서 똑같은 내용이 등록됐을 경우 하나만 남기고 제거.
# 1 대량공백 제거
import re
review = re.sub('\n+|\t+', ' ', review)
review = re.sub(' +', ' ', review)
# 2 한달사용기, 재구매 리뷰 처리
# 한달사용기
if review.startswith('한달사용기'):
review = review[5:]
a_month.append(1)
else:
a_month.append(0)
# 재구매
if review.startswith('재구매'):
review = review[3:]
re_buy.append(1)
else:
re_buy.append(0)
# 3 연속되는 중복 리뷰 제거
def drop_duplicates(reviews, ratings, re_buy, a_month):
before = len(reviews)
i = 0
while i < len(reviews)-1:
if reviews[i] == reviews[i+1]:
reviews.pop(i)
ratings.pop(i)
re_buy.pop(i)
a_month.pop(i)
continue
i += 1
after = len(reviews)
print(' >> {:,} reviews are removed (continuous duplicates)'.format(before-after))
return reviews, ratings, re_buy, a_month결과물
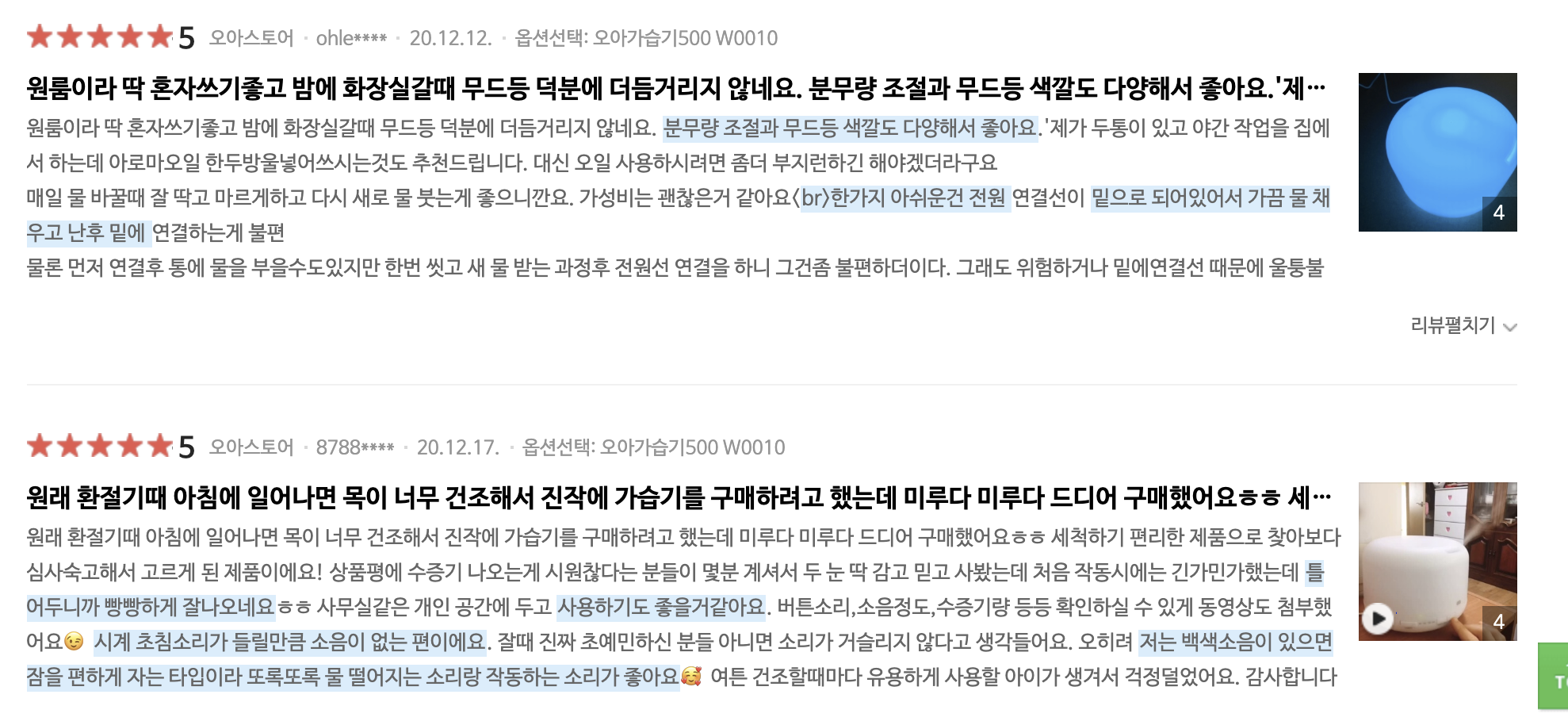
그 결과 아래와 같이 '\t'으로 구분된 데이터셋을 얻을 수 있게 됐다. 이제 이 데이터셋들을 가지고 aspect word와 opinion word들을 non-supervise로 추출해보는 작업들을 해보려고 한다. Rule 기반이면서 상당히 manual한 작업이 될 것 같다.