코드잇의 알고리즘의 정석 수업을 수강하고 정리한 글입니다.
정확하지 않거나 빠트린 내용이 있을 수 있기 때문에 강의를 수강하시길 권장합니다.
분할정복을 공부하려면 재귀 개념에 대한 이해가 선행되어야 한다.
1. Divide and Conquer 소개
분할정복이란?
- 문제를 부분문제로 나눈다.
- 부분문제들에 대한 솔루션을 이용해 기존 문제를 해결한다.
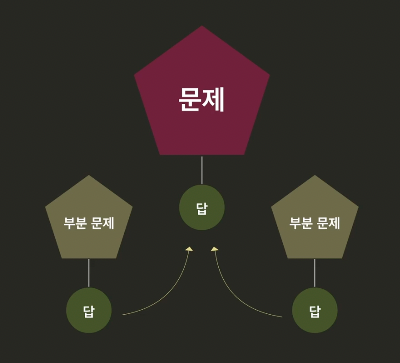
Divide and Conquer의 해결 과정은?
- Divide : 문제를 각 부분 문제로 나눈다. (문제를 , 로 나눈다)
- Conquer: 각 부분 문제를 정복한다. (, 를 정복해서 두 개의 솔루션인 A, B를 도출한다)
- Combine: 부분 문제들의 솔루션을 합쳐서 기존 문제를 해결한다.(두 솔루션 A, B를 이용해서 를 계산한다)
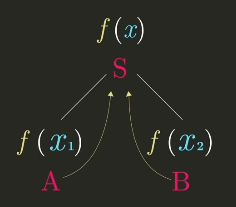
분할 정복이 어려운 이유
문제를 나누고, 정복하고, 합친다. 과정만 보면 간단하다.
하지만 Conquer단계의 동작 방식을 생각해보면 간단하지가 않다.
나눈 문제(, )조차 복잡하다면 또다시 작은 문제로 나누어야 하고 문제가 충분히 작아질 때 까지 divide 단계는 반복될 수 있다.

충분히 문제가 나누어졌다면 문제를 해결하고 합치는 동작을 반복하며 원래의 문제를 해결해야 한다.
내부적으로 복잡해보이는 이 동작이 분할정복을 어렵게 느끼도록 만든다.
그럼에도 꾸준히 연습하다 보면 복잡한 구조는 신경쓰지 않고 Divide, Conquer, Combine 이 세가지에만 집중해서 문제를 해결하게 될 것이다.
문제 - 1부터 n까지의 합
Divide and Conquer를 이용해서 1부터 n까지 더하는 consecutive_sum 함수를 작성하라.
이 함수는 정수 인풋 start와 end를 받고, start부터 end까지의 합을 리턴한다.
end는 start보다 크다고 가정한다.
def consecutive_sum(start, end):
# 코드를 작성하세요
# 테스트
print(consecutive_sum(1, 10))
print(consecutive_sum(1, 100))
print(consecutive_sum(1, 253))
print(consecutive_sum(1, 388))풀이
- 1~100의 합은 1~50의 합과 51~100의 합을 합친 것 과 같다. 이와 같이 문제를 나누도록 (divide) 코드를 구성한다.
- 1~1, 2~2와 같이 같은 숫자가 입력되면 그대로 반환하면 된다. 이를 참고해서 base case를 정의한다. 충분히 문제가 작아졌을 때 솔루션을 반환하는 것. (conquer)
- 해결 된 솔루션을 합쳐서 현재의 문제를 구하는 코드를 작성한다.(combine)
코드
def consecutive_sum(start, end):
if start == end:
return start
# 부분 문제를 반으로 나눠주기 위해 문제의 정중앙을 정의한다. (divide)
mid = (start + end) // 2
# 각 부분 문제를 재귀적으로 풀고(Conquer), 부분 문제의 답을 서로 더한다.(Combine)
return consecutive_sum(start, mid) + consecutive_sum(mid+1, end)
# 테스트
print(consecutive_sum(1, 10))
print(consecutive_sum(1, 100))
print(consecutive_sum(1, 253))
print(consecutive_sum(1, 388))55
5050
32131
754662. 합병 정렬
- 합병 정렬은 Divide and Conquer를 활용한다.
- Divide, Conquer, Combine으로 나누어서 생각해보자.
- Divide: 리스트를 반으로 나눈다.
- Conquer : 왼쪽 리스트와 오른쪽 리스트를 각각 정렬한다.
- Combine: 정렬된 두 리스트를 하나의 정렬된 리스트로 합병한다.
Combined 과정은 어떻게?
Divide, Conquer, Combine으로 나누어서 보면 과정이 단순해 보인다. 하지만 두 리스트를 하나의 리스트로 합치는 Combine과정은 그리 간단하지 않다.
두 리스트를 하나의 정렬된 리스트로 합치는 방법을 생각해보자. 다음과 같이 정렬된 두 리스트가 있다고 가정하자.
list1 = [3, 7, 13, 15]
list2 = [2, 5, 9, 11]
combined = []두 리스트 모두 첫번째 숫자가 가장 작기 때문에 첫번째 숫자를 combined에 넣으면 된다.
- 두 리스트 첫번째 숫자 중 더 작은 숫자를 먼저 combined에 넣는다.
- 남은 값 중 두 리스트의 첫번째 숫자를 비교한다.
- 1, 2를 반복하다보면 list1에만 숫자가 남는다. 남은 숫자를 모두 combined에 넣는다.
# 합병정렬 과정
list1, list2, combined = [3, 7, 13, 15], [2, 5, 9, 11], []
list1, list2, combined = [3, 7, 13, 15], [5, 9, 11], [2]
list1, list2, combined = [7, 13, 15], [5, 9, 11], [2, 3]
list1, list2, combined = [7, 13, 15], [9, 11], [2, 3, 5]
list1, list2, combined = [13, 15], [9, 11], [2, 3, 5, 7]
list1, list2, combined = [13, 15], [11], [2, 3, 5, 7, 9]
list1, list2, combined = [13, 15], [], [2, 3, 5, 7, 9, 11]
list1, list2, combined = [], [], [2, 3, 5, 7, 9, 11, 13, 15]두 정렬된 리스트를 하나의 정렬된 리스트로 합병 → 합병 정렬(Merge Sort)
합병 정렬 진행 과정
[16, 11, 6, 13, 1, 7, 10, 4] → 부분문제1: [16, 11, 6, 13], 부분문제2: [1, 7, 10, 4]
- Divide단계를 수행해서 부분문제로 나누어야 한다. 리스트를 반으로 나눈다.
아래는 부분문제1을 풀어 나가는 과정이다
부분문제1: [16, 11, 6, 13] → 부분문제3: [16, 11], 부분문제4: [6, 13]
- 아직 리스트가 충분히 작지 않기 때문에 Divide를 수행해서 부분문제로 나눈다. 리스트를 반으로 나눠서 부분문제3, 부분문제4로 나눈다.
부분문제3: [16, 11] → 부분문제5: [16], 부분문제6: [11]
- 아직 리스트가 충분히 작지 않기 때문에 Divide를 수행해서 부분문제로 나눈다. 리스트를 반으로 나눠서 부분문제 5, 부분문제 6으로 나눈다.
부분문제5: [16], 부분문제6: [11] → 부분문제5의 솔루션: [16], 부분문제6의 솔루션: [11]
- 부분문제5, 부분문제6은 리스트 요소가 하나밖에 없기 때문에 이미 정렬이 되었다고 볼 수 있다. Conquer단계를 수행한다. 요소가 하나일 때는 그대로 리턴하면 되기 때문에 두 부분문제5, 6(
[16],[11])은 정복되었다.
부분문제5의 솔루션: [16], 부분문제6의 솔루션: [11] → 부분문제3의 솔루션:[11, 16]
- 앞서 Combined 과정에서 설명했던대로 정복한 부분문제5, 6을 합쳐준다. 16보다는 11이 작기 때문에 11, 16순서로 합쳐진다. 이로써 부분문제3을 정복하였다.
부분문제4: [6, 13] → 부분문제7의 솔루션: [6], 부분문제8의 솔루션: [13]
- 아직 리스트가 충분히 작지 않기 때문에 Divide를 수행해서 부분문제로 나눈다. 리스트를 반으로 나눠서 부분문제7, 부분문제8로 나눈다.
부분문제7: [6], 부분문제8: [13] → 부분문제7의 솔루션: [6], 부분문제8의 솔루션: [13]
- 부분문제7, 부분문제8은 리스트 요소가 하나밖에 없기 때문에 이미 정렬이 되었다고 볼 수 있다. Conquer단계를 수행한다. 요소가 하나일 때는 그대로 리턴하면 되기 때문에 두 부분문제7, 8(
[6],[13])은 정복되었다.
부분문제7의 솔루션: [6], 부분문제8의 솔루션: [13] → 부분문제4의 솔루션: [6, 13]
- 앞서 Combined 과정에서 설명했던대로 정복한 부분문제7, 8을 합쳐준다. 13보다는 6이 작기 때문에 6, 13순서로 합쳐진다. 부분문제4를 정복하였다.
부분문제3의 솔루션: [11, 16], 부분문제4의 솔루션: [6, 13] → 부분문제1의 솔루션:[6, 11, 13, 16]
- 앞서 Combined 과정에서 설명했던대로 정복한 부분문제3, 4을 합쳐준다. 작은 수부터 순서대로 combined룰 수행하면 부분문제1이 정복된다.
동일한 순서로 부분문제2를 정복한다. 그리고 해결된 부분문제1의 솔루션과 부분문제의 솔루션에 대해 combined과정을 거치면 원래의 문제가 해결된다.
merge 함수 작성하기
문제
합병 정렬 알고리즘에 사용되는 merge함수를 작성해보자.
merge함수는 정렬된 두 리스트 list1, list2를 받아서, 하나의 정렬된 리스트를 반환한다.
def merge(list1, list2):
# 코드를 작성하세요.
# 테스트
print(merge([1],[]))
print(merge([],[1]))
print(merge([2],[1]))
print(merge([1, 2, 3, 4],[5, 6, 7, 8]))
print(merge([5, 6, 7, 8],[1, 2, 3, 4]))
print(merge([4, 7, 8, 9],[1, 3, 6, 10]))풀이
최종적으로 merge sort를 구현해보기 위해서는 merge함수가 필요하다.
divide 단계를 통해 총분히 두 개의 문제로 나누고 conquer 단계를 통해 정복된 솔루션을 얻었다고 가정하자. 이 두 솔루션을 합치는 단계가 combine단계다.
combine단계를 수행하려면 어떻게 해야할까?
두 부분문제의 솔루션으로 solution1=[1, 2, 3, 4]와 solution2=[5, 6, 7, 8]리스트가 반환되었다면 combine을 결과는 [1, 2, 3, 4, 5, 6, 7, 8]이 되어야 한다.
앞서 combine과정에서 설명했던 것처럼 다음과 같은 순서를 반복하면 된다.
combine 결과를 merged_list라고 하자.
1. solution1, solution2의 첫번째 숫자 중 더 작은 숫자를 먼저 merged_list에 넣는다.
2. 남은 값 중 두 리스트(solution1, solution2)의 첫번째 숫자를 비교한다.
3. 1, 2를 반복하다 한쪽에만 남은 숫자를 모두 combined 뒤에 붙인다.
코드
def merge(list1, list2):
merged_list = []
i, j = 0, 0
# list1, list2의 첫번째 숫자를 비교하며 merged_list에 combined
while (i < len(list1) and j < len(list2)):
if list1[i] < list2[j]:
merged_list.append(list1[i])
i += 1
else:
merged_list.append(list2[j])
j += 1
# list2의 남은 항목을 combined
if i == len(list1):
merged_list += list2[j:]
# list1의 남은 항목을 combined
elif j == len(list2):
merged_list += list1[i:]
return merged_list
# 테스트
print(merge([1],[]))
print(merge([],[1]))
print(merge([2],[1]))
print(merge([1, 2, 3, 4],[5, 6, 7, 8]))
print(merge([5, 6, 7, 8],[1, 2, 3, 4]))
print(merge([4, 7, 8, 9],[1, 3, 6, 10]))합병 정렬 구현하기
문제
Divide and Conquer 방식으로 merge_sort함수를 작성하라. merge_sort는 파라미터로 리스트 하나를 받고, 정렬된 새로운 리스트를 반환한다.
def merge(list1, list2):
merged_list = []
i, j = 0, 0
while (i < len(list1) and j < len(list2)):
if list1[i] < list2[j]:
merged_list.append(list1[i])
i += 1
else:
merged_list.append(list2[j])
j += 1
if i == len(list1):
merged_list += list2[j:]
elif j == len(list2):
merged_list += list1[i:]
return merged_list
# 합병 정렬
def merge_sort(my_list):
# 코드를 입력하세요.
# 테스트
print(merge_sort([1, 3, 5, 7, 9, 11, 13, 11]))
print(merge_sort([28, 13, 9, 30, 1, 48, 5, 7, 15]))
print(merge_sort([2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]))풀이
앞서 combine단계는 구현하였다.
먼저 base case를 작성해본다. 문제가 충분히 작아져서 리스트의 정렬할 숫자가 하나밖에 없다면 어떨까? 그대로 반환하면 된다. base case는 다음과 같다.
if len(my_list) <= 1:
return my_list이 장의 핵심은 divide and conquer다. 말 그대로 복잡한 문제는 분할해서 정복하면 된다.
[16, 11, 6, 13, 1, 7, 10, 4] 문제는 [16, 11, 6, 13]과 [1, 7, 10, 4]문제로 분할할 수 있다.
1. 두 개의 리스트로 나누어서 divide단계를 수행하는 코드를 작성한다.
2. 재귀적으로 함수를 호출해서 conquer를 수행하는 코드를 작성해보자.
3. conquer의 결과는 merge함수를 통해 combine을 수행하자.
코드
def merge(list1, list2):
merged_list = []
i, j = 0, 0
while (i < len(list1) and j < len(list2)):
if list1[i] < list2[j]:
merged_list.append(list1[i])
i += 1
else:
merged_list.append(list2[j])
j += 1
if i == len(list1):
merged_list += list2[j:]
elif j == len(list2):
merged_list += list1[i:]
return merged_list
# 합병 정렬
def merge_sort(my_list):
# base case
if len(my_list) <= 1:
return my_list
mid = len(my_list) // 2 # 부분문제로 나누기 위한 리스트의 중간 인덱스 값
# 부분 문제로 나눈다 (divide) 두개의 merge_sort를 재귀적으로 호출한다. (divide, conquer)
left_half = my_list[:mid])
right_half = my_list[mid:]
# merge_sort를 재귀적으로 호출해서 부분문제를 해결한다.(conquer)
# merge를 통해 각 부분문제의 솔루션을 합친다. (combine)
return merge(merge_sort(left_half), merge_sort(right_half))
# 테스트
print(merge_sort([1, 3, 5, 7, 9, 11, 13, 11]))
print(merge_sort([28, 13, 9, 30, 1, 48, 5, 7, 15]))
print(merge_sort([2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]))
3. 퀵 정렬
- 합병정렬은 divide, conquer는 쉬웠고 주로 Combine단계에서 작업이 수행되었다.
- 퀵정렬은 이와 달리 divide에서 대부분이 수행되고 Conquer, Combine단계에서는 쉽다.
먼저 Divide를 살펴보자
퀵정렬에서 리스트를 나누는 과정을 Partition이라고 한다.
- 리스트에서 피봇(pivot) 즉 기준점을 정한다.
[16, 11, 6, 13, 1, 4, 10, 7]에서 7을 피봇이라고 한다
- 피봇을 기준으로 값을 새롭게 배치한다. 피봇을 기준으로 작은 값은 왼쪽으로, 큰 값은 오른쪽으로 배치한다.
[16, 11, 6, 13, 1, 4, 10, 7]→[6, 1, 4, 7, 11, 16, 10, 13]
Divide and Conquer
- Divide단계에서 피봇을 정하고 작은 값은 왼쪽으로, 큰 값은 오른쪽으로 배치한다.
[16, 11, 6, 13, 1, 4, 10, 7]→[6, 1, 4] [7] [11, 16, 10, 13]
- Conquer단계에서 피봇을 중심으로한 왼쪽과 오른쪽의 리스트를 정렬한다.
[6, 1, 4] [7] [11, 16, 10, 13]->[1, 6, 4] [7] [10, 11, 13, 16]
- Combine단게에서 별다른 작업을 할 필요 없이 좌, 우측의 리스트와 피봇을 합친다.
[1, 6, 4, 7, 10, 11, 13, 16]
Conquer단계에서의 정렬을 보자. [6, 1, 4]와 [11, 16, 10, 13]은 재귀적으로 해결해야 한다. 그리고 재귀적으로 해결한다는 것은 base case가 존재해야 함을 의미한다.
base case는 어떻게 될까? 리스트의 길이가 1일때 그대로 리스트를 반환하면된다.
퀵 정렬에서 가장 어려운 부분
partition 함수 설명
partition함수는 파라미터를 3개 받는다. (my_list, start, end)
- my_list: 파티션 하려는 리스트
- start, end: 파티션 하려는 볌위
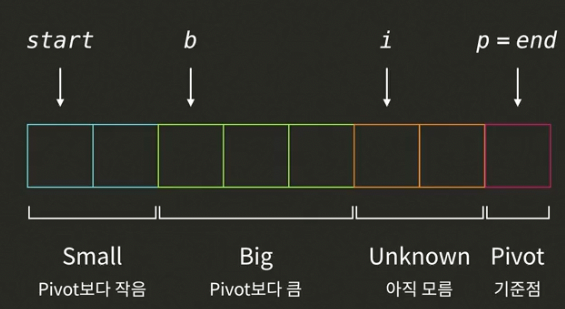
- start: Small그룹 시작 인덱스
- b: Big그룹 시작 인덱스
- i: Unknown 시작 인덱스
partition 수행 과정
[16, 11, 6, 13, 1, 4, 10, 7]의 파티션을 수행하기
-
i가 가리키고 있는 [16, 11, 6, 13, 1, 4, 10, 7]에서 마지막 숫자인 7을 Pivot으로 정한다.
i=0, b=0
-
i가 가리키고 있는 16은 피봇7보다 크므로 인덱스 i를 증가시킨다. (i=1, b=0)
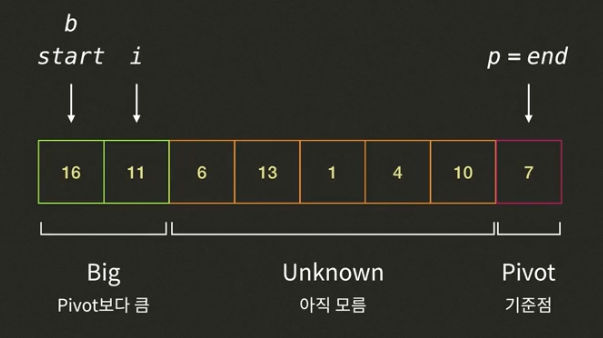
- i가 가리키고 있는 11은 피봇7보다 크므로 인덱스 i를 증가시킨다. (i=2, b=0)
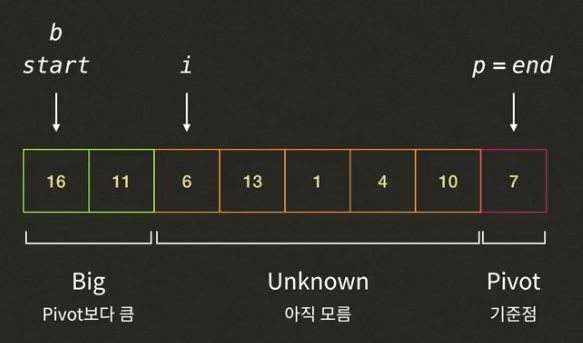
- i가 가리키고 있는 6은 피봇7보다 작으므로 인덱스b의 값(16)과 인덱스 i의 값을 바꾸고, 인덱스b와 인덱스i를 증가시킨다.(i=3, b=1)
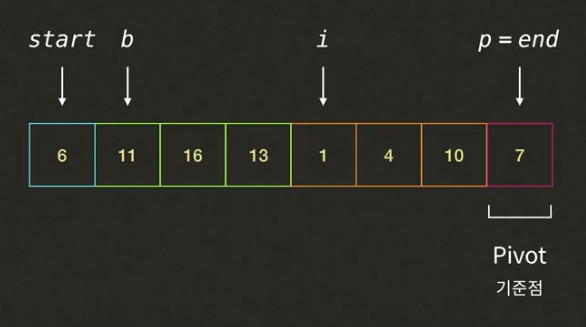
- i가 가리키고 있는 13은 피봇7보다 크므로 인덱스 i를 증가시킨다. (i=4, b=1)
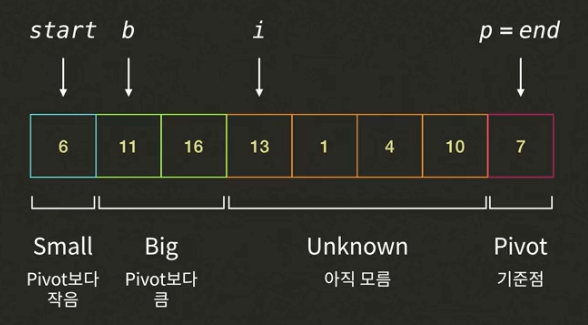
- i가 가리키고 있는 1은 피봇7보다 작으므로 인덱스 b의 값(11)과 인덱스 i의 값(1)을 바꾸고, 인덱스 b와 인덱스 i를 증가시킨다. (i=5, b=2)
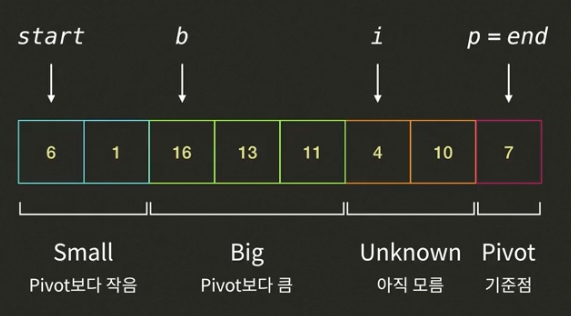
- i가 가리키고 있는 4는 피봇7보다 작으므로 인덱스 b의 값(16)와 인덱스 i의 값(4)을 바꾸고, 인덱스 b와 인덱스 i를 증가시킨다. (i=6, b=3)
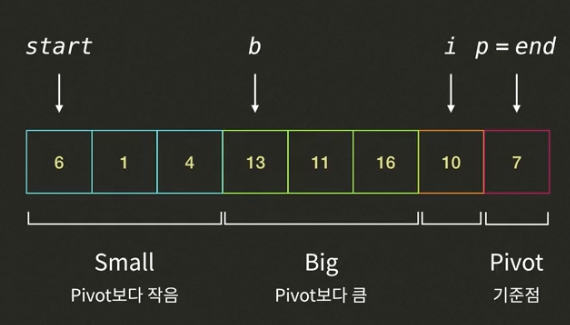
- i가 가리키고있는 10은 피봇7보다 크므로 인덱스i를 증가시킨다.
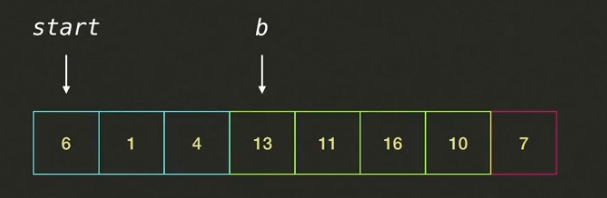
- 결국 i는 피봇까지 도달하였다. b가 가리키는 값과 피봇 값의 위치를 바꾼다.
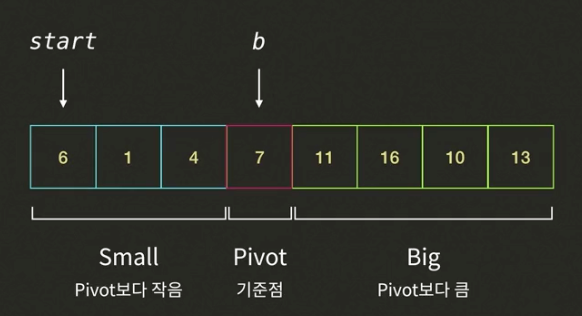
피봇의 좌측에는 피봇보다 작은값이, 우측에는 피봇보다 큰 값이 들어간다. 파티션을 모두 수행하였다.
partition 함수 구현하기
문제
partition 함수 설명 내용을 토대로 partition 함수를 작성하라.
partiton함수는 리스트 my_list, 그리고 partition할 범위를 나타내는 인덱스 start와 인덱스 end를 파라미터로 받는다. my_list의 값들을 pivot기준으로 재배치한 후, pivot의 최종 위치 인덱스를 리턴해야 한다.
# 두 요소의 위치를 바꿔주는 helper function
def swap_elements(my_list, index1, index2):
# 코드를 작성하세요.
# 퀵 정렬에서 사용되는 partition 함수
def partition(my_list, start, end):
# 코드를 작성하세요.
list1 = [4, 3, 6, 2, 7, 1, 5]
pivot_index1 = partition(list1, 0, len(list1) - 1)
print(list1) # [4, 3, 2, 1, 5, 6, 7]
print(pivot_index1) # 4# 콘솔 출력
[4, 3, 2, 1, 5, 6, 7]
4
[1, 2, 3, 4, 6, 5, 6]
3풀이
partition함수 설명을 참고하여 풀이한다.
코드
# 두 요소의 위치를 바꿔주는 helper function
def swap_elements(my_list, index1, index2):
my_list[index1], my_list[index2] = my_list[index2], my_list[index1]
# 퀵 정렬에서 사용되는 partition 함수
def partition(my_list, start, end):
i, b, p = 0, 0, len(my_list)-1
while i < p:
if my_list[i] < my_list[p]: # 현재 인덱스의 값이 피봇의 값보다 작으면 수행
swap_elements(my_list, i, b) #
b += 1
i += 1
swap_elements(my_list, p, b)
p = b
return p
# 테스트 1
list1 = [4, 3, 6, 2, 7, 1, 5]
pivot_index1 = partition(list1, 0, len(list1) - 1)
print(list1)
print(pivot_index1)
# 테스트 2
list2 = [6, 1, 2, 6, 3, 5, 4]
pivot_index2 = partition(list2, 0, len(list2) - 1)
print(list2)
print(pivot_index2)# 콘솔 출력
[4, 3, 2, 1, 5, 6, 7]
4
[1, 2, 3, 4, 6, 5, 6]
3퀵 정렬 구현하기
문제
Divide and Conquer 방식으로 quicksort 함수를 작성하라. quicksort는 파라미터로 리스트 하나와 리스트 내에서 정렬시킬 범위를 나타내는 인덱스 start와 인덱스 end를 받는다.
merge_sort와 달리 quicksort함수는 정렬된 새로운 리스트를 리턴하는게 아닌 파라미터로 받는 리스트 자체를 정렬시킨다.
swap_elements와 partition함수 이전과 동일하게 사용하라.
# 두 요소의 위치를 바꿔주는 helper function
def swap_elements(my_list, index1, index2):
# 이전 과제에서 작성한 코드를 붙여 넣으세요!
# 퀵 정렬에서 사용되는 partition 함수
def partition(my_list, start, end):
# 이전 과제에서 작성한 코드를 붙여 넣으세요!
# 퀵 정렬
def quicksort(my_list, start, end):
# 코드를 작성하세요.
# 테스트 1
list1 = [1, 3, 5, 7, 9, 11, 13, 11]
quicksort(list1, 0, len(list1) - 1)
print(list1)
# 테스트 2
list2 = [28, 13, 9, 30, 1, 48, 5, 7, 15]
quicksort(list2, 0, len(list2) - 1)
print(list2)
# 테스트 3
list3 = [2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]
quicksort(list3, 0, len(list3) - 1)
print(list3)# 콘솔 출력
[1, 3, 5, 7, 9, 11, 11, 13]
[1, 5, 7, 9, 13, 15, 28, 30, 48]
[1, 1, 2, 2, 4, 4, 4, 5, 6, 6, 7, 7, 10, 11, 13, 15]풀이
Divide단계: 피봇을 기준으로 부분문제를 나눈다.
Conquer: 부분문제를 재귀적으로 해결한다. Conquer는 저절로 수행되지 않는다. base case를 먼저 생각해보고 앞서 구현한 파티션 과정을 수행해야한다.
Combine: 수행하지 않아도 된다.
코드
# 두 요소의 위치를 바꿔주는 helper function
def swap_elements(my_list, index1, index2):
my_list[index1], my_list[index2] = my_list[index2], my_list[index1]
# 퀵 정렬에서 사용되는 partition 함수
def partition(my_list, start, end):
i, b, p = start, start, end
while i < p:
if my_list[i] < my_list[p]: # 현재 인덱스의 값이 피봇의 값보다 작으면 수행
swap_elements(my_list, i, b) #
b += 1
i += 1
swap_elements(my_list, p, b)
p = b
return p
# 퀵 정렬
def quicksort(my_list, start, end):
# base case
if start >= end:
return
pivot = partition(my_list, start, end)
# Divide: pivot을 기준으로 리스트를 나눈다.
# Conquer: pivot 왼쪽과 pivot 오른쪽을 quicksort로 정렬한다.
quicksort(my_list, start, pivot-1)
quicksort(my_list, pivot+1, end)
# 테스트 1
list1 = [1, 3, 5, 7, 9, 11, 13, 11]
quicksort(list1, 0, len(list1) - 1)
print(list1)
# 테스트 2
list2 = [28, 13, 9, 30, 1, 48, 5, 7, 15]
quicksort(list2, 0, len(list2) - 1)
print(list2)
# 테스트 3
list3 = [2, 5, 6, 7, 1, 2, 4, 7, 10, 11, 4, 15, 13, 1, 6, 4]
quicksort(list3, 0, len(list3) - 1)
print(list3)# 콘솔 출력
[1, 3, 5, 7, 9, 11, 11, 13]
[1, 5, 7, 9, 13, 15, 28, 30, 48]
[1, 1, 2, 2, 4, 4, 4, 5, 6, 6, 7, 7, 10, 11, 13, 15]