
앞서 Aspect seed가 될 수 있는 단어들을 추출했다. 단순 빈도 + 특정 상품군에서만 많이 등장하는 단어(Word level TF-IDF) + Common words를 Seed로 선정했다. 여기서는 이 seed word와 유사한 의미를 갖고 있는 단어들을 추출해서 aspect가 될 수 있을지 검토하는 작업을 다뤄보겠다. "음질", "발색", "가습"이 seed word라면 그와 유사한 단어들도 aspect word에 포함될 수 있도록 하는 과정이다.
음질: 음향, 음감, 사운드, ...
발색: 발색력, 착색, 색상, ...
가습: 가습량, 분무량, 분무, 분사량, ...
Word2Vec
Word2Vec은 말 그대로 Word를 Vector로 바꿔주는 방식이다.
음질이 [0,0,0,1,0,0,0,0,0,0...] 이라는 onehot 벡터를 가진다고 할 때 이는 1)너무 sparse하여 모델의 크기가 커지는 문제가 발생할 수 있고, 단순히 onehot으로 나타냈기 때문에 2)음량 [0,0,0,0,0,0,..어딘가에 1,0,0,0] 벡터와의 관계를 나타낼 수도 없다.
그래서 v차원(vocab의 크기)이 아닌 m차원의 벡터로 dense하게 바꿔주면서도 다른 단어들과의 관계를 나타낼 수 있도록 학습시킨다.
어떻게?
비슷한 의미를 갖는 단어들은 비슷한 환경에서 등장한다를 전제로 한다. 발색과 발색력은 다른 단어이지만 앞뒤 단어가 유사할 것이다. 그래서 아래 페이퍼의 그림과 같이 주위 단어들을 통해 가운데 단어를 예측(CBOW)한다거나 중간 단어를 활용해 주위 단어들을 예측(SkipGram)하는 방식으로 Learning이 이뤄지게 만든다.
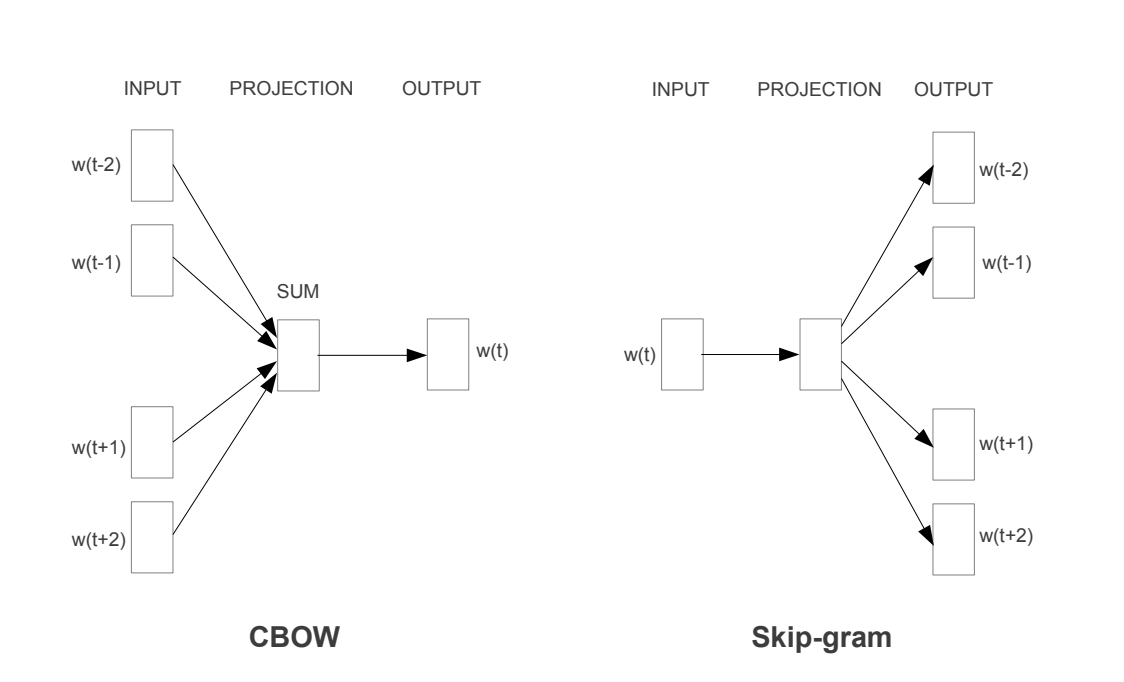
CBOW: Continuous Bag of Words
CBOW는 주위 단어들로 중심 단어를 예측한다. Onehot 형태로 주위 단어들이 들어가기 때문에 어떤 weight matrix를 거쳐서 dense한 벡터로 바뀌게 된다. 그리고 주위 단어 벡터들의 합을 하나의 representation 벡터로 삼고, 두 번째 weight matrix를 통과시켜서 다시 Vocab 만큼의 크기를 갖는 벡터로 결과를 출력해준다. 여기서 주위 단어를 몇개 반영해서 중간 단어를 예측할지 나타내는 걸 window size라 한다.
첫번째 weight matrix는 v * m 차원이고 두번째 matrix는 m * v 차원이 되어야 한다. 그래야 dense한 벡터로 바꿔주었다가 마지막에 다시 v차원의 벡터를 출력함으로서 최종적으로 단어를 예측할 수 있게 되기 때문이다. 최종 v차원 벡터와 truth onehot 벡터 (중간 단어를 나타내는 one-hot 벡터)로 Cross Entropy Loss를 계산해서 중간 matrix의 weight를 바꿔준다.
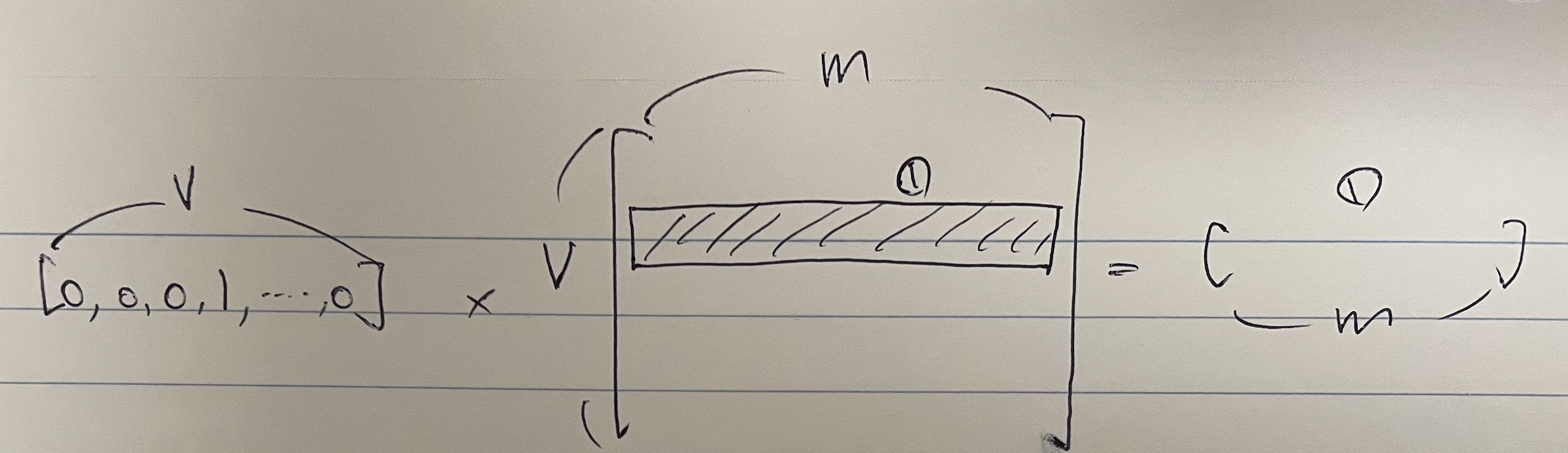
중요한 점은 첫번째 weight matrix가 lookup table이 된다는 점이다. 아래처럼 onehot 벡터에서 dense vector를 뽑다보면 k번째 단어는 k번째 row로 출력되게 된다. 저 matrix가 사전이 되는 것이고, 우리는 저 사전에서 원하는 단어의 벡터를 뽑을 수 있다.
Skipgram
Skipgram도 유사한 방식이다. Vocab size의 one-hot vector가 첫 번째 weight matrix를 통과하여 m차원의 dense vector로 바뀌게 된다. 정해진 window size 개수 만큼의 각각의 weight matrix를 통과시켜서 주위 단어들의 각 자리마다 v차원의 vector들을 뽑아내게 된다. 그리고 그 자리들에 실제로 등장하는 단어(truth)를 가지고 학습을 시킬 수 있다.
Skipgram이 CBOW보다 성능이 좋다고 알려져 있다. 학습이 더 많이 일어나기 때문이다. 단어 1개를 가져와서 주위 단어 개수만큼 weight 학습이 이뤄지기 때문에 여러 단어가 한번만 학습되는 CBOW보다 학습 횟수가 많다. Semantic Accuracy에서 다른 모델들에 비해 월등히 높은 Accuracy를 보인다.
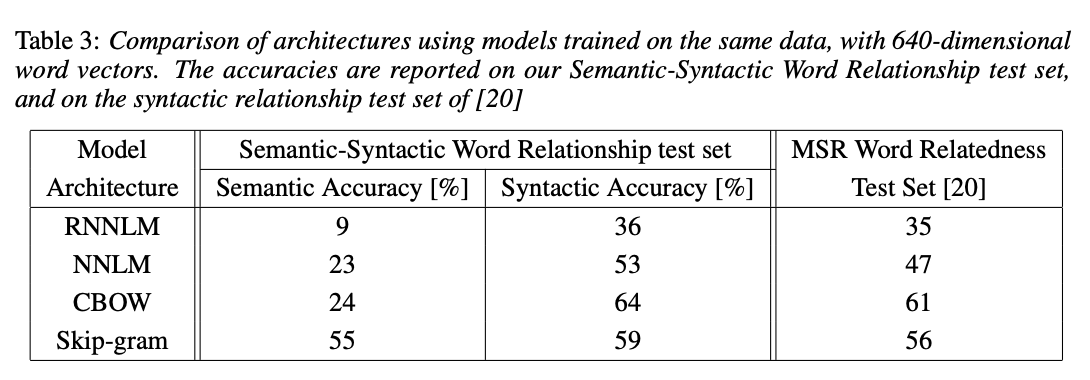
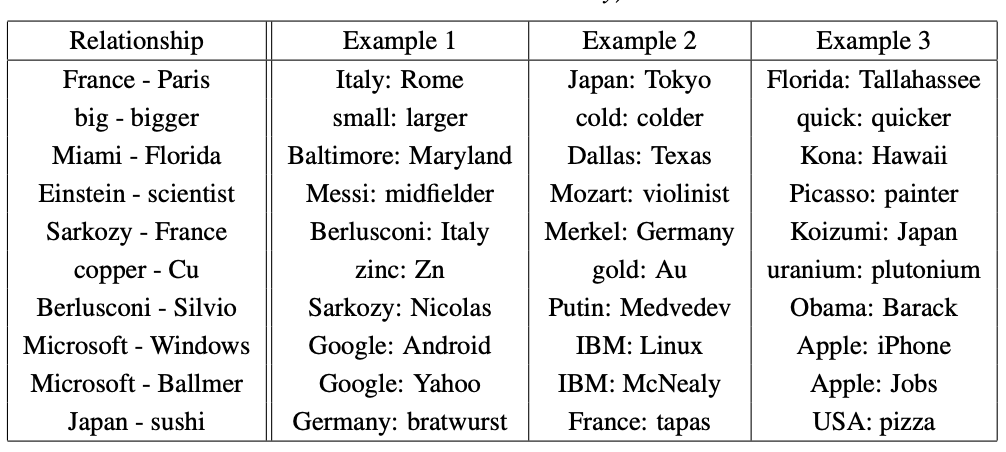
Case Analysis
단순 정확도 수치보다는 어떤 예시들이 존재하는지 보면 이 임베딩 모델의 성능을 쉽게 이해할 수 있다. 페이퍼에서는 아래와 같은 방식으로 관계를 분석해보았다.
Paris - France + Italy = Rome
Paris를 나타내는 벡터에서 France를 나타내는 벡터를 빼고 Italy 벡터를 더했더니... Rome이 나온다고? 이외에도 기업과 SW, 사람과 직업 등의 관계를 많이 이해하고 있었다. Corpus가 클수록 optimization 횟수도 늘어나고 주위 단어의 variance도 줄어들어 성능이 좋아질 것이다.
실제 데이터에 적용했던 후기는 뒷 편에 계속...
Reference
Efficient Estimation of Word Representations in Vector Space (2013)
