두 가지 Dataset 유형
Dict형: dataset[index]를 찍어보았을 때 아래와 같이 데이터셋이 담겨 있는 형태이다. dataset list 안에 dict 형태로 데이터가 존재한다.
{'input_ids': [1944, 126, 34, 122, 2693, ...],
'label': 2,
'tokens': ['_헤드셋', '보다', '_더', '_빨리', ...],
'text': 헤드셋보다 더 빨리왔. 시냅스연결 후 크로마 색도 좋고 ...}
List형: dataset[index] 안에 list 형태로 데이터셋이 담겨 있다.
[[1944, 126, 34, 122, 2693, ..], 2, ['_헤드셋', '보다', '_더', '_빨리', ...], 헤드셋보다 더 빨리왔. 시냅스연결 후 크로마 색도 좋고 ...]
Torch 모델에 넣기 위한 Dataset을 구축할 때 위의 두 가지 방법을 사용하곤 한다. 수십만 건의 데이터를 처리할 때는 큰 차이를 느끼지 못했는데 수천만 건의 데이터로 데이터셋을 만들다 보니 어떤 방식이 얼마나 빠를지 궁금해서 테스트를 해보았다.
실험 데이터셋

간단한 리뷰-감성(별점은 customized하여 encoding) 데이터셋이다. 370만 건 정도만 가지고 테스트를 해보았다.
Tokenizer

자연어 데이터를 Dataset으로 구축할 때에는 Tokenize 작업이 필요하다. 사실 이 부분이 가장 많은 시간을 차지할 것이다. 실험에선 약 500만 건의 동일 카테고리 리뷰로 학습한 SentencePiece Tokenizer를 사용했다. Google의 spm 라이브러리로 사전학습 후 저장해둔 model을 사용한다.
실험 코드
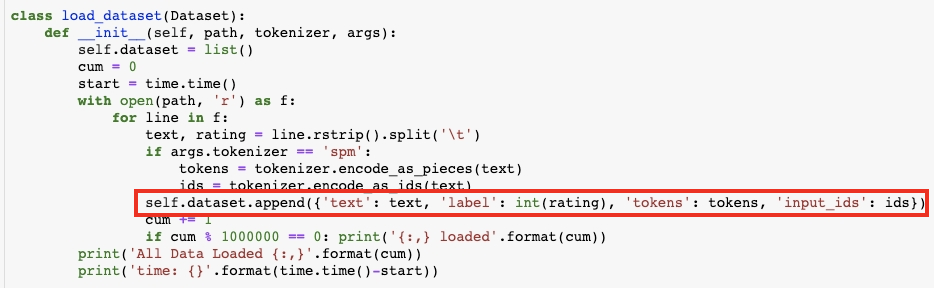

Dict 형태는 위 처럼 dict를 만들어서 추가해주는 형태이고 List형은 아래처럼 추가한다. 너무 많지 않은 데이터셋이기 때문에 list형태로 전체를 받아서 저장해둔다. 그리고 시간 측정.
결과 비교: List형이 20% 가량 빠름

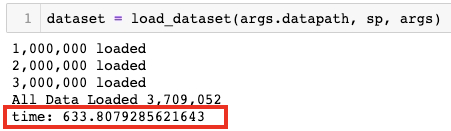
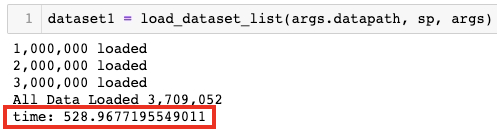
위가 dict형태, 아래가 list형태로 데이터셋을 처리한 결과이다. 각 샘플을 dict로 조합하는 과정에서 시간이 더 소모되는 건 맞지만 약 20% 정도의 차이는 예상보다 컸다.
모델에서 Data를 load할 때 dict형은 정확하게 key 값으로 접근 가능하다는 장점이 있다. 하지만 데이터 크기가 더 증가하거나 동료들과의 코드 공유가 적은 개인 연구를 진행할 때는 list 형태를 활용하는 편이 좋겠다.
