Cluster membership changes
In order to ensure safety, configuration changes must use a two-phase approach. In Raft the cluster first switches to a transitional configuration we call joint consensus; once the joint consensus has been committed, the system then transitions to the new configuration. The joint consensus combines both the old and new configurations:
- Log entries are replicated to all servers in both configurations.
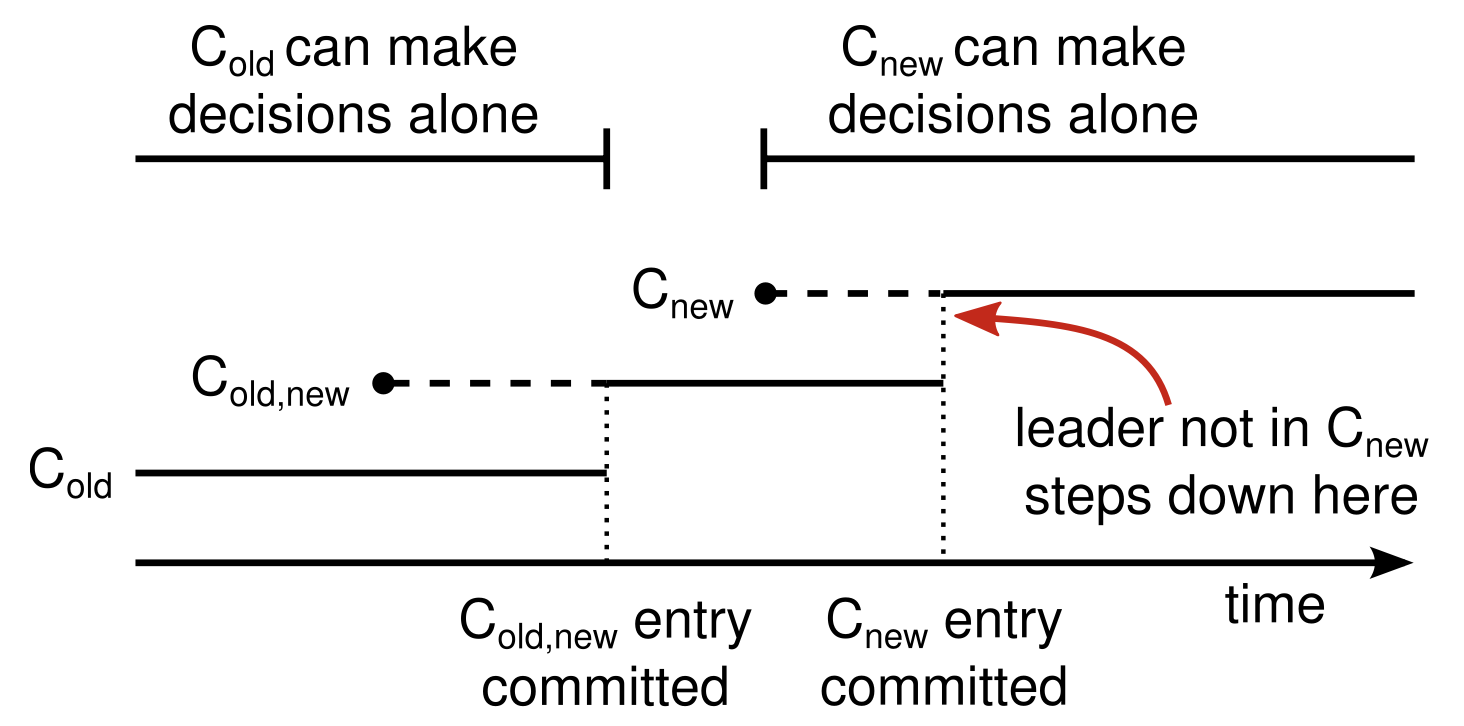
- Dashed lines: Configuration entries that have been created but not committed
- Solid lines: Show the latest committed configuration entry.
The leader first creates the configuration entry in its log and commits it to (a majority of and a majority of ). There is no point in time in which and can both make decisions independently. - Any server from either configuration may serve as leader.
- Agreement(for elections and entry commitment) requires separate majorities from both the old and new configurations. The joint consensus allows individual servers to transition between configurations at different times without compromising safety.
Cluster configurations are stored and communicated using special entries in the replicated log.
- When the leader receives a request to change the configuration from to , it stores the configuration for joint consensus ( in the figure) as a log entry and replicates that entry using the mechanisms described previously.
- Once a given server adds the new configuration entry to its log, it uses that configuration regardless commit for all future decisions. This means that the leader will use the rules of to determine when the log entry for is committed.
- Once has been committed, neither nor can make decisions without approval of the other, and the
Leader Completeness Propertyensures that only servers with the log entry can be elected as leader. It is now safe for the leader to create a log entry describing and replicate it to the cluster. When the new configuration has been committed under the rules of , the old configuration is irrelevant and servers not in the new configuration can be shut down.
Three issues to address for reconfiguration
- New servers may not initially store any log entries. It could take quite a while for them to catch up, during which time it might not be possible to commit new log entries.
- Solution: Additional phase is required before the configuration change, in which the new servers join the cluster as non-voting members (the leader replicates log entries to them, but they are not considered for majorities). If non-voting member catch up with all log entries, then the member will be promoted to a voting member.
- The cluster leader may not be part of the new configuration.
- Solution: The leader steps down (returns to follower state) once it has committed the log entry. This means that there will be a period of time (while it is committing ) when the leader is managing a cluster that does not include itself; it replicates log entries but does not count itself in majorities. The leader transition occurs when is committed because this is the first point when the new configuration can operate independently (it will always be possible to choose a leader from ).
- Removed servers (those not in ) can disrupt the cluster. These servers will not receive heartbeats, so they will time out and start new elections.
- Solution: Servers disregard
RequestVoteRPCs when they believe a current leader exists. Heartbeat Interval is much smaller than Minimum Election Timeout
- Solution: Servers disregard
Log Compaction
As the log grows longer, it occupies more space and takes more time to replay. Snapshotting is the simplest approach to compaction.
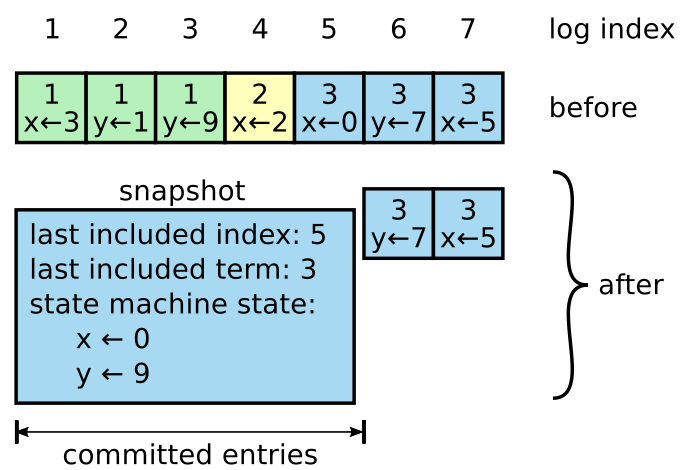
Each server takes snapshots independently, covering just the committed entries in its log.
- last included index: Index of the last entry in the log that the snapshot replaces
- last included term: The term of the last entry in the log that the snapshot replaces. These are preserved to support the
AppendEntriesconsistency check for the first log entry following the snapshot.
When the leader has already discarded the next log entry that it needs to send to a follower due to the compaction, the leader send snapshots to followers that lag behind. Exceptionally slow follower or a new server joining the cluster would lost entry. The way to bring such a follower up-to-date is for the leader to send it a snapshot over the network. The leader uses a new RPC called InstallSnapshot to send snapshots to followers that are too far behind.

If the snapshot contains new information not already in the recipient’s log, the follower discards its entire log.
Disadvantages
- Sending the snapshot to each follower would waste network bandwidth and slow the snapshotting process.
- The leader’s implementation would be more complex. The leader would need to send snapshots to followers in parallel with replicating new log entries to them, so as not to block new client requests.
Issues
- Servers must decide when to snapshot.
- One simple strategy is to take a snapshot when the log reaches a fixed size in bytes.
- Writing a snapshot can take a significant amount of time.
- The solution is to use copy-on-write techniques so that new updates can be accepted without impacting the snapshot being written.
Client interaction
When a client first starts up, it connects to a randomly-chosen server. If the client’s first choice is not the leader, that server will reject the client’s request and supply information about the most recent leader it has heard from (AppendEntries requests include the network address of the leader).
Prevent executing commad multiple times
As described so far Raft can execute a command multiple times: for example, if the leader crashes after committing the log entry but before responding to the client, the client will retry the command with a new leader, causing it to be executed a second time. The solution is for clients to assign unique serial numbers to every command. Then, the state machine tracks the latest serial number processed for each client, along with the associated response. If it receives a command whose serial number has already been executed, it responds immediately without re-executing the request.
Reading stale data
Read-only operations can be handled without writing anything into the log. However, with no additional measures, this would run the risk of returning stale data, since the leader responding to the request might have been superseded by a newer leader of which it is unaware. Raft needs two extra precautions to guarantee this without using the log.
- Leader must have the latest information on which entries are committed.
The Leader Completeness Propertyguarantees that a leader has all committed entries. To find out, it needs to commit an entry from its term. Raft handles this by having each leader commit a blank no-op entry into the log at the start of its term. - Leader must check whether it has been deposed before processing a read-only request (its information may be stale if a more recent leader has been elected). Raft handles this by having the leader exchange heartbeat messages with a majority of the cluster before responding to read-only requests.
